


🎙 Mike Del Balso/CEO of Tecton: There is too much depth in this space for feature stores to be just a “feature”
TheSequence interviews ML practitioners to merge you into the real world of machine learning and artificial intelligence
There is nothing more inspiring than to learn from practitioners. Getting to know the experience gained by researchers, engineers and entrepreneurs doing real ML work can become a great source of insights and inspiration. Please share these interviews if you find them enriching. No subscription is needed.

👤 Quick bio / Mike Del Balso
Tell us a bit about yourself. Your background, current role and how did you get started in machine learning?
Mike Del Balso (MDB): I am the co-founder/CEO of Tecton, an enterprise feature store. Prior to founding Tecton, I led product efforts for applied ML at Uber and Google.
I spent the last decade building systems to apply ML reliably in the real-world at scale. I was the product manager for ML in Google’s ads auction, which requires first-class operational processes (now called MLOps). This same team published the well-known Machine Learning: The High Interest Credit Card of Technical Debt paper. I later helped start the ML team at Uber where we created Uber’s Michelangelo platform and helped scale ML at Uber to tens of thousands of models in production. This very applied background in ML, solving practical challenges, putting ML in production motivated the founding of Tecton.
🛠 ML Work
Part of the Tecton team coined the term “feature store” as part of Uber Michelangelo project. What was the inspiration for building this new capability in a ML pipeline and did you ever imagine it was going to spark a brand new segment of the ML market?
MDB: At Uber, teams wanted to use data for more than just analytics, they wanted to deploy ML-powered user experiences into the product itself (e.g. ETA estimation). It’s one thing to build a prototype, it’s another thing to deploy and run an ML application reliably in production. We worked with dozens of teams to help them build and operate these production ML systems. It quickly became clear that we were hardly spending any of our time on the actual models themselves. We were spending all our time solving the data engineering problems adjacent to models.
With the first version of Michelangelo, teams could easily deploy models but would start separate large projects to wire up data pipelines to generate fresh feature values and deliver them to the models in production. These projects would take months and were painful to complete. Data scientists were always blocked on engineers – there wasn’t a standard way to reliably create, deploy, and serve ML features. We developed the feature store in Michelangelo to allow teams to create and “deploy” features instantly to production in a standardized way. It was all about unblocking and empowering data scientists. We knew the feature store solved a real pain point at Uber, but didn’t expect it to become such a hot topic so quickly.
Since Uber, the concept of feature stores have gained prominence within the machine learning community. Can you describe what’s the value proposition of a feature store and why are they a necessary component of an ML pipeline?
MDB: Feature store is an interface between your model and your data. Feature stores are about making things simpler for data science teams. Feature pipelines in ML are complex, often involving real-time data processing, continual recalculation, production serving, and correctness/drift monitoring. The goal is to make using a new feature in your ML project as simple as importing a new pip package.
Feature stores enable this simplicity by introducing a new abstraction, the “feature view”. This abstraction separates the feature definition logic from the configuration of the underlying infrastructure. With this abstraction features become portable across environments, which is particularly useful for ML, where models are trained in one environment and operationalized in another. This creates an easy way to retrieve consistent feature values across development and production.

