
📝 Guest post: 7 key considerations to develop a scalable annotation pipeline
In TheSequence Guest Post our partners explain in detail what machine learning (ML) challenges they help deal with. In this post, SuperAnnotate’s team unveils how to develop a scalable annotation pipeline.
Whether for medical imaging, autonomous driving, agriculture automation, or robotics, scaling a computer vision (CV) project is tough and takes tons of micromanaging, tracking, and analysis for the best results. The data is usually annotated in batches because of the volume and multiplicity of iterations needed along the way. The batches undergo several revisions for continuous improvement of the model accuracy. Generally, free and open-source annotation tools are sufficient to create the first batch of annotations to kickstart a CV project with hundreds to thousands of images. However, when trying to scale, such tools become obsolete, and teams face substantial challenges in creating, managing, and maintaining the constant inflow of high-quality training data within their computer vision pipelines. This post will cover the top 7 considerations to help you scale your CV pipeline.
Robust tooling
Quality management
Collaboration system
CV pipeline integration
Speeding up and automating annotations
Finding the right annotation workforce
Data curation
Final thoughts
Robust tooling
Robust tooling is a must-have for detail-oriented annotations. To build scalable annotation pipelines, the obtained toolset has to be flexible and scalable alike. The increased number of toolsets allows for various functionalities and enhanced accuracy for top performance.

On top of it, CV technology no longer consists of bounding boxes only, and there can be a massive difference between the tools that do and do not support all these features in areas such as image annotation and data labeling. Therefore, to fine-tune your annotation project, you need a user-friendly and feature-rich tool variation to meet your most sophisticated annotation needs. The latter may range from selecting attributes and highlighting motion direction to connecting selected points, freehand drawing vs. straight lines, and so on. In fact, tool selection impacts model performance considerably and can lead to an average of 12% model improvement.
One thing to keep in mind throughout the CV pipeline is the extent to which the selected tools can support an increasing number of annotations per image without necessarily affecting the loading time. Done properly, robust annotation tool selection will improve your model performance significantly.
