
The Sequence Opinion #790: From Book Smarts to Street Smarts: How AI Benchmarks are Changing
A shift from static benchmarks to dynamic evaluations is a key requirement of modern AI systems.
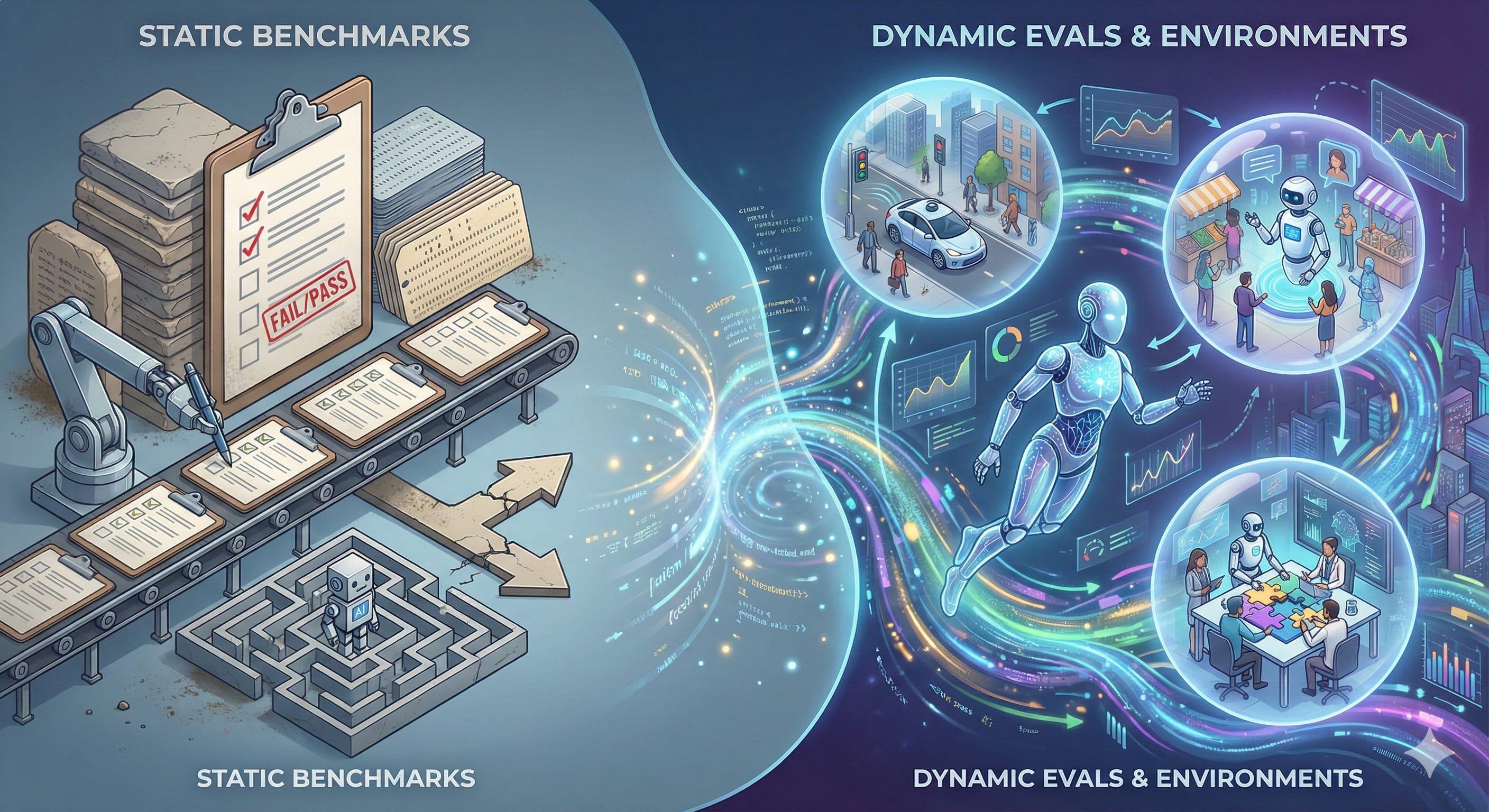
If you’ve been watching the loss curves lately, you might have noticed a structural transition in the field that is technically profound but metrics-poor. We are effectively moving from the era of the Chatbot—a stochastic, next-token prediction engine—to the era of the Agent—a digital employee expected to navigate, reason, and execute long-horizon workflows. This isn’t just a product update; it’s a fundamental shift in the ontology of intelligence.
For the last few years, the “unit test” for AI has been the static benchmark: a frozen list of questions and answers, basically digitized versions of the SATs or StackOverflow. We measured intelligence by the ability to retrieve information or compress the internet into a set of weights. But as we settle into 2026, the utility of these static numbers is collapsing. We are witnessing the saturation of datasets like MMLU and GSM8K, not necessarily because models have achieved human-level reasoning, but because they have effectively memorized the test.
The “vibe” in the research community has shifted. We stopped celebrating 90% scores on math tests and started asking why that same model can’t fix a simple bug in a repo without hallucinating a dependency. This essay explores that transition. We are moving from “Question-Answer” pairs to “Observation-Action” loops, and that requires us to build entirely new gymnasiums for these models to work out in.