


🎙 Joe Doliner/CEO of Pachyderm on developing a canonical ML stack and main challenges for mainstream developer adoption
It’s so inspiring to learn from practitioners. Getting to know the experience gained by researchers, engineers, and entrepreneurs doing real ML work is a great source of insight and inspiration. Please share this interview if you find it enriching. No subscription is needed.
You can also leave a comment or ask a question in the comment section below.

👤 Quick bio / Joe Doliner
Tell us a bit about yourself. Your background, current role and how did you get started in machine learning?
Joe Doliner (JD): I’m the co-founder and CEO of Pachyderm, which provides open-source solutions to help machine learning teams tackle their biggest data management challenges. Previously, I was a software engineer for Airbnb as part of their data science infrastructure team and prior to that was the first engineer at RethinkDB. Consider myself to be an open-source aficionado to the core.
🛠 ML Work
Part of Pachyderm vision is to develop a “canonical stack” for ML solutions. What are the key building blocks or categories of a canonical ML stack? What could be a balance to determine when to use a single-stack versus best-of-breed solutions?
JD: Pachyderm is one of the founding members of the AIIA1, the AI Infrastructure Alliance, which goal is to create a canonical stack for ML meaning a standard toolset that everyone uses as a first choice to design and create AI apps. We started it because we feel that to create a truly end-to-end ML platform, you need a collection of tools that work together seamlessly.
Think of canonical stack as a LAMP stack for AI. The LAMP stack created an explosion of apps on the web, most notably WordPress, which became one of the most powerful and flexible web hosting frameworks in the world. Without the LAMP stack, developers can’t move up the stack to build amazing applications. They need a powerful foundation to build on.
