
📝 Guest Post: Meet LoRAX: The Open Source System that Serves 1000s of Fine-Tuned LLMs on a Single GPU*
In this guest post, Travis Addair, CTO and Co-founder of Predibase, introduces LoRAX, their open-sourced solution to the challenges of serving fine-tuned LLMs. He provides an in-depth exploration of LoRAX's inner workings and explains how you can begin utilizing LoRAX in your projects.
Building with large language models (LLMs) is at the top of every developer’s to-do list and teams that have progressed beyond simple experimentation are quickly realizing that smaller open-source LLMs like LLaMA-2 outperform costly general-purpose commercial models like GPT-4 when fine-tuned for a specific task.
But even though these fine-tuned models are relatively small compared to GPT-4, existing LLM inference systems require each model to be hosted on its own dedicated GPU hardware. This can quickly add up to tens of thousands of dollars per month in cloud costs for just a handful of fine-tuned models. In contrast, one of the most popular commercial LLM APIs – OpenAI’s gpt-3.5-turbo – charges just $6 per million tokens for fine-tuned models. The future is faster, cheaper, fine-tuned open source models, but to get there, the cost to serve such models must become competitive with commercial APIs.
LoRAX (or LoRA eXchange) was created by Predibase to eliminate the cost barrier to serving fine-tuned models. Unlike existing LLM inference solutions, LoRAX is optimized for productionizing many fine-tuned models using a single set of GPU resources. Leveraging state-of-the-art optimizations from the AI research community, LoRAX allows users to pack upwards of 1000 fine-tuned LLMs into a single deployment, dramatically reducing serving costs.

LoRAX is open-source and free to use commercially under the Apache 2.0 license. It comes batteries-included with pre-built Docker images, Helm charts for deploying on Kubernetes, and numerous optimizations including continuous batching, Paged Attention v2, Flash Attention v2, SGMV multi-adapter fusion, asynchronous adapter prefetching and offload, and support for quantization techniques including bitsandbytes and GPT-Q.

Fine-Tuning and Serving LLMs with LoRA
The conventional approach to fine-tuning a deep neural network is to update all the parameters of the model as a continuation of the training process. For LLMs with billions of parameters, this requires a massive amount of GPU memory (every trainable parameter amounts to about 4x additional overhead to fine-tune it) and storage waste (tens of gigabytes per model checkpoint).
To make fine-tuning less resource-hungry, parameter-efficient fine-tuning techniques like Low Rank Adaptation (LoRA) introduce adapters consisting of a small number of new parameters that are trained, while the original model parameters remain frozen. LoRA achieves performance comparable to full fine-tuning with much less overhead. At serving time, both the original model parameters and the new adapter parameters are loaded together as a single deployment.

Treating the base model and the adapter as a single deployable entity makes sense when you only have a single fine-tuned model. But as soon as you deploy an additional fine-tuned model using the same base model, the problem becomes clear: the majority of the GPU resources are being allocated to serving additional copies of the same base model parameters for every fine-tuned model! The part of the deployment that is unique to the fine-tuned model – the adapter weights – accounts for less than 1% of the total parameters, meaning many of these adapters could fit within the GPU memory capacity in most cases.

This all raises the question: what if we could pack multiple fine-tuned models into a single deployment by reusing the common base model parameters?
Introducing LoRA eXchange (LoRAX)
LoRA Exchange (LoRAX) is a new approach to LLM serving infrastructure specifically designed for serving many fine-tuned models at once using a shared set of GPU resources. Compared with conventional dedicated LLM deployments, LoRAX consists of three novel components:
Dynamic Adapter Loader, allowing each set of fine-tuned LoRA weights to be loaded from storage just-in-time as requests come in at runtime, without blocking concurrent requests.
Heterogeneous Continuous Batching, extending the popular continuous batching paradigm to pack requests for different adapters together into the same batch, using optimized SGMV CUDA kernels to keep latency and throughput nearly constant with the number of concurrent adapters.
Adapter Exchange Scheduler, a fair scheduling system that asynchronously prefetches and offloads adapters between GPU and CPU memory, and chooses which requests to batch together to optimize the aggregate throughput of the system.
When a request is sent to LoRAX for inference, the adapter will begin downloading in the background immediately and load the weights into host (CPU) memory. Once the scheduler decides the adapter is eligible to begin serving its requests, the weights will be prefetched onto the GPU, and once they’ve been fully loaded into the GPU, the scheduler will start incorporating requests from the newly loaded adapter into the continuously updated batch sent for decoding.

Once the adapter’s requests are in the batch and being sent for decoding, LoRAX ensures that only the single associated adapter is applied to each row of the batch using a technique developed by researchers at University of Washington and Duke University called Segmented Gather Matrix Vector multiplication (SGMV).
Using SGMV, we observe that even with 128 concurrent adapters per batch, LoRAX maintains near constant throughput and latency scaling.
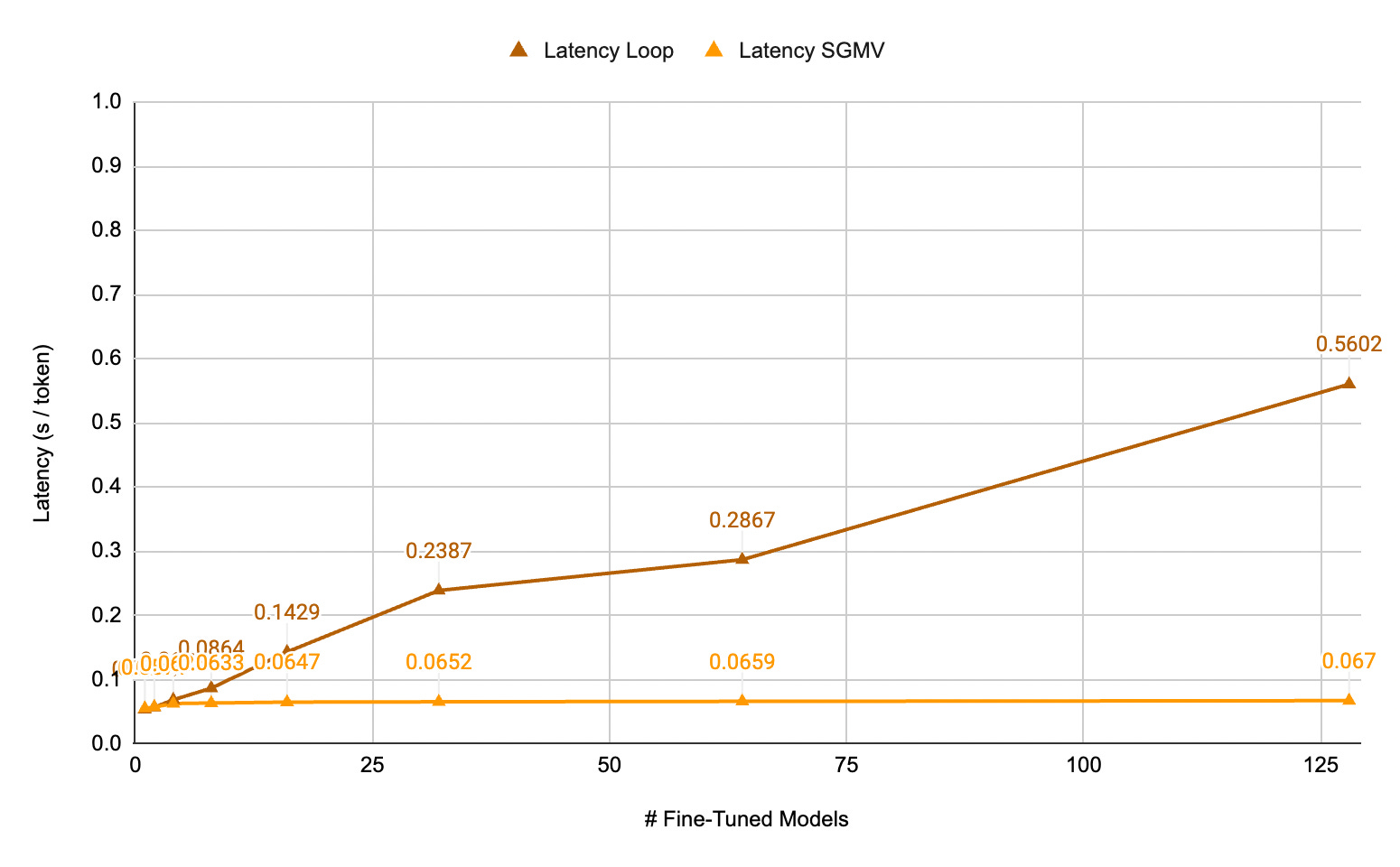
In cases where LoRA ranks differ between rows within a batch, LoRAX is able to fallback to a simpler loop-based approach that applies a mask to the output of each adapter to zero its contribution to rows associated with a different adapter.