Quality management
Data quality management is at the core of the CV pipeline. The increasing demand for annotations enhances performance requirements. To that end, it is imperative to create annotation instructions from the very beginning for optimal workflow.
To cut you a fair amount of working time right at the outset, we recommend having a state-of-the-art annotation instruction manual. As the CV industry progresses explosively, a pre-set guide becomes a cornerstone of quality assurance (QA) to avoid further mistakes and establish cohesion within annotation teams.
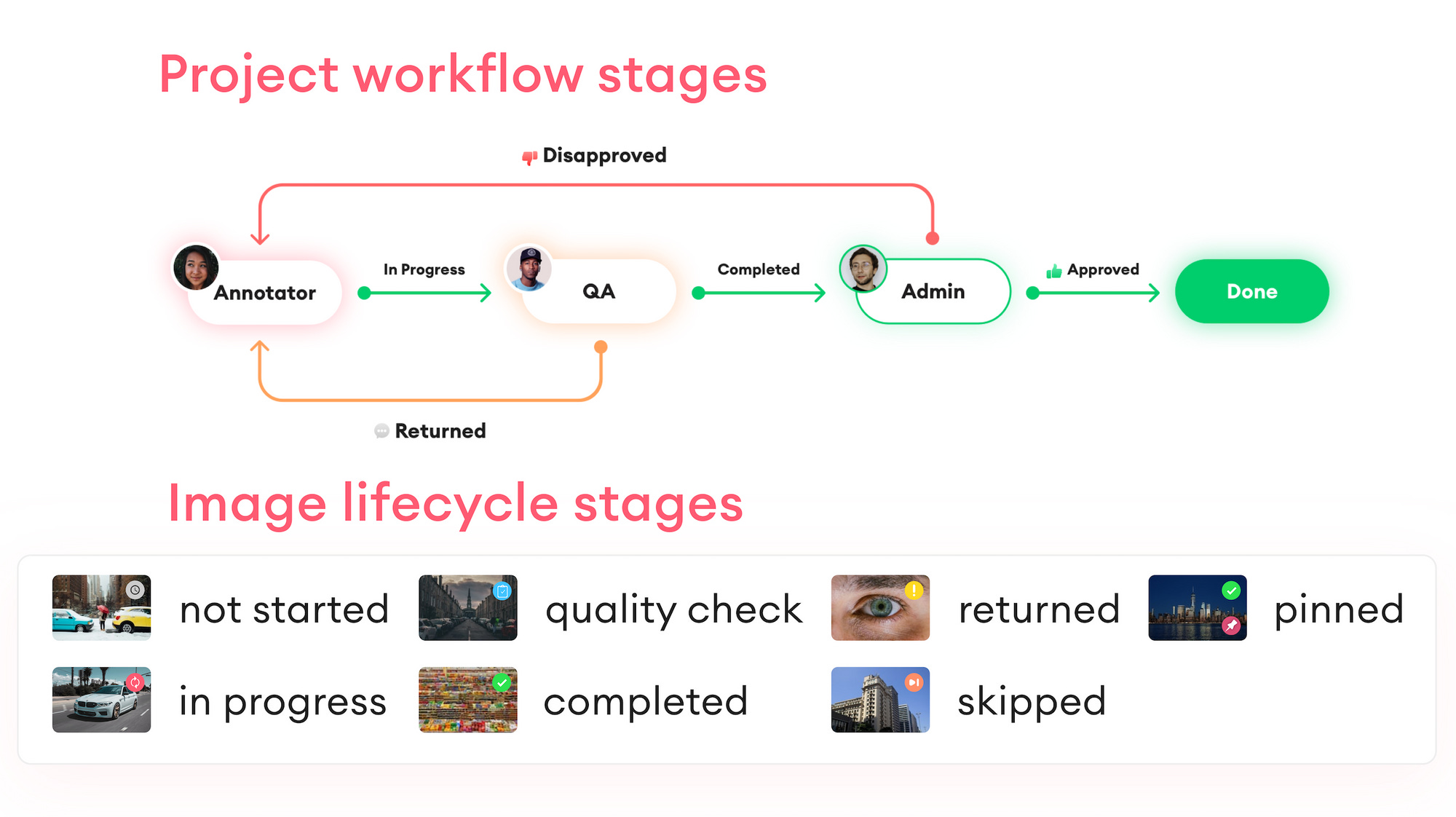
To put it bluntly, the total absence of an in-process quality management mechanism will cost you plenty of time and money, resulting in inefficient collaboration within teams, poor model performance, and dissatisfied users. With a thought-out system and action plan, you can easily detect mislabeled annotations while spending much less time than you would in the case of manual QA.
So, finding ways to reduce your QA time is a worthwhile investment. To ensure high-quality data throughout the CV cycle, further multi-level monitoring and review is required. A solid quality management system will give you the advantage of pre-assigned user roles at various life cycle stages before the cultivated data can be considered a template.
Collaboration system
Your CV project's success depends on how smoothly your teams of annotators, data auditors, managers, and CV engineers interact. It is also crucial to gauge every member's progress and extract the analytics of the team to understand who can benefit at a particular stage most and who needs extra coaching for better results. This way, you will also understand everyone’s speed and quality of work that helps making effective decisions when on a pressing deadline. Identifying the strengths and weaknesses of your team will as well help you come up with more realistic deadlines to reinforce your CV strategy.
Speaking of applications, a robust collaboration system is especially helpful in crisis situations. The COVID-19 pandemic is one of the most recent examples: companies with solid cooperation mechanisms managed to stay afloat of the pandemic as they learned to effectively manage remote annotation teams, no matter the isolation and impending physical restrictions. By assigning and distributing tasks automatically, you can also easily track the progress of each member from anywhere in the world.