Right now, AI is mostly done at the big tech companies because they have the power to invest $500 million to roll their own software and the engineers to do it, with money left over to hire the top data scientists and researchers on the planet.
Enterprises and smaller companies aren't going to build their own stacks from the ground up. For AI apps to become as ubiquitous as the apps on your phone, you need a canonical stack that makes it easier for non-tech companies to build AI apps without having to roll their own infrastructure.
The graphic below shows a complete end-to-end stack for ML that works for almost every known use case in ML today. It’s not a series of boxes that a logo fits cleanly into, but a stack where one company’s solution flows across multiple boxes.
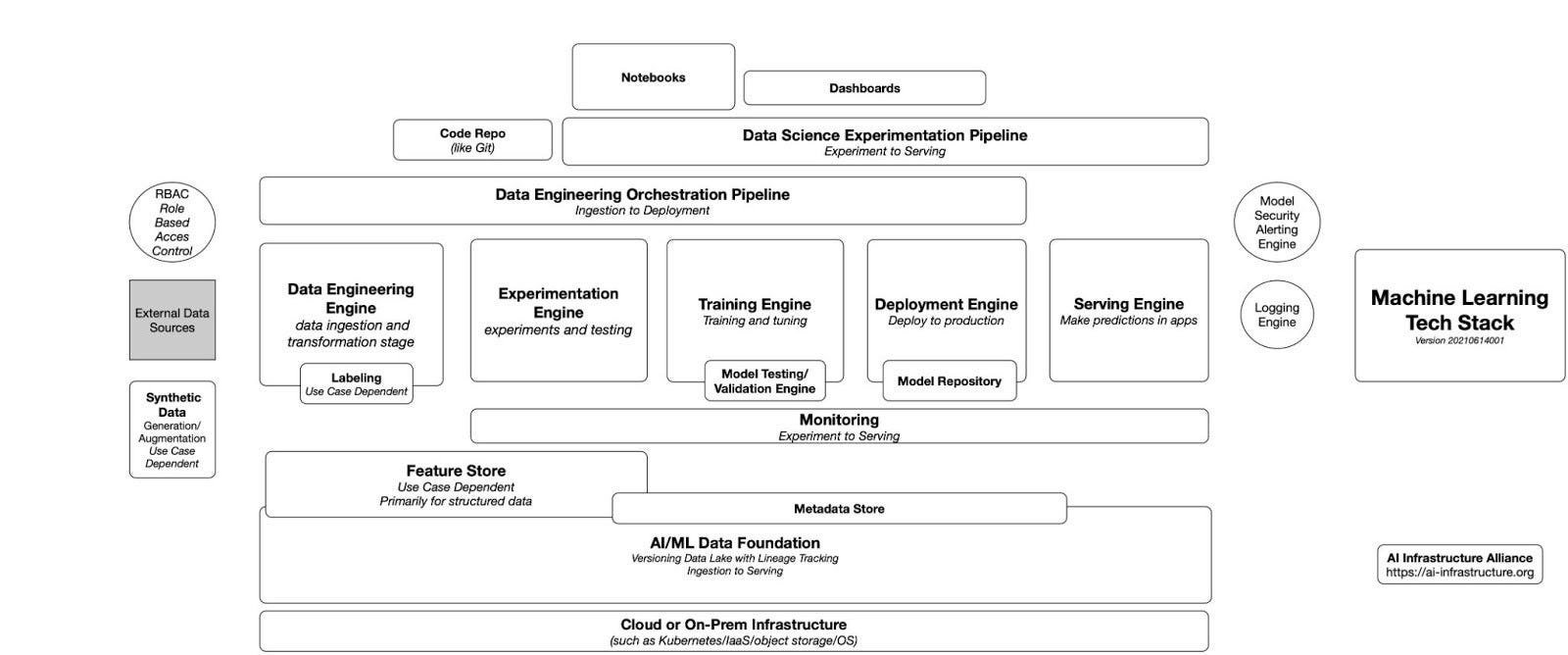
Check out the color-coded version of the diagram below to see where Pachyderm fits in:
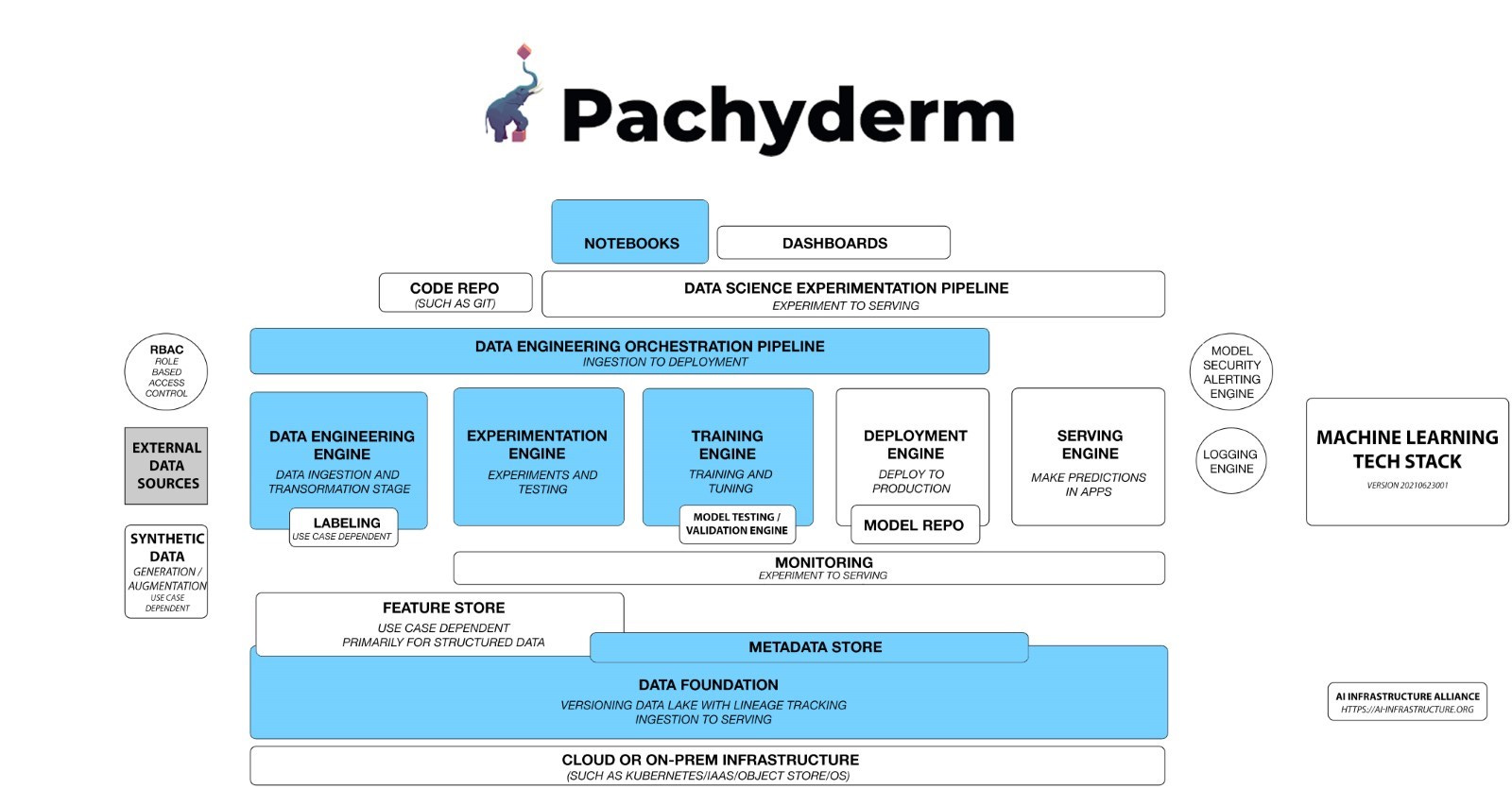
You can think of Pachyderm as a massive data lake with versioning and lineage, as well as a framework-agnostic pipeline that’s data-driven.
Data-driven means new data or changes in the data can automatically kick off pipelines steps without you having to write a whole loop to check for changes to data constantly or handle errors that arise while doing so.
Because our pipeline system understands data versions and diffs, as new data is added to the system, it can easily kick-off incremental processing of that data in the pipeline, processing only the changed data instead of everything from scratch again. That means you don’t have to retrain on 200 terabytes of data because 10 GB just flowed into the system. We can train forward, keeping all the old weights of the model.
We’re often just lumped in as “data versioning” but it’s so much more than that.
Our pipelining system can run any framework you can put in a container. While most pipelines can only run Python and maybe one other language, Pachyderm can run Python, R, C++, Java, Rust, Scala, Go, Bash and anything else you can stuff in a container. If you want to run TensorFlow and PyTorch in different stages and then two versions of Anaconda and that library you just found from Stanford to do some cutting-edge NLP, you can do it all.
The number of ML frameworks and platforms entering the market is overwhelming. Is the ML space too fragmented for being such an early-stage trend? In your opinion, what are categories that are here to stay and which ones are likely to become a feature of larger platforms?
JD: We expect to see consolidation around the key steps in the ML lifecycle, as they get more and more widely adopted. The software will expand from its original purpose to cover more and more of the lifecycle.
At its most basic, the ML lifecycle takes machine learning applications from idea to production. There can be some variance depending on the use case, but it typically boils down to the same major steps:
The collection, preparation, and labeling of data.
Experiments and exploration to determine the data and algorithms required for successful models.
Training and evaluation to determine if the selected models are successful for their applications.
Deployment to production and monitoring.
These aren’t linear steps executed one by one. They are incredibly iterative as more of a living, breathing system that needs to be developed and built out over time. Think of them as an ML loop. Mastering and scaling these processes are how teams mature their machine learning practices.

Over time it’s only natural for companies to build on their strength and deliver a more comprehensive solution to each stage of the lifecycle. This type of Cambrian explosion is typical of any early market. Before Ford came to dominate car-making with interchangeable parts, there were almost 100 different bespoke car companies.
