
🏷 Edge#138: Toloka App Services Aims to Make Data Labeling Easier for AI Startups
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. On Thursdays, we do deep dives into one of the freshest research papers or technology frameworks that is worth your attention.
💥 What’s New in AI: Toloka App Services for AI Startups
For developing better AI models, one needs a vast amount of labeled data. Acquiring raw (unlabeled) data is relatively simple in this era of information technology, but labeling large volumes of unstructured data is a highly labor-intensive job. Thus, the majority of the time invested in an AI project is allotted to data-centric operations.

The success of supervised learning algorithms depends extensively on the amount and quality of labeled data. The data labels help guide the ML model in the right direction such that it can classify unseen samples accurately. The entire data annotation process involves a lot of steps, like tagging, classification, and processing. For example, suppose in a task to aid autonomous driving, a single image captured may contain several objects like people, other vehicles, pavements, crosswalks, traffic lights, etc., which needs to be identified separately. Furthermore, the annotation quality needs to be high; otherwise, faulty data labels will amplify the adverse effects in the ML model training. As data labeling methods keep being increasingly important to the success of machine learning (ML) solutions, we continue to cover some of the interesting platforms in the space. In Edge#107, which was about Crowdsourced vs. Automated vs. Hybrid Data Labeling, we’ve briefly covered Toloka, a crowdsourced data labeling platform that was initially started to fit the needs in large-scale industrial ML pipelines. Today, we want to overview their new service tailored for startups and teams in the early stage of their AI production – Toloka App Services. Let’s dive in.
Data Labeling: The challenges for a novice
There are different ways to attack a data-labeling problem: crowdsourced, automated, or hybrid. The obvious tradeoff is between the scale and systematicity of automated approaches and the accuracy and simplicity of crowdsourced models. Toloka App Services is one of the solutions capitalizing on crowdsourced/hybrid data labeling methods.
A general workflow for generating high-quality labeled ML datasets using a crowdsourced approach requires the following steps:
Decomposition: Divide your project into multiple steps until each step is clear enough for any labeler to complete
Instructions: Clear and concise instructions increase the accuracy of the final results
Interfaces: A good interface makes it easy for users to perform repeated actions quickly and correctly
Quality control: Carefully plan and configure a quality control system to ensure high-quality results
Pricing: Establish the optimal price based on speed and quality requirements
Results: After the pool finishes, aggregate the results and check statistics
Project Maintenance: Supervise the entire operation and ensure that the process meets proposed timelines
After all these steps, there are two main requirements of data labeling that have to be fulfilled:
-Accuracy: This measures how close the data labels are to the ground truth, i.e., checking the consistency in the predictions of an ML algorithm concerning the real world. Accuracy in data labeling is vital for the success of Computer Vision and Natural Language Processing tasks.
-Quality: This is the measure of the accuracy of the entire dataset generated. Here you need to check whether the labels tagged by different data labelers reach a consensus to ensure consistency and accuracy of the datasets.
Toloka App Services
All the above might sound like a daunting task for a team that just started their AI journey and doesn’t want to put a lot of effort into training their first models. Toloka App Services tries to make it less of a headache by taking five out of these seven steps off your plate. First, you need to divide your project into smaller steps (Point 1) and provide instructions to the data labelers (Point 2) Toloka Apps will take care of the actual data labeling operation, allowing you to focus on the analysis and deliver high-quality insights. The solution for engineers provides all the necessary components: the pre-set interfaces, tools for balancing speed/quality ratio, the global crowd, optimal matching of tasks and performers, full range of automated quality control methods, dynamic pricing, and a free API to integrate it into the ML production pipeline.
How it works
Toloka includes three important components that together help ensure data labeling quality: expert benchmark, crowd input, automation.
Expert benchmark: Toloka provides in-house expert labelers who help set a benchmark and create comprehensive guidelines for the consistency of labels. Toloka claims results in a 40% lower error rate than the available managed service solutions in the market.