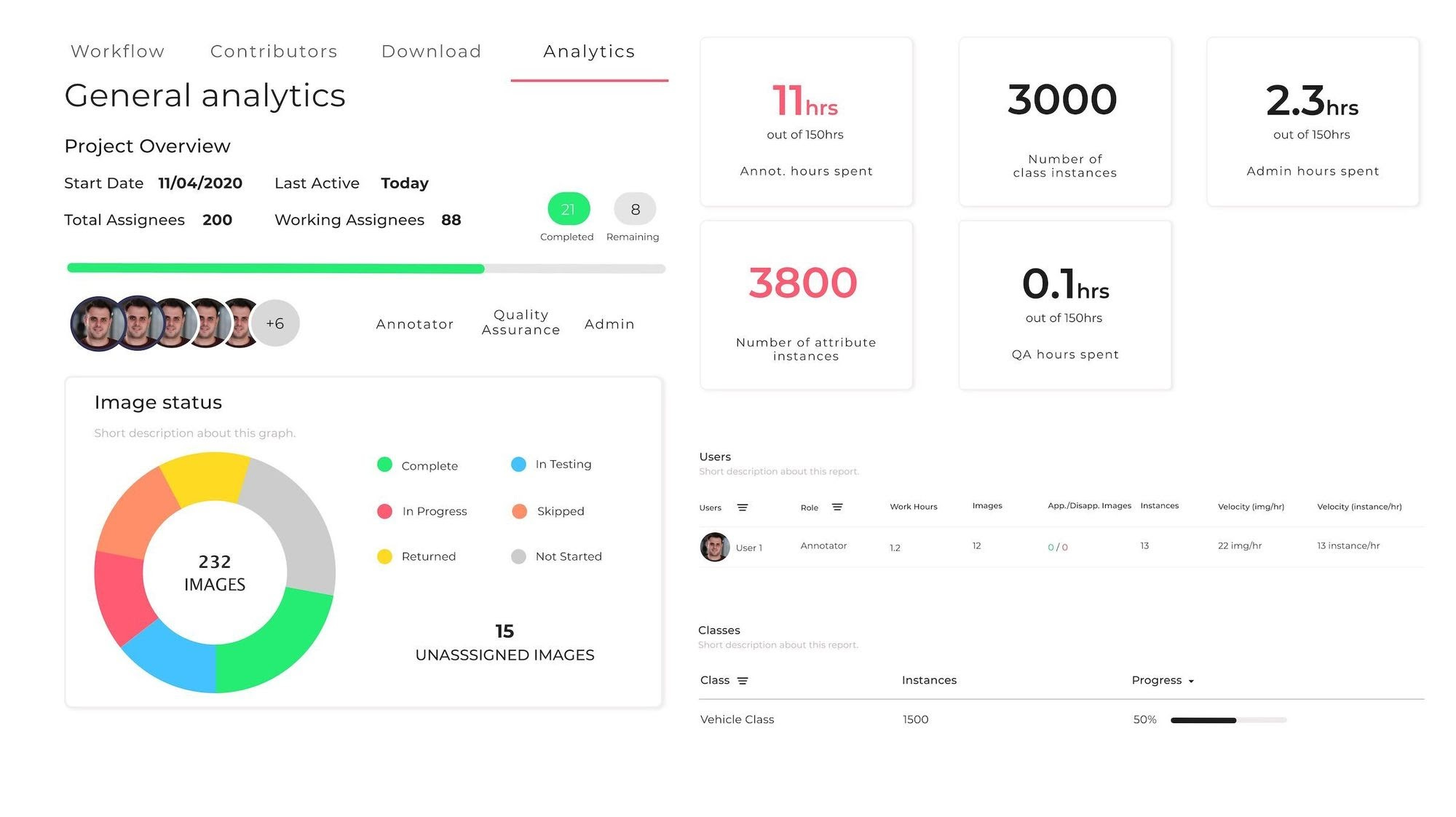
The CV pipeline is propelled by an automated collaboration system as it enables easier communication within teams, minimized number of human errors, effective project instruction, and individual feedback options based on performance. In addition, tracking the number of annotations per annotator without direct oversight in an office setting is quite a privilege these days.
Beware that working remotely puts your data security at risk, which may be a major concern when managing annotation teams. So, your first step towards building a secure system should be risk assessment.
CV pipeline integration
You more than need an automation procedure to streamline data and project management processes to ensure the whole pipeline is operating as one system. While CV pipeline integration can be understood differently, some of the essentials of pipeline integration might include automating the project setup, data manipulation functions, team management, data transfer functions, data versioning, and much more. In simple terms, it is an automation of multiple cycles throughout your pipeline for optimal results. At the same time, your system has to be flexible to additional training for customized functions if your project needs fluctuate. CV pipeline integration will help eliminate manual processes around data management and grant the freedom to implement custom functions within a blink without using much of your workforce.
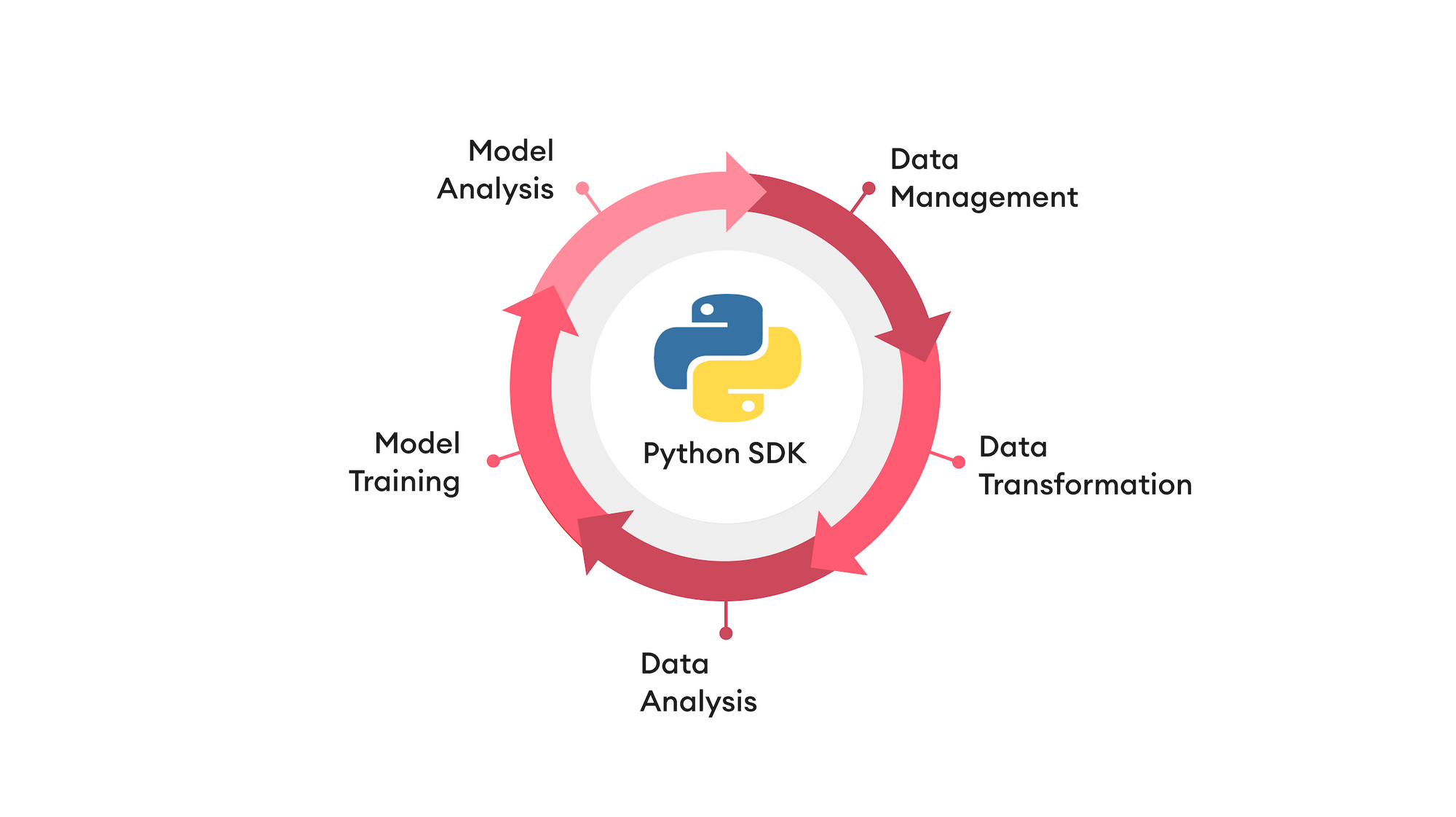
This way, your model will learn to iterate on experiments faster, giving you a competitive advantage over other players in the industry. Have you thought of ways that could potentially boost your model performance quality? Start off with SuperAnnotate's SDK integration.
Speeding up and automating annotations
If you want to have a considerable edge over your competitors, you better avoid spending countless hours on image annotation. You might get away with the load you are provided at this moment, but what if you take on projects with fivefold or tenfold more data? Finding means to speed up your image annotations will give you the confidence to head on projects of any size and complexity level, which in turn will impact the cost, quantity, and quality of your annotations.

Consider workflow optimizations, advanced tooling, and especially transfer learning when optimizing the speed of your annotations. You might be wondering, how will transfer learning impact the annotation speed? It is much faster to readjust and rework the parts of the images that the neural network (NN) failed to predict than manually annotating images on your own. That way, you can score an average of 12% accuracy improvement over the original model.
By using the pre-trained networks and transfer learning, you can tremendously deduct the time otherwise spent on annotations. Consider NN integration to achieve the desired annotation and project completion speed if you haven’t done it yet, and make sure to conduct proper testing of your newly trained NN before applying it to large-scale projects.
Finding the right annotation team
Along with the rapid advance of AI technologies, the task of annotation has become more elaborate than ever, requiring relevant background, experience, and skillset to deliver quality results. Companies opt for outsourcing annotations these days mainly through two outsourced workforces: crowdsourced and professionally managed. That being said, finding professionally managed annotation teams has its own challenges, and your choice should be driven by your project requirements and client objectives.

