
📝 Guest Post: The Coming Wave of Specialized AI*
In this blogpost, Piero Molino, author of Ludwig.ai, CSO & Co-Founder at Predibase, will make the case for why smaller, faster, fine-tuned LLMs are poised to take over large, general AI models. Training your own model used to require a huge upfront cost, but now open-source models can be fine-tuned on a few thousand examples, a small investment that is quickly amortized compared to using general models that, because of their generality, are very large and expensive. Consequently, companies are adopting a new AI development process that makes it possible to realize business value from AI much faster, and you can adopt it too.
If you’d like to learn more about specialized AI and fine-tuning, join Predibase’s November 7th webinar "Fine-Tune and Serve 100s of LLMs for the Cost of One with LoRAX”.
The rise of general AI
AI has been in the spotlight since late 2022, thanks to groundbreaking generative services such as Midjourney and ChatGPT, which have introduced remarkable capabilities in image generation and text-based interactions. Their success is mostly due to how easy they have made using AI for anyone, not just developers or machine learning experts, through user-friendly interfaces and APIs which eliminated entry barriers.
The simplicity of integrating commercial AI APIs into software applications ignited a wave of excitement and innovation among hackers, entrepreneurs, and businesses, leading to rapid prototyping and widespread adoption.
General AI shortcomings
Today, after a year of experimentation, companies that have integrated AI into their applications are recognizing the challenges posed by the high costs, limited throughput, increased latency, and concerns about privacy and ownership associated with commercial AI APIs. The generality of these APIs, which initially benefited consumers, is becoming a drawback. Why would an enterprise, with specific business tasks, pay the cost of a large model capable of generating French poetry when a specialized, smaller, quicker, task-specific model can often outperform it and cost less? General models are similar to CPUs, capable of handling a variety of tasks reasonably well, while specialized models resemble accelerators, such as GPUs or ASICs: they may lack the same versatility, but excel in specific tasks, use resources better and are more cost-effective.
The reason why general large models have been preferred is that they don't need any data collection and can be used right away, while building your own model has historically required significant amounts of training data, resulting in much higher upfront costs. This is not true anymore: fine-tuning is emerging as the mechanism for obtaining specialized models for specific tasks without requiring huge amounts of data (a few thousand examples are sufficient). Fine-tuning enables any organization to have their own specialized GPT without breaking the bank.
Advantages of commercial LLMs
Ready to use right away.
Can be used for multiple applications with varying degrees of success.
No training data required.
No upfront training costs.
Concerns related to commercial LLMs
High inference costs.
High latency.
Limited throughput.
No ownership of the models.
Lack of transparency and data privacy.
Fine-tuned models outperform general models
While the shortcomings of large general models may be tolerable for prototypes and experimentation, they quickly become unsustainable as applications reach production volumes. This dilemma leaves practitioners with limited choices: go back to creating models from scratch–which requires an often prohibitive amount of data and compute resources–or leverage techniques to fine-tune models for task-specific applications.
While headlines have often focused on the latest large language models (LLMs) with ever more parameters, the open-source community has demonstrated the potential of collaboration in closing the performance gap. Models like Llama-v2, Stable Diffusion and Mistral, along with other LLMs, have made powerful capabilities widely accessible.
Moreover, new fine-tuning recipes made it possible to train smaller models with performance competitive with commercial LLMs using orders of magnitude more parameters, like in the case of Alpaca 7B: a highly performant instruction-following language model created by Stanford researchers by fine-tuning LLaMA 7B-13B on just 52K task-specific instructions automatically generated using larger LLMs. A similar recipe was used to produce Vicuna, which got even closer results to larger models. More recent research (LIMA) has shown that fine-tuning is a viable solution with just 1000 examples of high quality data.
It is now well understood that commercial LLMs are not as performant as fine-tuned models on the majority of the tasks: as shown by this recent survey, ChatGPT underperforms fine-tuned baselines in 77.5% of tasks from 19 academic papers detailing 151 tasks and the author concluded that “vanilla ChatGPT will be used as a quick prototype for some applications, but it will be replaced by a fine-tuned model (often smaller, for economical reasons) for most production-ready solutions.”