Practically, the feature view abstraction solves several core problems in the ML lifecycle.
Data scientists become empowered to self-serve deploy feature pipelines to production instantly and reliably.
Organizations get a centrally governed catalog of standard features used for experimentation or production decision-making. This also enables reuse across teams.
Finally, feature stores orchestrate end-to-end feature dataflows on your infrastructure, eliminating engineering work on a per-feature level. This means data science teams can build better models with more features, and engineering teams can scale to support more data science efforts with the same resources.
👉 Additional materials: Edge#10: Feature Selection and Feature Extraction
Subscribing you support our mission to simplify AI education, one newsletter at a time
What should be the three core capabilities of an enterprise-ready feature store?
MDB: Feature stores allow you to declaratively define how your features should be computed and accessed, and then provide your models with a unified and consistent interface for feature access across training and real-time production inference.
We recently published a blog post describing the core capabilities of feature stores. A feature store integrates with your data infrastructure to:
Run data pipelines that transform raw data into feature values;
Store and manage the feature data itself;
Serve feature data consistently for training and inference purposes.
This sounds simple but it gets quite complicated when you introduce ML-specific constraints. For example, features need to be accessed consistently offline in batch (for training) and online in real-time (for inference), to avoid train/serve skew:
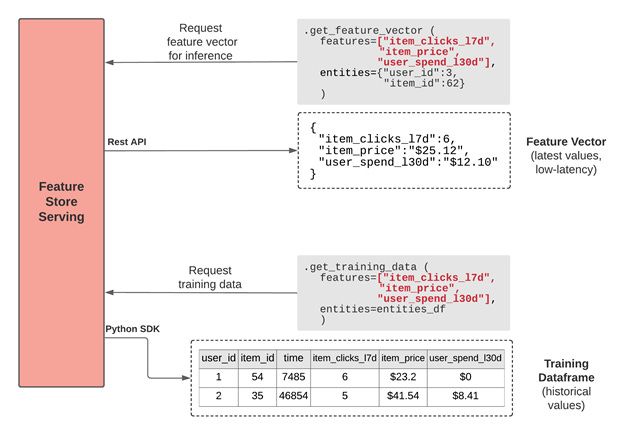
Second, feature data needs to be retrieved for training purposes using time travel, in order to prevent feature leakage. Finally, the most valuable models are often using very different systems as data sources for their features. Feature stores need to support this interface across batch, streaming, and real-time data:
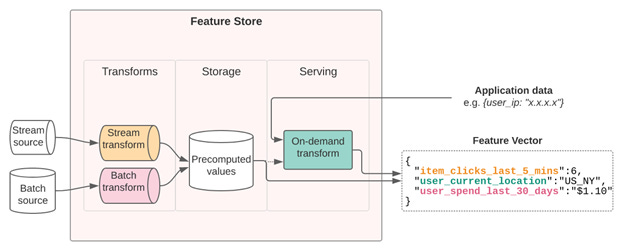
And ideally, you can reuse as much of your existing infrastructure as possible. Feature stores like Tecton deploy into your environment, integrating with your existing data stack.
Recently, big technology platforms like AWS have entered the feature store space. In the long-term, are feature stores a standalone product or a feature (interesting choice of words 😉 ) of broader ML platforms?
MDB: There’s too much depth in this space for it to be a “feature”. These problems practically occupy 90% of teams’ time when deploying ML.
Data is inherently complex, and the dual-environment nature of ML applications (train on data in development, predict on data in production) amplifies this complexity. Companies have entire data engineering teams built out to deal with the challenges feature stores target, and most of them are struggling. A large number of common data traps in Operational ML make critical mistakes easy to make, hard to notice, and even harder to debug. Depth and focus are required to do it right and when your customer experience is powered by ML, leaving features to an afterthought isn’t an option.
Given the growing complexity of this problem space, I believe “end-to-end” ML platforms are over-bundled and too inflexible. They are proving to be mistakes and dead-end investments for teams trying to put ML in production. The dominant strategy for practitioners who are building for the future is to assemble their ML stack with a selection of best-of-breed components, in part due to the diversity of use cases that need to be addressed. This requires the industry to adopt standards and invest in cross-compatibility and pluggability.
What is the vision for the Tecton platform and what are some of the most ambitious ideas you guys are working on?
MDB: Data is the lifeblood of any ML application. The feature store operates those data flows and is quickly becoming the center of the ML stack. We’re opening up interfaces to expose this data to more components/MLOps tools. Your ML monitoring tool should just connect to the feature store and have an immediate view of all the data flows in your ML application. Your AutoML system should plug into your feature store and not only find the best model but the best features as well.
What I’m even more excited about is Tecton’s opportunity to bring operational machine learning to the modern data stack. There’s been so much innovation on the analytics side of the data world. Data teams have spent the past few years centralizing their analytic data into data warehouses or data lakes. The best ML models use both analytic data (e.g. historic user activity) and operational data (e.g. details of the current transaction). The core focus for Tecton is: how can we make developing ML on operational data as easy as modern data warehouses make building dashboards/BI on analytic data?
🔺 If you’re interested in these topics, we’re hosting a conference called Apply() on practical Data Engineering for ML on 4/21-4/22. It’s very practitioner and real-world solutions focused.
Sign up or submit a talk! If you read TheSequence we’d love to have you! 🔻
💥 Miscellaneous – a set of rapid-fire questions
TensorFlow or PyTorch?
MDB: Both. There’s not one tool to rule them all.
Favorite math paradox?
MDB: It has been said before, but for people using data to guide their product changes, Simpson’s Paradox should be top of mind. It’s extremely practical and a good reminder to think experiment results in-depth. It also underlies some of my favorite interview questions.
Any book you would recommend to aspiring data scientists?
All of Statistics is my favorite 101 + reference book. It gives very applied, but rock-solid first principles intuition about data and statistics, which are the core of ML. A colleague on my ML team at Google lent me this and I read every page and did every exercise. It's dense, but you won't regret any ounce of effort you put into it.
Is P equals NP?
MDB: No idea, but like xkcd (“A webcomic of romance, sarcasm, math, and language"), I love bringing it up casually:
