
The Sequence Knowledge #866: Three Text Diffusion Models You Need To Know About
LlaDa, Gemini Diffusion and Mercury rule the space.
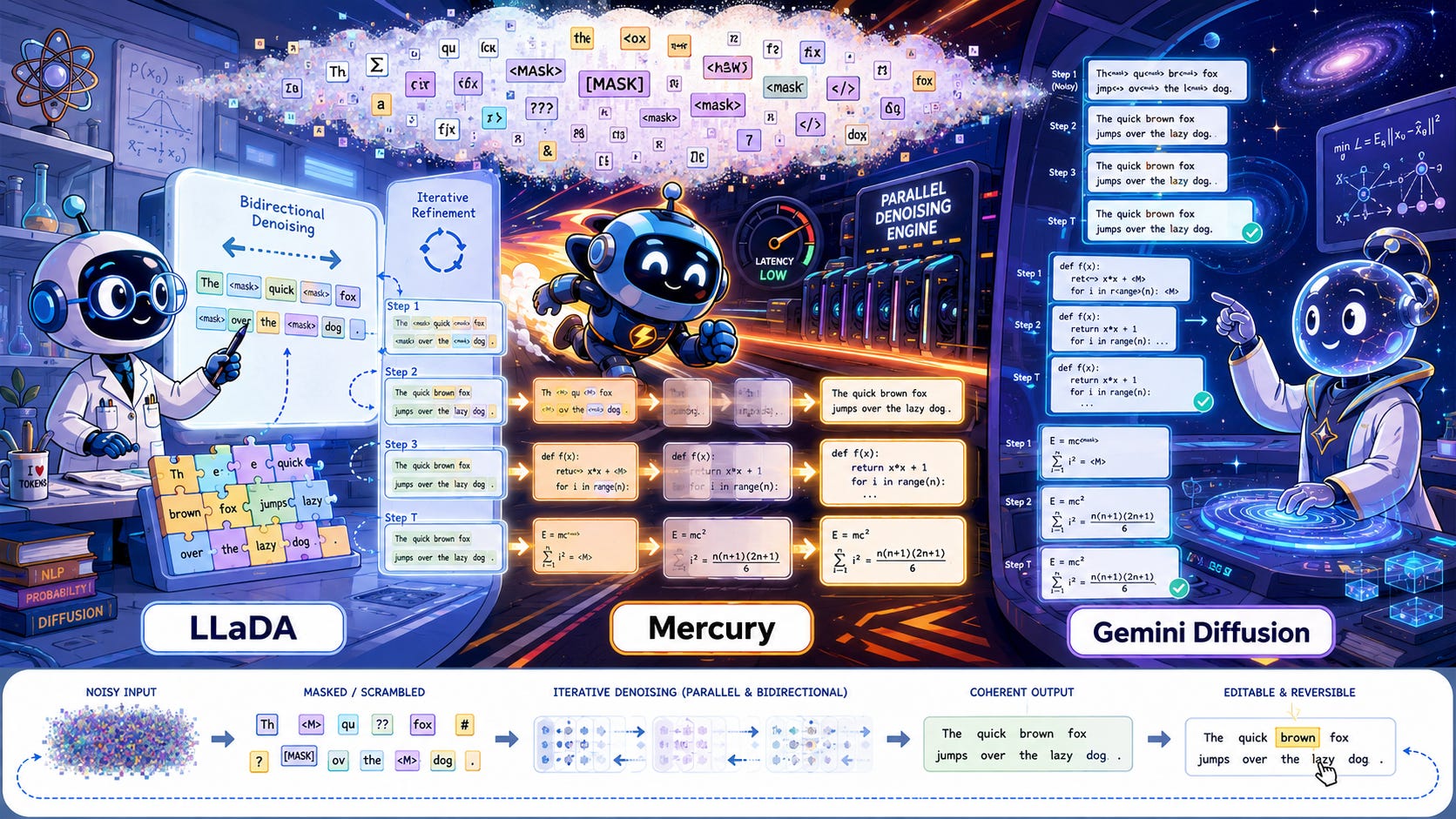
💡 AI Concept of the Day: Three Text Diffusion Models You Need To Know About
For most of the LLM era, language generation has been built around a single assumption: text should be produced like a typewriter, one token at a time, left to right, each new symbol conditioned on a frozen history. Text diffusion models challenge that assumption at its root. They treat generation less like typing and more like editing: start from noise or masks, look at the whole canvas, and iteratively refine it into coherent language.
That sounds like a stylistic tweak. It is actually a different computational worldview. Instead of factorizing language as “the next token given all previous tokens,” diffusion models define a corruption process and then learn how to reverse it. In language, that usually means masking tokens or pushing text into noisier latent states, then training a model to recover the original sequence over several denoising steps. The result is a system that can update many positions at once, use bidirectional context during generation, and revisit its own outputs rather than committing irreversibly at every step.
If you look at the field today, three systems define the conversation more than any others: LLaDA, which proved that diffusion can scale into a real large language model; Mercury, which turned diffusion into a genuine commercial speed advantage; and Gemini Diffusion, which signaled that frontier labs see this paradigm as strategically important. Together, they outline the three phases of a new architecture class: scientific proof, industrial deployment, and frontier validation.