We see a number of areas that are likely to just fold into a larger solution. A “metadata store” appears in everyone’s stack but what is a metadata store? It’s really just a database. We don’t see much of a need for an external database that stores all the stages of a pipeline and what happens in that pipeline.
Pachyderm has a “metadata store” that stores all the information about the code, the models and the data as their all changing simultaneously. When we talk about data in this context, we don't just mean raw data. We mean all the intermediary data artifacts that are produced throughout this process – cleaned dataset, labeled data and annotations, model features, model artifacts, evaluations metrics, metadata – it’s all just data and it needs to be developed and managed and versioned and tracked and iterated on. Every product out there today has some kind of built-in database and we don’t see any reason it’s likely to become a separate product.
Lastly, everyone today has their own pipelining system and that won’t last. We’ll end up standardizing on a few ways to do data engineering-focused pipelines and data science-focused pipelines. We expect those types of pipelines to be agnostic in the way that Pachyderm’s pipeline is agnostic. Any pipeline that requires the development team to support every language or framework is unscalable in the long run, in the same way, that Yahoo couldn’t have people go look at every website once the web really started to grow.
One of the areas in which Pachyderm excels is data lineage and versioning. What makes this such an important component of ML solutions and what techniques can be used to address this challenge?
JD: As Andrew Ng says “data is food for AI.”
In hand-coded logic the data is secondary. When a programmer designs hand-coded logic, they write all the rules and only touch the data briefly. If you write a website login script, you only touch the data once to get a username and password.
But with machine learning, the models learn the rules from the data.
Data is primary.
In a recent talk, Ng noted that most data scientists spend a lot of time tweaking the models and the hyperparameters of those models for very little result. They might get a 0.2% increase in accuracy playing around with the model. But something altogether different happens when they go back and tweak the data.
They might have 10 people doing labeling and they all interpreted their instructions of how to draw the bounding box a little differently. Going back and refining those instructions and telling them to re-label 30% of the images jumps performance up 20%. That’s a major difference.
Your data is the hidden part of the iceberg. We’ve got a lot of tools to deal with the part above the water but very few tools that deal with the data effectively and that’s a major problem because data is the lifeblood of ML.

As teams get bigger and bigger, you’re going to need to keep track of shifting datasets for compliance purposes and to find which exact dataset trained a model. If you need to go back in time and find out why a model is exhibiting bias after new data got added, you need to be able to roll back to that exact point in time where you started training on the newly added data.
In a big data science team, different teams may need totally different versions of the data, formatted or changed in various ways to the model they’re building. Eventually keeping track of all those changes without a lineage system is impossible. Every model becomes a one-off that you can’t recreate. That very quickly becomes a nightmare as models need to get updated and you need an unaltered version of the dataset to start retraining. Without that, your model will learn different rules.
It’s not just lineage either. You need an immutable filesystem too. Immutability is not optional.
Without it, you can’t guarantee that the data didn’t change out from under you, which makes your experiment non-reproducible. If one data scientist distorts the original dataset, overwriting it with a new column in the text, or a different file size, or a different filter on the video, it irrevocably changes the output of the model.
Pachyderm couples lineage with a powerful copy-on-write filesystem that sits atop an object store, like Amazon S3. That keeps the data small as you get infinite snaps of that data automatically every time a change is made. Other systems make copies of the data over and over but that won’t scale. If you have multiple 1 GB video files and you throw a filter on it that changes 5 MB, why are you making a copy of the whole 1 GB again?
Another area of focus of your work is CI/CD which I find super tricky when comes to ML pipelines. What are the key CI/CD differences between traditional software and ML workflows?
JD: The key difference with machine learning CI/CD is you have to keep track of the data, the models, and the code as they are all changing at the same time.
The orchestration engine needs to control all of them together, so they can keep track of how they all interrelate and interact with each other at any point in time.