Moreover, the best practices for fine-tuning open-source LLMs are now made accessible to developers by tools like Ludwig.ai, our open source declarative ML framework. Ludwig makes fine-tuning easy through a straightforward configuration file and optimizes fine-tuning on readily available hardware like T4 GPUS (those provided for free in Google Colab).

Fine-tuning has become a strong option among the different approaches to building AI, which vary depending on the task details and data available:
When vast amounts of data are available (billions of tokens), specialized models trained from scratch are the best option. However, this approach is extremely costly and time-consuming, taking days to complete on expensive GPU clusters that strain budget and capacity.
In cases where organizations have medium to large data volumes, typically ranging from 1,000 to 1 million data points, fine-tuning is the best and most cost-effective choice and can be accomplished within hours without breaking the bank.
For scenarios with limited data, typically fewer than 100 data points, in-context learning and retrieval-augmented generation techniques are usually the most effective strategy.
In situations where data is extremely scarce or nearly non-existent, relying on a general model becomes the only viable solution.
Over time, organizations without available data that start using general models will start collecting data. The tasks they perform will shift toward the left side of the distribution in figure 1, making fine-tuning the most attractive option quickly. Simultaneously, new general models will become able to solve new tasks, extending the right end of the distribution in figure 1.
The enterprises in the best position will be those that adopt tools capable of supporting techniques required across the entire task distribution, but general models, even when used with in-context learning, despite reducing training costs to virtually zero at the beginning, come with higher inference expenses. In contrast, fine-tuned models are not only cost-effective to train but also economical to deploy, making them the most financially efficient choice with the highest return on investment and lowest total cost of ownership.
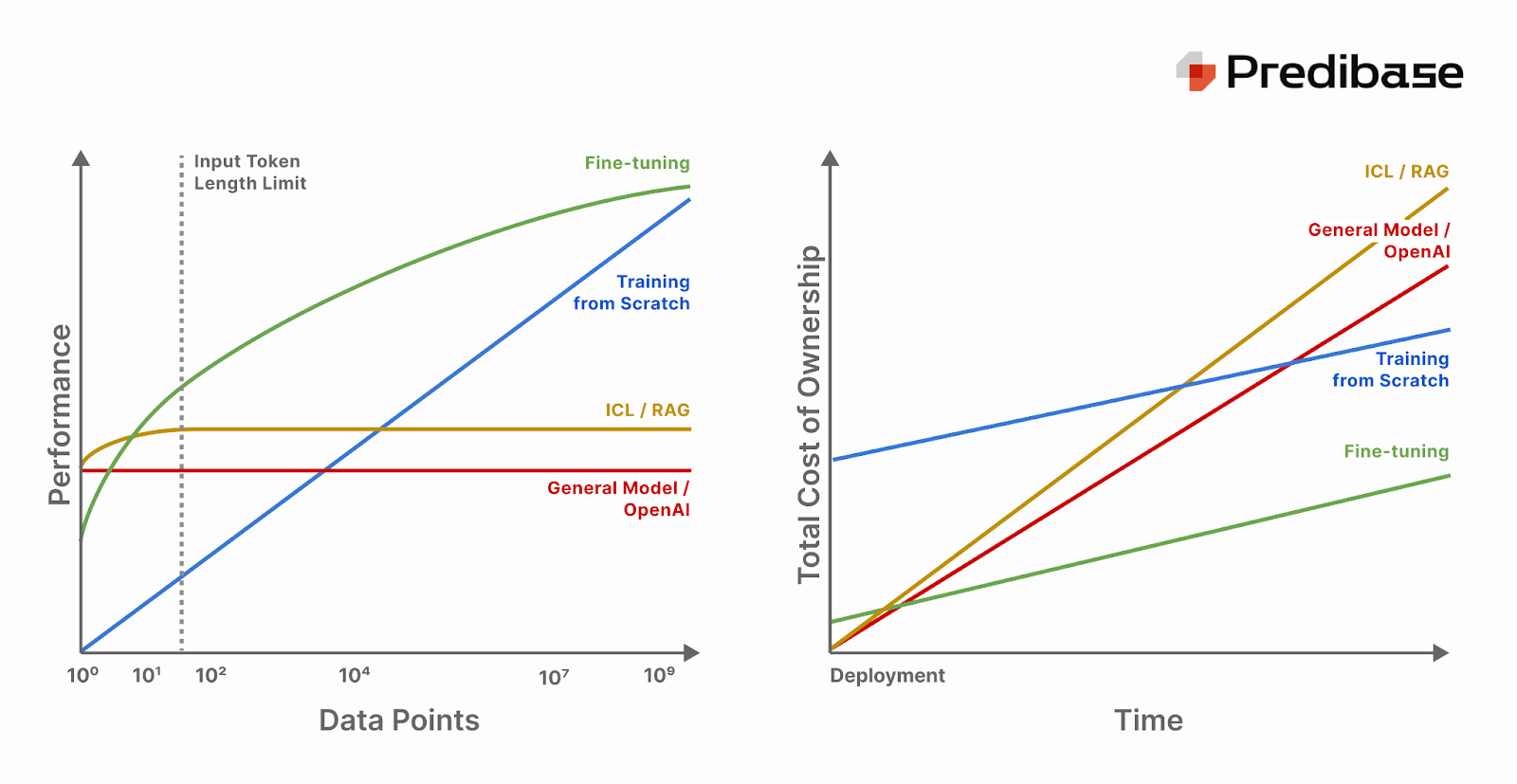
Left chart: While a smaller open-source model may not meet performance requirements out of the box, fine-tuning it with even small amounts of high-quality data (10^4 data points) improves performance dramatically and makes it competitive even with models trained from scratch on orders of magnitude more data (10^7 data points).
Right chart: While training from scratch has a large upfront cost, a general model like GPT-4 is ready to use out of the box but is expensive to use at scale. Fine-tuned open-source models are incredibly economical with very low upfront costs. If you deploy using LoRAX rather than giving every fine-tuned model its own set of dedicated GPU resources, you can substantially reduce total cost of ownership compared to a model trained from scratch or a commercial LLM.
A new model development lifecycle
In the past 15 years, a significant initial effort was required for data collection and labeling before even considering training a machine learning model. Now we are observing our customers adopting a new process. Teams start by using a general model – either commercial APIs or open source – to build a first prototype version of an AI product. This shift significantly reduces the barriers to entry and the cold start problem and enables quick validation. The use of the prototype generates data that is collected and can be used to fine-tune specialized models. The process then repeats by using the specialized model, improving performance with each iteration.

General models serve as the starting point for a v0 product, essentially igniting the engine that drives the iterative refinement of specialized AI models. By adopting this process, engineers enjoy the best of both worlds: they can quickly realize value through general AI and then optimize for cost, accuracy, and speed through specialized models. This optimization occurs only when the AI product has already demonstrated value.
From the ongoing adoption of this process, we derive a clear vision of a near future where specialized, fine-tuned LLMs that are tailored to specific tasks will be ubiquitous, unlocking new levels of efficiency, speed, and cost-effectiveness for all companies developing AI products.
How Predibase makes this AI development lifecycle easy
Predibase provides open source AI infrastructure for developers built on top of the popular open source framework Ludwig. The Predibase platform allows developers to efficiently fine-tune and serve open source LLMs on scalable managed infrastructure with just a few lines of code.
Models are served through a dynamic serving infrastructure that adjusts automatically to match the requirements of your production environment. It allows to serve numerous fine-tuned LLMs simultaneously, leading to more than a 100x reduction in costs compared to dedicated deployments and you can load and query these models in a matter of seconds.
Try Predibase for free to start fine-tuning and serving open source LLMs for your tasks.