
Edge#4: Beauty of Neural Architecture Search, and Uber's Ludwig that needs no code
In this issue:
we look at Neural Architecture Search (NAS) that is equal to or outperform hand-designed architectures;
we explain the research paper “A Survey on Neural Architecture Search” and how it helps to understand NAS;
we speak about Uber’s Ludwig toolbox that lowers the entry point for developers by enabling the training and testing of ML models without writing any code.
💡 ML Concept of the Day: What is Neural Architecture Search?
Developing neural networks is hard and typically relies on the subjective opinion of experts. Let’s take a simple scenario in which we are trying to build a predictive model for a specific attribute. Based on the definition of the problem, one data scientist might decide that recurrent neural networks (RNNs) are the way to attack it while another expert could think that a combination of convolutional neural networks (CNNs) and RNNs is more efficient. Even after we settle on a deep learning technique, we still need to decide factors such as the number of layers, parameters, and other elements that influence the nature of the model. Given a specific problem, how can we determine the correct neural network architecture to achieve the desired outcome? Could we use ML to solve that challenge?
Neural architecture search (NAS) is a machine learning technique for automating the creation of neural networks. Conceptually, NAS focuses on finding the right neural network architecture for a given problem. A NAS technique will take inputs as a dataset and a task (classification, regression, etc.) and will output a possible set of architectures.
An important aspect to understand NAS is its relationship with another popular ML field: AutoML which we’ve discussed in Edge#2. From a functional standpoint, NAS can be seen as a subset of AutoML. While NAS is more focused on model architecture, AutoML covers a broader set of automation tasks such as training, deployment, and model serving. In any case, both NAS and AutoML are likely to play a key role in the next phase of the deep learning space.
🔎 ML Research You Should Know About: A Survey on Neural Architecture Search
A Survey on Neural Architecture Search was published in 2019 by a group of AI researchers from IBM. It’s considered by many to be one of the key papers to understand the NAS space.
The objective: The NAS space is growing very rapidly and the amount of research can be overwhelming. A Survey on Neural Architecture Search provides a survey of the most important NAS methods, principles, and components in order to help researchers make sense of this rapidly growing area of research.
Why is it so important: It unifies and categorizes the different NAS methods using a consistent structure, comparing and contrasting the key building blocks of NAS models. This is one of those papers that any data scientist working with NAS methods should consult from time to time.
Diving deeper: The main idea of NAS methods is to find the best neural network architecture for a given problem. Despite the diversity and rapid growth in the number of NAS techniques, they can all be abstracted in two fundamental steps:
What to search for: a search space that constraints the different options available for the design of specific neural networks;
How to search: a search algorithm defined by an optimizer that interacts with the search space.
1️⃣ In A Survey on Neural Architecture Search, IBM proposes two fundamental types of search spaces for all NAS problems:
Global Search Space covers graphs that represent an entire neural architecture;
Cell Search Space focuses on discovering the architecture of specific cells that can be combined to assemble the entire neural network.
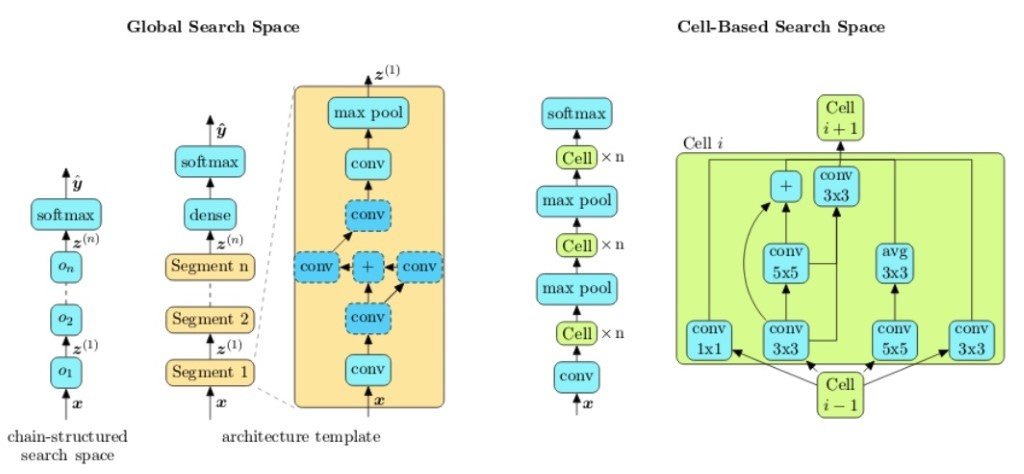
Both global and cell search spaces have pros and cons. Cell-based search spaces have a unique benefit: the produced architectures can be applied across different datasets. At the same token, global search spaces architectures are easier to modify and have proven more effective in scenarios such as mobile neural networks.
2️⃣ The second component of the NAS technique is an optimization method. The IBM paper presents three fundamental optimization methods:
Reinforcement Learning: these optimization models leverage reinforcement learning action-reward duality to have agents that modify the architecture of a neural network and receive a reward based on its performance.
Evolutionary Algorithms: evolutionary algorithms are population-based global optimizer for black-box functions which consist of following essential components: initialization, parent selection, recombination and mutation, survivor selection. In the context of the neural architecture search, the population consists of a pool of network architectures.
One-Shot Models: this type of optimizer trains a single neural network during the search process. This neural network is then used to derive architectures throughout the search space as candidate solutions to the optimization problem.
These optimization approaches have their own limitations and advantages. For instance, one-shot approaches are particularly interesting and comprise methods that train a single model that encompasses all the samples encountered during the search process. At the same time, evolutionary optimizers are better in predicting performances or do a look-ahead for the performance respectively, thereby saving a significant amount of actual training time.
The IBM paper goes further and compares the efficiency of the combination of the different search spaces and optimizer models. From that perspective, the paper has become one of the most important references to deep dive into the NAS space.
🤖 ML Technology to Follow: Uber’s Ludwig is an Open Source Framework for Creating ML Models Without Writing Any Code
Why should I know about this: Most developers struggle to get started with ML frameworks. Concepts such as training and model serving are difficult to grasp for mainstream developers. Platforms like Ludwig lower that entry point by enabling the training and testing of ML models without the need to write code.
What is it: Ludwig has been built on top of TensorFlow and abstracts its core building blocks from the development experience. To use Ludwig all you need is a data file with the inputs attributes and the desired outputs, Ludwig does the result. Ok, that sounds a bit too easy to be true but it really works that way in many scenarios. Behind the scenes, Ludwig uses the input and output definitions to perform a multi-task learning routine to predict all outputs simultaneously and evaluate the results. This simple structure is key to enable rapid prototyping. Ludwig is able to do that because it includes a series of deep learning models that are constantly evaluated and can be combined in a final architecture.
Functionally, Ludwig can be seen as a framework for simplifying the processes of selecting, training, and evaluating ML models for a given scenario. Ludwig provides a set of model architectures that can be combined together to create an end-to-end model optimized for a specific set of requirements. Conceptually, Ludwig is based on a series of principles:
No Coding Required: Ludwig enables the training of models without requiring any ML expertise.
Generality: Ludwig can be used across many different ML scenarios.
Flexibility: Ludwig is flexible enough to be used by experienced ML practitioners as well as by non-experienced developers.
Extensibility: Ludwig was designed with extensibility in mind. Every new version has included new capabilities without changing the core model.
Interpretability: Ludwig includes visualizations that help data scientists understand the performance of ML models.
The main innovation behind Ludwig is based on the idea of data-type specific encoders and decoders. Ludwig uses specific encoders and decoders for any given data type supported. Like in other deep learning architectures, encoders are responsible for mapping raw data to tensors while decoders map tensors to outputs. The architecture of Ludwig also includes the concept of a combiner which is a component that combines the tensors from all input encoders, processes them, and returns the tensors to be used for the output decoders.

The image credit: Ludwig on producthunt.
One of the main benefits of Ludwig is that it integrates with many cutting edge tools such as Comet.ML and also includes prebuilt versions of modern deep learning models such as Google BERT.
How can I use it: Ludwig is free, open source and is available at https://github.com/uber/ludwig. The framework can be installed as a traditional Python package and can be used from the command line or a programmable API.
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. TheSequence keeps you up to date with the news, trends, and technology developments in the AI field.
5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space. Make it a gift for those who can benefit from it.