Most of the CI/CD systems today were built to just deal with the code. The data was secondary. It was handled by another system. But with ML you need to keep track of the data state as well as the model and the code.
Those three states may diverge all at once or one at a time. Your data may change in one stage while your code remains the same. At another point your code may change along with the data and the model too.
With Pachyderm, every step in the machine learning loop is a transformation. We use JSON or YAML to define a transition from one state to another. It covers everything from data ingestion to model output at the end of the pipeline.
You might write a script to pull all the data from one external data source into the Pachyderm platform, and another script to pull from a different data source. Then you might rename all the files or clean them in another step. In another stage you may lean on a labeling engine like Label Studio, which we integrated with, followed by a series of new training jobs. Each step is part of that workflow and easily defined in Pachyderm so it flows from one step to the next easily.
How much simpler can ML development get in the next 3-5 years and what are the main challenges that need to be addressed to trigger mainstream developer adoption?
JD: It can get a lot simpler and it will, but don’t forget that AI/ML is really young. AlexNet came out in 2012, less than a decade ago, and spurred the current wave of ML and GPUs to power deep learning.
AlexNet took it out of the research labs and into the enterprise. But what big companies like Google found is they couldn’t just use the same tools they already had for traditional development. They needed new tools and they had to start from scratch.
That’s because AI/ML is a totally new branch on the software development tree. It’s not just the AI/ML infrastructure software that’s changing, it’s the very way we create AI’s that’s changing at the same time. Reinforcement Learning is taking off right now and will likely need tools we haven’t fully conceived of yet as we do it at bigger and bigger scales. Innovation in a new space is not an overnight process.
Traditional software development was mostly baked for many, many years. We had a few innovations, like object-oriented programming and DevOps vs waterfall development, but those innovations were building on well-defined innovations before them. We’re still figuring out what we need in ML. Feature stores barely existed a few years ago and now we have multiple companies designing them. It takes lots of people working on a problem across the world to converge on a solution that works for everyone else and becomes standard.
As we figure out the basic primitives and design patterns in this space, we’ll get more advanced and more automated and that will let us go from putting a few models in production, that required a lot of hand-holding to get there, to putting 1000s of models in production fast in a highly automated way.
Do you like TheSequence? Consider subscribing to support our mission to simplify AI education, one newsletter at a time. You can also give TheSequence as a gift.
💥 Miscellaneous – a set of rapid-fire questions
Favorite math paradox?
JD: Gödel's incompleteness theorem.
Is the Turing Test still relevant? Any clever alternatives ?
JD: It’s useful as a thought experiment, and it lays the groundwork for thinking about testing AI. The test itself is no longer that useful for testing modern ML.
Probably the best, updated alternative is the Abstraction and Reasoning Corpus (ARC, by Chollet from his paper, On the Measure of Intelligence. Also check the Q&A with him here.)
Abstraction is what separates humans from machines. We only need to get cut once by a knife to abstract the idea that sharp = danger. We don’t need to see a million pictures of jagged rocks to know they will cut us too.
Any book you would recommend to aspiring data scientists?
JD: Deep Learning with Python by Francois Chollet is brilliant.
Is P equals NP?
JD: The fascinating thing about P = NP is that unlike other prominent open problems it doesn’t seem like one outcome is more likely than the other. Whereas for many open questions it seems very likely the theorems are true, the proof just eludes us.
It's also worth asking how much it matters if it is true?
Do we need to know if every NP problem has a shortcut or is it all right if we find shortcuts to many of those problems as they become important to humans?
We’ve already seen better algorithms to generate solutions to NP problems so we don’t have to brute force through every solution. I think AlphaGo and AlphaGo Zero, as well as Google’s new chip design software, shows that given enough need humans will find a shortcut.
So maybe that means P does equal NP. 😊
I'll bet on human ingenuity to find a shortcut when it matters most and I find it hard to believe that the most important problems don’t have shortcuts that can help us approximate the best answer.
TheSequence is a member of AIIA.