
The Sequence Opinion #730: Reinforcement Learning: a Street-Smart Guide from Go Boards to GPT Alignment
The walkthrough the history of RL.
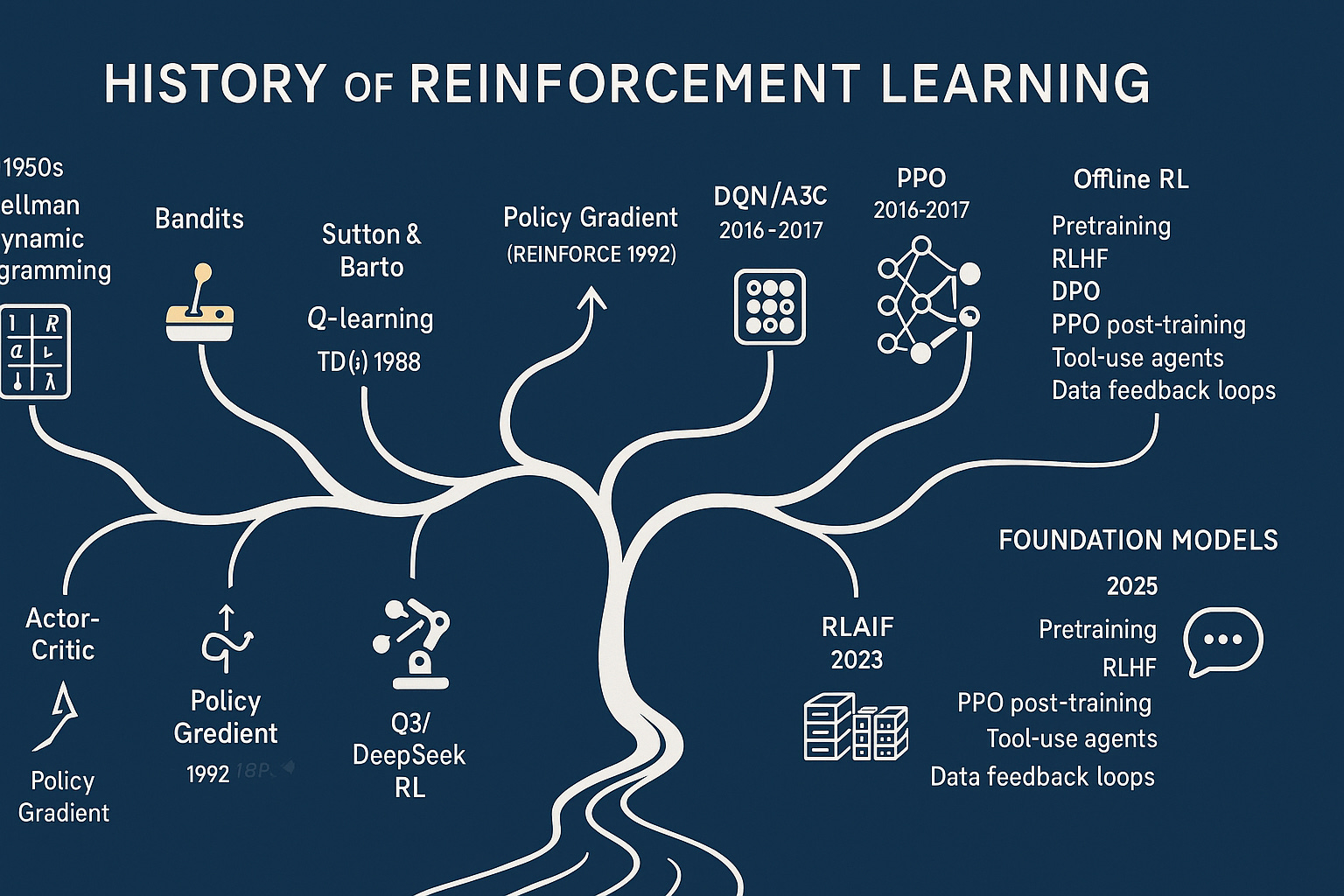
Reinforcement learning (RL) is the part of AI that learns by doing. Not from a teacher with answer keys (supervised learning), and not by free-associating the web (self-supervised pretraining), but by poking the world, seeing what happens, and tweaking itself to do better next time. Think of a curious agent in a loop:
look at the world
pick an action
get a little pat on the back (or a slap on the wrist)
update itself
repeat forever
That’s RL. It’s simultaneously powerful and annoying: powerful because it can discover strategies nobody wrote down; annoying because it’s sample-hungry, finicky, and loves to “hack” whatever score you give it.
Below is a guided tour: where RL came from, the big algorithmic building blocks, the AlphaGo → AlphaZero → MuZero leap, the migration from games to reality, and how today’s frontier models use RL after pretraining (RLHF, RLAIF) to become useful and safe(-ish).
Origins: trial-and-error with a feedback loop
Early psychology noticed a simple rule: actions that lead to good outcomes get repeated. Control theory made it operational: if you can estimate how “good” a situation is, you can plan and optimize decisions over time. Computer science then wrapped this into the agent loop above and asked: how do we learn a good way to act when the world is messy, delayed, and sometimes random?
Two concepts emerged and never went away: