
🍩 Edge#11: The Universe of Meta-Learning~
In this issue:
we discuss the concept of meta-learning;
we explore Berkeley AI Research Lab’s famous paper about an algorithm for meta-learning that is model-agnostic;
we deep dive into Comet.ml, which many people call the GitHub of machine learning.
Enjoy the learning!
💡 ML Concept of the Day: What is Meta-Learning?
Traditional machine learning theory teaches us that the universe is divided into two forms of learning: supervised and unsupervised. Reality is a bit more complicated and there are dozens of learning paradigms that sit between those two extremes. Meta-learning is one of those paradigms that has gotten lots of attention in recent years. It focuses on a fascinating idea: learning to learn.
The term meta-learning was originally coined in 1979 by Donald B. Maudsley, who defined it as "the process by which learners become aware of and increasingly in control of habits of perception, inquiry, learning, and growth that they have internalized". In the context of machine learning, meta-learning typically refers to the ability of a model to improve the learning of sophisticated tasks by reusing knowledge learned in previous tasks. This concept shows similarities with other machine learning ideas such as transfer learning or multi-task learning, but the core difference is that meta-learning centers not only on knowledge reusability but on the process of generalizing learning methods and acquiring knowledge faster. In more “machine learning-ish” terms, meta-learning is a paradigm where a machine learning model gains experience over multiple learning episodes – often covering distribution of related tasks – and uses this experience to improve its future learning performance. Effectively, meta-learning models learn the process of learning.
Just as learning paradigms cannot be simply divided into supervised and unsupervised methods, meta-learning paradigms cannot be encapsulated into a single group. Most of the meta-learning methods included in modern deep learning frameworks fall into one of the following categories:
Optimizer Meta-Learning: this type of meta-learning technique is used to optimize the performance of an already existing neural network.
Metric Meta-Learning: this type of meta-learning method is used to determine if a specific metric is used effectively by a neural network.
Few Shots Meta-Learning: this type of meta-learning method focuses on learning from unseen datasets.
Recurrent Model Meta-Learning: this type of meta-learning trains a model to train another neural network.
As traditional supervised learning methods face roadblocks due to the requirements of large labeled datasets, paradigms such as meta-learning are likely to gain relevance within the next generation of machine learning models.
🔎 ML Research You Should Know: The MAML Paper
In Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, researchers from the Berkeley AI Research Lab introduced a meta-learning algorithm that is completely agnostic to the architecture of the target model.
The objective: The Model-Agnostic Meta-Learning (MAML) technique explores how meta-learning can be ubiquitously applied to incredibly diverse deep learning models.
Why is it so important: The MAML paper is considered one of the most influential papers in the history of meta-learning. Its publication inspired a new generation of research and implementations in the field of meta-learning.
Diving deeper: The ultimate goal of meta-learning is to train a model on a variety of learning tasks so that it can solve new tasks with very little training. However, one of the challenges of meta-learning methods is that they tend to optimize for the type of model they are intending to produce. In the MAML paper, the researchers introduced a meta-learning method that is both general and model-agnostic. By model-agnostic, we mean that MAML can be applied to any algorithm that has been trained using a gradient descent procedure, which is the same as saying, ‘deep neural networks’ 😉.
The key principle behind MAML is incredibly simple. The technique trains the model parameters in a way that the model can achieve maximum performance on a new task, just by adjusting the parameters with a small training dataset. Think of a model that masters tasks such as ball handling, jumping, running, and can be efficiently adapted to master games like basketball or football. Wouldn’t that be nice?
In MAML, the meta-learner seeks to find an initialization that is not only useful for adapting to various problems, but that can do so in a small number of steps, using only a few examples. Let’s look at the figure below. Assume that our model is seeking to find a set of parameters θ that are highly adaptable. The line represents the meta-learning process in which MAML optimizes a set of parameters in such a way that when a gradient step is taken with respect to a particular task (represented by the gray lines), the parameters are close to the optimal parameters θ∗i for task i.

Image credit: the original research paper
Unlike other meta-learning methods, MAML does not seek to learn an updated function or learning rule, nor does it expand the number of learning parameters needed to train a model on a new task. Furthermore, MAML does not impose any constraints on the architecture of the target model. The MAML approach is incredibly flexible and can be adapted to many deep learning tasks. It’s not a surprise that MAML has become one of the most popular techniques of modern meta-learning architectures.
🤖 ML Technology to Follow: Comet.ml is a Platform for Meta Machine Learning
Why should I know about this: Comet.ml is one of the machine learning platforms that’s gaining increasing traction within data science teams. The platform streamlines the creation of machine learning models and experiments across different frameworks.
