🎙 Krishna Gade/CEO Fiddler AI: Challenges with model explainability
TheSequence interviews ML practitioners to merge you into the real world of machine learning and artificial intelligence
There is nothing more inspiring than to learn from practitioners. Getting to know the experience gained by researchers, engineers and entrepreneurs doing real ML work can become a great source of insights and inspiration. We’d like to introduce to you TheSequence Chat – the interviews that bring you closer to real ML practitioners. Please share these interviews if you find them enriching. No subscription is needed.
👤 Quick bio / Krishna Gade
Tell us a bit about yourself. Your background, current role and how did you get started in machine learning?
Krishna Gade (KG): I am the Founder/CEO of Fiddler, an Explainable AI (XAI) Platform. Prior to founding Fiddler, I led engineering teams at Facebook, Pinterest, Twitter, and Microsoft.
For most of the last two decades, I spent time building scalable platforms at these internet companies to convert data into intelligent insights using big data, machine learning, and deep learning technologies. At Facebook, I was leading the News Feed Ranking Platform that created the infrastructure for ranking content in News Feed and powered use-cases like Facebook Stories and recommendations like People You May Know, Groups You Should Join, etc. My team built Facebook’s explainability features like ‘Why am I seeing this?’ which helped bring much-needed algorithmic transparency and thereby accountability to the News Feed for both internal and external users.

🔍 Research
You are currently focused on one of the toughest areas of modern machine learning. Can you describe the challenges with model explainability and monitoring?
KG: Machine learning is being increasingly applied by enterprises across a variety of use-cases, but AI is not the easiest technology to build and operationalize. However, the past few years have seen the emergence of GUI-based ML tools and open-source libraries to help enterprises, less inclined to build in-house, successfully train and deploy ML models. Training highly accurate ML models has become relatively fast and cheap now. But deploying, monitoring, governing, and ensuring responsible use of them over time – that’s become the main challenge.
Data Science and Engineering teams have come to realize they must then monitor and manage their models to ensure risk-free and reliable business outcomes. With the rise of higher-performing black-box models, the need to explain models has become both more necessary and more challenging. ML models are essentially stochastic entities and their performance can degrade over time due to changes in input data distribution, seasonality, or some unexpected events like COVID-19. Therefore models require continuous monitoring to ensure their fidelity while in production. An Explainable ML Monitoring system extends traditional monitoring to provide deep model insights with actionable steps.
A classic challenge in machine learning interpretability is the difference between simple models like decision trees and complex neural networks. How does Fiddler manage to provide a single platform for explainability across such different sets of architectures?
KG: Great question!
At Fiddler, we chose a particular family of techniques that rely on attribution based methods to explain ML models. These algorithms attribute a given model’s prediction to input features, relative to a certain baseline input. For example, we can attribute a lending model’s prediction to its features like FICO, Income, Previous Debt, etc, we can also attribute an object recognition network’s prediction to its pixels, as well as attribute a text sentiment network’s prediction to individual words. This is a reductive formulation of answering the question of “why this prediction” but it is surprisingly effective :)
Oftentimes, the features used in an ML model are not independent so the task of attributing the impact of each feature on the model's final prediction is non-trivial. Therefore, we leverage the well established Shapley Value concept from the cooperative game theory proposed by Lloyd Shapley in 1953. We’ve found that our novel and scalable implementation (here is a research paper about it) performs well across different model types and scales for large production datasets.
🔺 TheSequence Edge is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. Stay up to date with the news, trends, and tech developments in the AI field. Practical. No hype. 🔻
Is machine learning explainability a feature or a product? Can explainability platforms remain standalone companies of eventually will be merged into the larger machine learning stacks from companies like Microsoft, Google or AWS?
KG: Sure, as teams are building more and more sophisticated AI applications, they recognize a single monolithic AI platform is not working for them after a point. They are looking for a machine learning workflow with best-of-breed tools.