The evolution of CV has led to the emergence of hundreds of annotation companies around the world, which has made the process of finding and vetting a lot more complicated and risky. Given the importance of consistent, high-quality training data, we strongly recommend against using crowdsourced annotation teams, as they may or may not be full-time annotators and are likely to lack centralized management: there are higher chances you will waste your time, energy, money, and resources on top of receiving poorly annotated images.
If you have access to a trusted network of service providers and annotation teams with the skills and the experience to run the projects efficiently, you better use it now. Marketplaces like these are likely to boost your pipeline more than individual annotation teams or agencies, but that depends on your project features: the choice is yours.
Data curation
The overwhelming amount of AI products underlines the significance of data curation in your CV cycle. Data curation is the active and ongoing process of data management all throughout its lifecycle, encompassing initial storage, collection, and archiving for future re-use. It determines the value of your data to meet the needs and interests of a specific group of users.
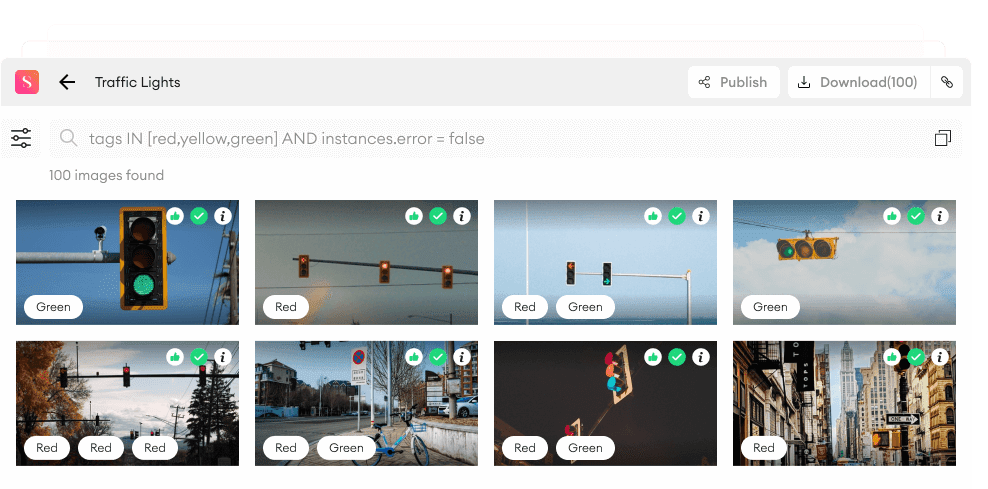
One of the major perks of data curation is that it provides easy access and navigation of your data whenever you need, which, nonetheless, does not concern datasets as much as metadata. Yet, companies internalize and define data curation differently.
Data curators are not merely involved in maintaining, managing databases, and determining which ones are relevant to a particular project. They are just as responsible for coming up with practices to improve the data management quality. The reason why the job of data curators is so important is that there needs to be an arbiter who is aware of the context of the data before it is trusted for use.
The proliferation of modern-day data has made it difficult to stick with a single data curation method. Overall, data curation can optimize the following operations:
Constructing a training dataset
Verification of the resulting training to make sure it’s unbiased
Effectively streamlining your CV workforce
Management of the transfer functions
Sometimes, data curation can be entirely invested in dataset quality management. Once you have your dataset, you can review and analyze it for further training or improve the trained model for top performance. That is the case at SuperAnnotate too, where the tools foster easier navigation across the datasets contributing to model performance accuracy.
Final thoughts
Building a scalable CV pipeline is not one-sitting labor, as you saw. Instead, there are critical considerations for each step all throughout your pipeline that can substantially ease your daily operations and guarantee the success of your project.
Most importantly, the application of at least a few of the proposed considerations will accelerate your entire pipeline, taking your CV operations to the next level.
We hope this article expands your understanding of pipeline optimization to benefit your CV effort. Let us know if you have more questions in the comments below.
*This post was written by SuperAnnotate’s team and originally published on their blog. We thank SuperAnnotate for their ongoing support of TheSequence.
About SuperAnnotate
SuperAnnotate's all-in-one platform with its integrated marketplace of labeling teams is uniquely designed to produce the highest quality training datasets directly into ML pipelines via API, ability to version and manage those datasets, give insights about model performance and any potential biases. You can quickly decide what to label next and focus on building and scaling your pipeline. SuperAnnotate was recognized as one of the top 100 AI companies in the world in 2021 by CB Insights and is already trusted by 300+ businesses, including 20% of Fortune 20.