
⛑👑 Edge#89: Feature Learning – What Makes Some Features Better Than Others?
In this issue:
we discuss what makes some feature representations better than others;
we explore Uber’s architecture to discover optimal features;
we overview three architectures powering feature stores at Airbnb, Pinterest, and DoorDash.
💡 ML Concept of the Day: Feature Learning. What Makes Some Features Better Than Others
Feature extraction and selection are one of the fundamental building blocks of modern machine learning pipelines. In Edge#10, we have discussed feature extraction/selection and representation learning in-depth, including diverse techniques and technologies like feature stores that are actively used in this area. Regardless of the technological approach to feature representation, there is a common question that haunts data scientists in most machine learning workflows: What makes some feature representations better than others? This might seem like a silly question if we are thinking about scenarios with a handful of features, but think about modern machine learning problems that are modeled using hundreds of thousands or even millions of features that are impossible to interpret by domain experts.
While there is no trivial answer to our target questions there are some general principles that we can follow. In general, there are three key desired properties in feature representations:
Disentangling of causal factors.
Easy to model.
Works well with regularization strategies.
Fundamentally, solid representations include features that correspond to the underlying causes of the observed data. More specifically, this thesis links the quality of representations to structures in which different features and directions correspond to different causes in the underlying dataset, so that the representation is able to disentangle one cause from another.
Another leading indicator of good representation is the simplicity of modeling. For a given machine learning problem/dataset, we can find many representations that separate the underlying causal factors but they could be brutally hard to model.
The final quality of solid knowledge representations is related to structures that work well with regularization strategies. This is super important as machine learning axioms such as the “no free lunch theorem” show that regularization is often needed to achieve knowledge generalization. From that perspective, a representation structure that can not be used in regularization strategies is unlikely to lead to generalization. In general, there are some properties of feature representations such as smoothness, linearity or causal factors that are good indicators of the effectiveness of regularization methods.
So there you have it, those three elements are often non-obvious but represent some of the key attributes of robust feature representations.
“If you think of features as the most valuable signal you can extract from a given set of data,” said Mike Del Balso, co-founder and CEO of Tecton, “it becomes clear that how those features are represented and structured is critical to both the quality of that signal and your ability to leverage that signal for automated decision-making through ML.”
🔎 ML Research You Should Know: Uber’s Architecture to Discover Optimal Features
In a recent blog post titled “Optimal Feature Discovery: Better, Leaner Machine Learning Models Through Information Theory” engineers from Uber detailed the architecture used to optimize feature evaluation and selection.
The objective: Build an architecture that leverages principles of information theory to optimize the selection of features in Michelangelo Palette, Uber’s feature store.
Why is it so important: Uber’s feature selection optimization architecture is one of the first examples of applying this type of technique at scale.
Diving deeper: Selecting the right features for machine learning models in large-scale infrastructures is a massive challenge. In those scenarios, data scientists can be faced with the problem of choosing between existing or potential new features in order to improve the performance of the model. Selecting too many features makes models vulnerable to the course of dimensionality and decreases their interpretability. Techniques such as feature pruning are super interesting but they are highly dependent on the specific trained model. In general, there are two major challenges with feature selection:
Sprawling: It’s very typical to add features to a model and never recycle them, creating models with a large number of inefficient features over time.
Redundancy: Because of the constant addition of features, it is very common to end up with models with a redundant number of features.
To address some of these challenges, Uber referred to the legendary information theory pioneered by Claude Shannon in 1948. In principle, information theory uses mathematical models to quantify the relevance of information in the presence of uncertainty. Without getting into too many mathematical details, Uber incorporated some ideas from information theory into a tool called X-Ray used for feature exploration in the Palette: Michelangelo feature store. Given the scale of Uber’s machine learning operations, Palette hosts tables that have hundreds of thousands of features used across different machine learning pipelines. Palette’s X-Ray uses ideas from information theory to streamline the exploration of features relevant to a specific dataset or machine learning model, preventing data science teams from building redundant features.
“When we originally created the Michelangelo platform at Uber, one of the defining goals was to enable efficient feature sharing and discovery, as we knew this would pay dividends by empowering the teams at Uber to put ML into production leveraging existing, high-value features” said Mike Del Balso, co-founder and CEO of Tecton. “X-Ray seems to be a natural extension of that defining goal by presenting practitioners at Uber with the most valuable features that are available to them.”

Image credit: Uber
Based on the principles of information theory, Uber’s methodology for feature selection has two main phases:
Feature Ranking: This phase starts with a dataset containing all possible features for a given model which are then joined with other applicable features in the Palette store. After that, the X-Ray selection algorithm ranks the features according to their relevance.
Feature Pruning: In this phase, competing models are trained using different sets of the top candidate features. The best candidate models are selected based on their accuracy.

Image credit: Uber
The idea of applying techniques from information theory to feature selection is certainly clever. Implementing these feature selection methods at scale with Michelangelo’s Palette represents a very solid validation. Feature store platforms like Tecton already incorporate similar feature selection ideas but we should see wider adoption of these principles in mainstream feature store stacks in the near future.
🙌 Partner’s section

🤖 ML Technology to Follow: Three Architectures Powering Feature Stores at Large Technology Companies
Why should I know about this: Drawing inspiration from the architectures by companies like Airbnb, DoorDash, and Pinterest that they built to enable feature engineering and storage in their machine learning pipelines.
What is it: In several issues of this newsletter, we have discussed leading feature store platforms such as Tecton, Hopsworks and Feast, which provide end-to-end solutions for the lifecycle of features in machine learning pipelines. However, the feature store platform vendors are not the only ones driving innovation in the feature store space. Large technology companies have also pioneered innovative solutions for feature stores in their machine learning architectures.
Buying vs. building is an interesting decision point when it comes to feature stores. For most environments, commercial feature store platforms can accelerate the lifecycle of machine learning models. However, some massively large machine learning pipelines often include very specific requirements that favor the idea of custom building a feature store architecture. The whole concept of feature stores originated as part of one of those custom solutions at Uber. However, Uber is not the only fast-growing tech company building custom feature store solutions. Let’s look at some interesting feature store architectures that, although not widely documented, provide some interesting perspectives about the intricacies of this type of solution.
Airbnb
Airbnb has quietly become one of the most active contributors to open-source machine learning projects. Over the last few years, Airbnb has built a massive infrastructure that powers many core capabilities of machine learning systems. In terms of feature stores, Airbnb built Zipline, a training feature repository that serves features with different levels of granularity.
For building a given training set, Zipline backfills with hundreds of features and judges its efficacy. The current architecture includes batch and streaming feature engineering workflows powered by Spark and Flink respectively.
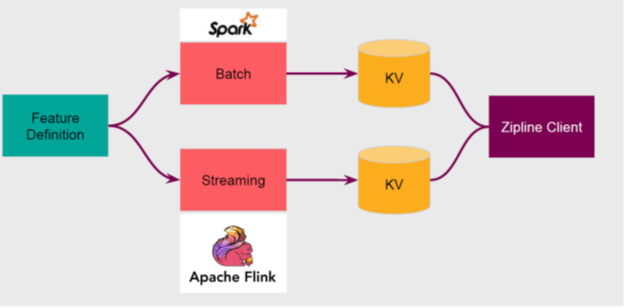
Image credit: Airbnb
DoorDash
DoorDash is another company that has made feature stores a key component of its machine learning architecture. After evaluating several architectures, the DoorDash engineering team settled on Redis as the backbone of its feature store platform. DoorDash’s current architecture includes both batch features through long-running ETLs, which interact with a data warehouse to calculate aggregations over historical data. Additionally, the architecture also includes real-time features processed via a Kafka infrastructure which also uses Flink for real-time aggregations.

Image credit: DoorDash
Pinterest
Galaxy is the name of the feature store platform powering machine learning workflows at Pinterest. Like some of the other architectures explored in this article, Galaxy enables online and offline feature serving for real-time and historical features respectively. Even more interesting is the fact that Galaxy includes a domain-specific language called Linchpin for feature definition for both model training and serving.