We compare this worst-case scenario with respect to throughput below using a baseline we call the “break even threshold”, which is the throughput scaling at which it would be more cost effective to spin up a dedicated deployment per adapter. As shown, even at 128 concurrent adapters all with different ranks, LoRAX’s worst case throughput sits well above the break even threshold.

After a configurable amount of time, if there are other adapters waiting to be loaded onto GPU and processed, the scheduler will begin offloading the adapter so that it may be exchanged for another. This ensures that LoRAX is able to scale to thousands of adapters, well beyond the limit of how many adapters can fit on a single GPU.
Getting Started with LoRAX
LoRAX ships pre-built Docker images that include optimized CUDA kernels for fast GPU accelerated inference, including Flash Attention v2, Paged Attention, and SGMV.
LoRAX can be launched serving a Llama or Mistral base model using a single command:
docker run --rm --runtime=nvidia \
-e PORT="8080" \
-p 8080:8080 \
ghcr.io/predibase/lorax:latest \
--model-id mistralai/Mistral-7B-Instruct-v0.1
-e PORT="8080" \
-p 8080:8080 \
ghcr.io/predibase/lorax:latest \
--model-id mistralai/Mistral-7B-Instruct-v0.1
LoRAX supports a REST API compatible with HuggingFace’s text-generation-inference (TGI) for text prompting:
curl -X POST http://localhost:8080/generate -H "Content-Type: application/json" -d '{"inputs": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"}'
An individual fine-tuned LoRA adapter can be used in the request with a single additional parameter, adapter_id:
curl -X POST http://localhost:8080/generate -H "Content-Type: application/json" -d '{"inputs": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "parameters": {"adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"}}'
LoRAX also includes a Python client that works similarly:
adapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
# Synchronous
print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text)
print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text)
# Streaming
text = ""
for response in client.generate_stream(prompt, max_new_tokens=64, adapter_id=adapter_id):
if not response.token.special:
text += response.token.text
print(text)
text = ""
for response in client.generate_stream(prompt, max_new_tokens=64, adapter_id=adapter_id):
if not response.token.special:
text += response.token.text
print(text)
For users looking to deploy on Kubernetes, LoRAX ships with ready to use Helm charts:
helm repo add lorax https://predibase.github.io/lorax/
helm install my-lorax lorax/lorax --version 0.1.0
Once deployed, LoRAX on Kubernetes can be interacted with the same REST or Python APIs by sending requests to the newly created Service resource.
Fine-Tune and Serve with LoRAX in Predibase
Even with LoRAX and other open source tools, building a scalable, high availability fine-tuning and serving platform with access to high end GPU resources can be a challenge. For users who want to fine-tune and serve LLMs and other open source models without building an entire platform and GPU cluster from scratch, check out Predibase.

Predibase provides a unified infrastructure for building and serving fine-tuned LLMs specialized to your tasks. The platform has open-source at its core, building on the open-source Ludwig framework originally developed at Uber AI for fine-tuning custom adapters that can be served on managed LoRAX deployments. For Predibase, LoRAX is the secret sauce that allows our users to host unlimited fine-tuned models for the same price as prompting the base model.
Predibase builds on the foundations of Ludwig and LoRAX to abstract away the complexity of managing a production LLM platform. The platform automatically determines the right compute resources needed for your training and serving jobs, optimizes resource utilization to prevent OOMs and other failure events, and orchestrates the entire lifecycle of your jobs with reliability, auto-scaling, and fault tolerance out of the box.
Sign up for our 2-week free trial and start fine-tuning and serving LLMs including Llama 2, Mistral, and Zephyr for free.
Join the LoRAX Community
Ultimately, the success of an open-source project hinges on the vibrancy of their community, and LoRAX is no different. In the coming months, we’ll be releasing more tutorials, building new features, and hosting community events. In the meantime, check out the LoRAX GitHub and Discord community to connect with the community and contribute to the project!
Here is the discord community link: https://discord.com/invite/H4k4FxEUnm
I tried to join discord community but got 'invalid input' error but a question - would LoRAX work on Macbook pro M3?