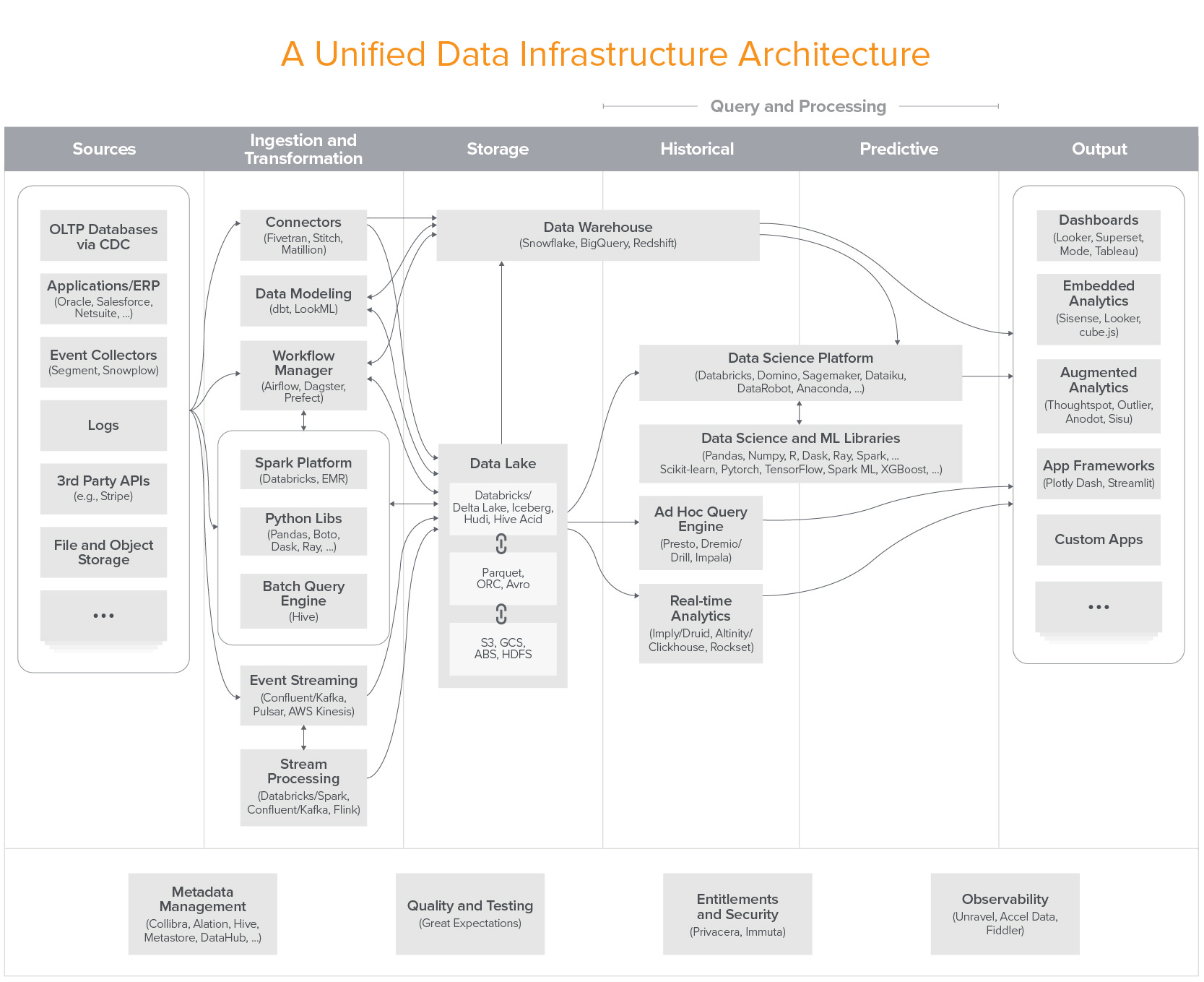
Image credit: a16z.com
{kind=link}
We’ve built a pluggable platform that allows our customers to integrate Fiddler with their favorite model types like Scikit-Learn, TensorFlow, PyTorch, MLFlow, Spark, etc, and seamlessly Monitor, Explain and Analyze their AI in production.