What is it: Many people refer to Comet.ml as the GitHub of machine learning programs. Comet.ml is not a repository for machine learning projects but, in the same way GitHub was able to streamline collaborative software development, Comel.ml is trying to achieve a similar goal for machine learning applications. Comet.ml provides a consistent model for data science teams to track their data sets, model changes, and experimentation history across many platforms and frameworks.
Comet.ml can be considered a workflow-agnostic machine learning platform. Every time you run an experiment, Comet.ml records snapshots of the code, parameter configuration, and other relevant artifacts, and tracks them using a simple interface. From that perspective, data science teams can use Comet.ml to keep track of all the components of a machine learning project. However, the platform is capable of so much more. Comet.ml allows a data science team to run experiments, compare results, and debug models using a consistent user interface. Considering that experimentation surpasses 50% of any machine learning project, you can get an idea of the relevance of platforms like Comet.ml.
One of the interesting capabilities of Comet.ml is what they refer to as Meta Machine Learning. Under that term, Comet.ml groups a series of capabilities such as automatic hyperparameter optimization, early stopping, and neural architecture search (covered in Edge#4) that accelerate the implementation of machine learning models. Comet.ml provides automatic integration with many machine learning programs such as TensorFlow, Keras, PyTorch, Scikit-Learn, and many others. Integrating Comet.ml into machine learning programs using any of these frameworks is simply a matter of adding a few lines of code.
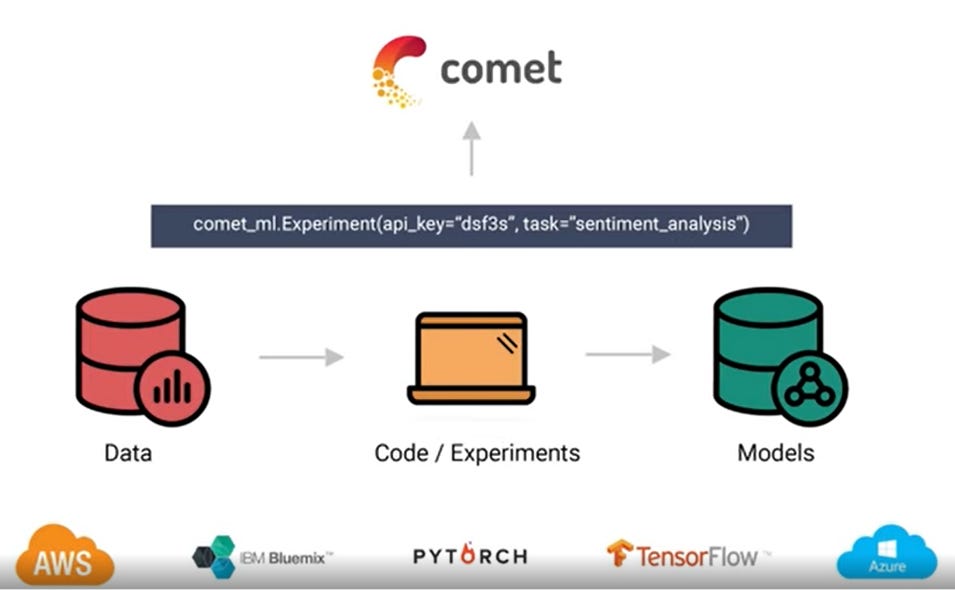
Image credit: Comet.ml
The toolset for managing the end-to-end lifecycle of machine learning applications is still in very nascent stages, but its importance is increasing rapidly. Combining a robust toolset with clever meta machine learning techniques, Comet.ml is certainly one of the platforms that you should keep on your radar.
How can I use it: You can start playing with Comet.ml by creating an account at https://www.comet.ml/signup and follow the quick start integrations https://www.comet.ml/docs/.
🧠 The Quiz
Now, let’s check your knowledge. The questions are the following:
Meta-learning concept shows similarities with other machine learning ideas such as transfer learning or multi-task learning. What is the core difference?
Model-Agnostic Meta-Learning (MAML) is a technique proposed by researchers from Berkeley AI Research Lab. What is the core principle of MAML?
Please use an email you are signed up with, so we can track your success.
That was fun! Thank you. See you on Thursday 😉
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. TheSequence keeps you up to date with the news, trends, and technology developments in the AI field.
5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space. Make it a gift for those who can benefit from it.
We have a special offer for group subscriptions.