Crowd input: While testing your data, humans should be part of the process for providing ground truth monitoring. Using Humans-in-the-loop (HITL), Toloka lets you check whether your ML model provides the intended prediction and helps you identify gaps in the train data, and give feedback to the model. HITL further allows retraining of the model if the prediction is incorrect or the confidence is below the set threshold.
In Toloka, a managed crowd force provides the majority of labels. With millions of crowd performers available across every time zone, Toloka’s algorithms select performers that are best suited for the target task, and the accuracy is monitored thoroughly. It helps dramatically reduce the data labeling project time from several days to just minutes.
Automation: Toloka employs auto-labeling solutions to increase the size of the training set, or the quality of labels (by adding an extra vote to each judgment), or the speed of labeling.
What is also nice about Toloka Apps is its user-friendly interface that allows you to kickstart your data labeling project without ML expertise. The solution includes pre-set data labeling pipelines available for real industries’ data labeling use cases. For the quality check, Toloka Apps employs pre-trained models and custom-built algorithms that are guaranteed to provide the best quality labels in record time. We also like that you do not need to create and maintain control tasks, set up, and experiment with quality control rules. A fully functional quality control setup is already in place.
Versatility
Toloka Apps enables a consistent interface for labeling highly diverse types of datasets:
Images: Labelling tasks for semantic segmentation, image classification, object recognition, image transcription, side-by-side comparison, moderation, creating collections.
Videos: Classification, moderation, collections
Text: Search relevance, Text Classification, Sentiment Analysis, Intent Classification, Utterance Collection, Named Entity Recognition
Audio: Audio Data Collection, Audio Transcription, Audio Classification
Data Enrichment: Business Data, Surveys, Content Generation
Field Data Collection: Offline data collection, Price monitoring, Merchandising, Secret buyer, Foot traffic, Advertisement monitoring
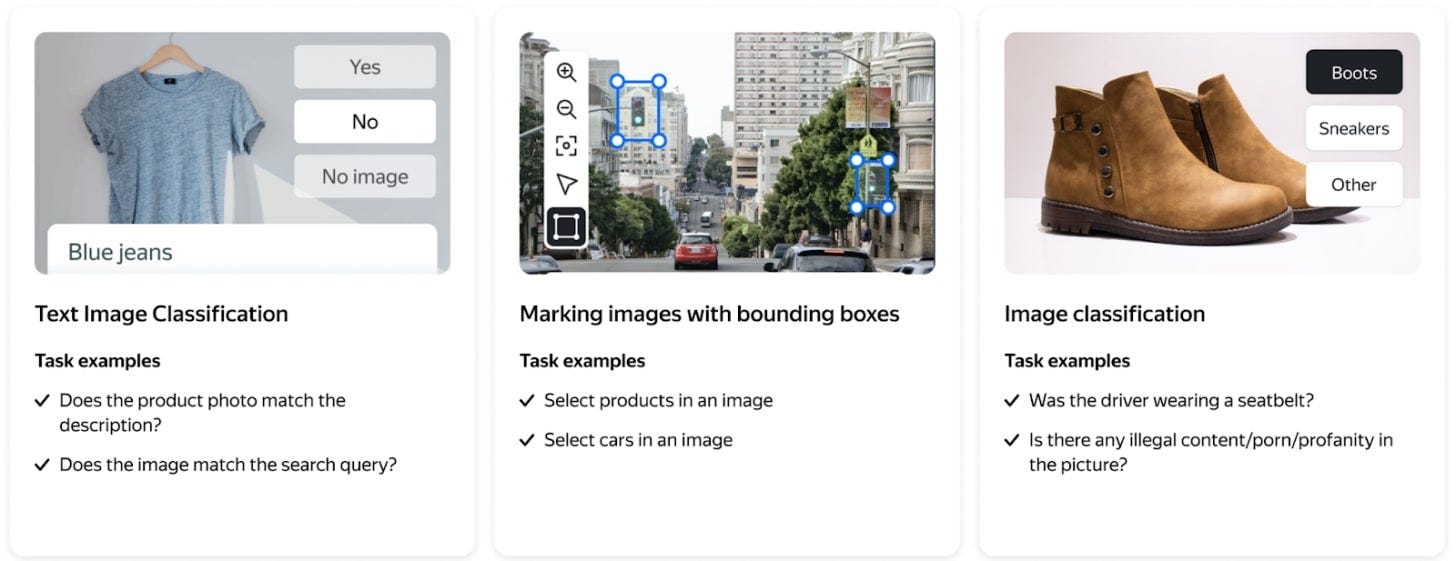
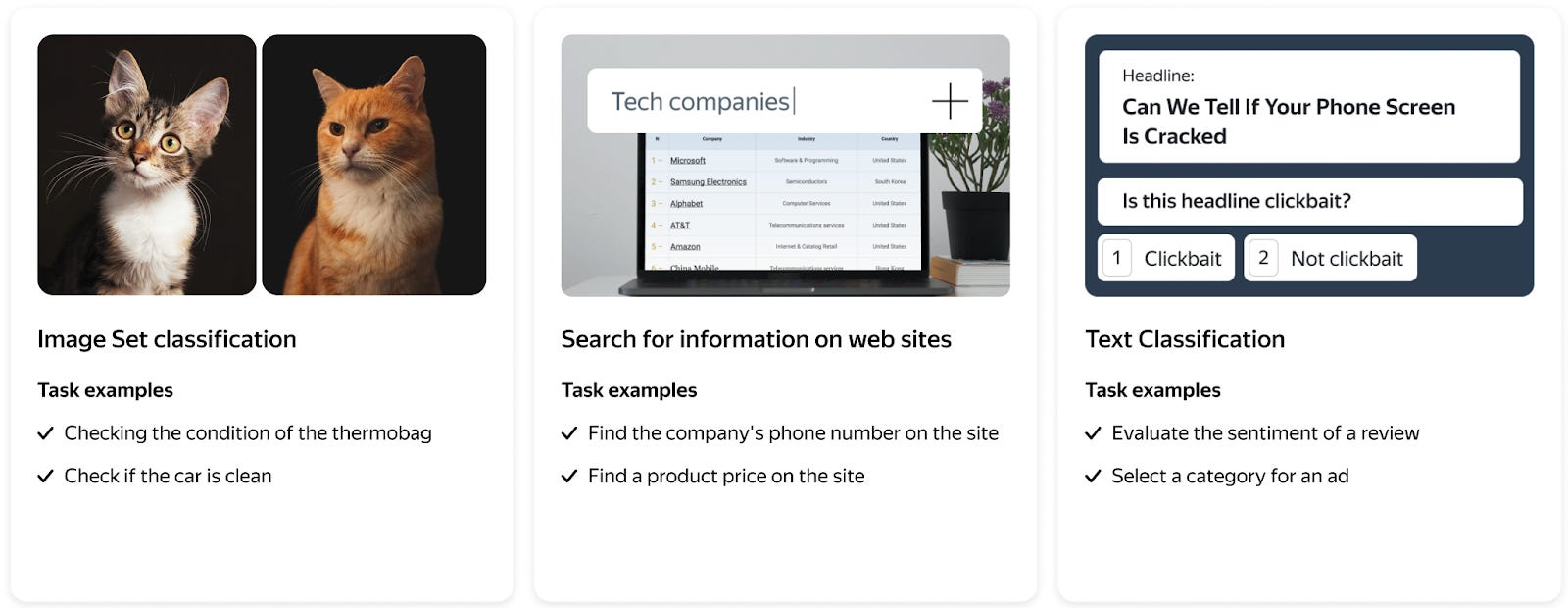


Conclusion:
Data labeling is a time-consuming but essential part of any ML project. Any ML solution is only as good as the data that is used to train it. Toloka App Services is one of the emerging data labeling solutions in the market that offers a flexible and scalable data labeling service for a wide range of tasks. Toloka assures the quality of the data labels while also being cost-effective. The pre-set options for startups and high flexibility and customization to play with make Toloka App Services one of the most helpful tools on the market.