We’ve seen this being successful in the traditional software development lifecycle, where developers use a myriad of tools (e.g, LAMP stack) to build, deploy, and monitor their applications. Machine learning development lifecycle is also going through the same evolutionary process where AI developer’s toolkit is literally being built right now by a handful of exciting startups like Fiddler! Given that businesses, consumers, and regulators are calling for more transparency and accountability in AI solutions, XAI platforms like Fiddler can provide more trustworthy, transparent, and accountable AI by plugging into every stage of the AI lifecycle.
What are some of your most ambitious ideas about machine learning explainability? Can we get to the point of using machine learning to explain the behavior of other machine learning models?
KG: Since I came from a software engineering background, I will use an analogy from there to illustrate my point. When we root-cause software failures in production teams, we use a “Five Whys” method to perform the diagnosis. One can extend that to Model Explainability. Say, for example, a credit risk ML model denies a loan application. We can ask a series of questions like below to know the truth.
Why did the credit risk model deny the loan application?
Why was the credit risk score so high for this loan?
What are the most influential factors that affected the credit risk score?
What are other loans that got rejected that are similar to this loan application?
Would the model approve the loan if the user requested a $1000 lesser amount?
What can the loan applicant do to improve their case for getting approved in the future?
...
As we answer one question, we get 10 other questions in our mind that we want to know the answers to. Therefore fully explaining a complex ML model becomes a holy-grail. The goal of any XAI tool is to get the user as close to the truth as possible.
We recognize that the XAI space is evolving quickly and lots of new algorithms are being invented, so we've taken the pragmatic approach of focusing our offering around tools and high-quality implementations of methods that have largely proven their usefulness in deployed AI applications. As space evolves, we are committed to improving our existing offering as well as adding new methods and techniques to meet our users' needs.
The ethos of the machine learning community is tightly aligned with the spirit of open-source. Why is Fiddler not open-source in a market with several open-source machine learning interpretability stacks?
KG: At Fiddler, we’ve productized several open-source XAI algorithms such as SHAP, Integrated Gradients along with our propriety techniques. We’ve published papers on our proprietary techniques as well as creating video tutorials that deep-dive into how they work. We’re committed to publishing our research as we believe in creating transparency around how our algorithms work for our users who are data scientists, ML engineers, analysts, and regulators.
What OSS stacks, like Microsoft Interpret or IBM XAI toolkit, provide is a collection of libraries. Developers still have to do all the heavy lifting to operationalize them. Whereas the value Fiddler provides to our users is that all of these algorithms (including some of our proprietary ones) are packaged in a scalable and operationalized XAI platform that helps them monitor and explain complex models and large datasets.
💥 Miscellaneous – a set of rapid-fire questions
TensorFlow or PyTorch?
KG: PyTorch if I am mostly prototyping, but Tensorflow for production models. Btw, check out this talk by Facebook and Fiddler partnering to explain PyTorch models.
Favorite math paradox?
KG: Simpson’s paradox. It is a fascinating paradox because it shows that data can both guide and deceive us at the same time :)
Any book you would recommend to aspiring data scientists?
KG: There are many popular books that have come into the field over time. For someone new to the field, aspiring for a rigorous text – I would recommend the Pattern Classification book by Duda, Hart, and Stork. I am also a big fan of “The Book of Why” by Judea Pearl, especially the first chapter is super insightful.
Is P equals NP?
KG: Hmm… If P equals NP, every NP problem would contain a hidden method, allowing computers to quickly find perfect solutions to them. But if P does not equal NP, then no such shortcuts exist, and computers’ problem-solving powers will remain fundamentally and permanently limited. We can make a philosophical argument that P just can’t equal NP. If it did, then it would mean that finding the solution to a problem has always been as easy as verifying that the solution is correct and that factoring our large numbers is easy.
We should be happy that P does not equal NP because that would have broken all internet security and all our identities and credit histories would have been stolen by now :)
TheSequence’s goal is to make you smarter about artificial intelligence. 5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space. Subscribe to receive it straight into your inbox. Support the project and our mission to simplify AI education, one newsletter at a time. Thank you.