
📝 Guest Post: Evaluating LLM Applications*
To successfully build an AI application, evaluating the performance of large language models (LLMs) is crucial. Given the inherent novelty and complexities surrounding LLMs, this poses a unique challenge for most companies.
Peter Hayes, who holds a PhD in Machine Learning from University College London, is one of the world’s leading experts on this topic. As CTO of Humanloop, Peter has assisted companies such as Duolingo, Gusto, and Vanta in solving LLM evaluation challenges for AI applications with millions of daily users.
Today, Peter shares his insights on LLM evaluations. In this 5-minute read, you will learn how to apply traditional software evaluation techniques to AI, understand the different types of evaluations and when to use them, and see what the lifecycle of evaluating LLM applications looks like at the frontier of Generative AI.
This post is a shortened version of Peter’s original blog, titled 'Evaluating LLM Applications'.

Take lessons from traditional software
A large proportion of teams now building great products with LLMs aren't experienced ML practitioners. Conveniently many of the goals and best practices from software development are broadly still relevant when thinking about LLM evals.
Automation and continuous integration is still the goal
Competent teams will traditionally set up robust test suites that are run automatically against every system change before deploying to production. This is a key aspect of continuous integration (CI) and is done to protect against regressions and ensure the system is working as the engineers expect. Test suites are generally made up of 3 canonical types of tests: unit, integration and end-to-end.

Typical makeup of a test suite in software development CI. Unit tests tend to be the hardest to emulate for LLMs.
Unit - very numerous, target a specific atom of code and are fast to run.
Integration - less numerous, cover multiple chunks of code, are slower to run than unit tests and may require mocking external services.
End-to-end - emulate the experience of an end UI user or API caller; they are slow to run and oftentimes need to interact with a live version of the system.
The most effective mix of test types for a given system often sparks debate. Yet, the role of automated testing as part of the deployment lifecycle, alongside the various trade-offs between complexity and speed, remain valuable considerations when working with LLMs.
Types of evaluation can vary significantly
When evaluating one or more components of an LLM block, different types of evaluations are appropriate depending on your goals, the complexity of the task and available resources. Having good coverage over the components that are likely to have an impact over the overall quality of the system is important.
These different types can be roughly characterized by the return type and the source of, as well as the criteria for, the judgment required.
Judgment return types are best kept simple
The most common judgment return types are familiar from traditional data science and machine learning frameworks. From simple to more complex:
Binary - involves a yes/no, true/false, or pass/fail judgment based on some criteria.
Categorical - involves more than two categories; for exampling adding an abstain or maybe option to a binary judgment.
Ranking - the relative quality of output from different samples or variations of the model are being ranked from best to worst based on some criteria. Preference based judgments are often used in evaluating the quality of a ranking.
Numerical - involves a score, a percentage, or any other kind of numeric rating.
Text - a simple comment or a more detailed critique. Often used when a more nuanced or detailed evaluation of the model's output is required.
Multi-task - combines multiple types of judgment simultaneously. For example, a model's output could be evaluated using both a binary rating and a free-form text explanation.
Simple individual judgments can be easily aggregated across a dataset of multiple examples using well known metrics. For example, for classification problems, precision, recall and F1 are typical choices. For rankings, there are metrics like NDCG, Elo ratings and Kendall's Tau. For numerical judgments there are variations of the Bleu score.
I find that in practice binary and categorical types generally cover the majority of use cases. They have the added benefit of being the most straight forward to source reliably. The more complex the judgment type, the more potential for ambiguity there is and the harder it becomes to make inferences.
Model sourced judgments are increasingly promising
Sourcing judgments is an area where there are new and evolving patterns around foundation models like LLMs. At Humanloop, we've standardised around the following canonical sources:
Heuristic/Code - using simple deterministic rules based judgments against attributes like cost, token usage, latency, regex rules on the output, etc. These are generally fast and cheap to run at scale.
Model (or 'AI') - using other foundation models to provide judgments on the output of the component. This allows for more qualitative and nuanced judgments for a fraction of the cost of human judgments.
Human - getting gold standard judgments from either end users of your application, or internal domain experts. This can be the most expensive and slowest option, but also the most reliable.
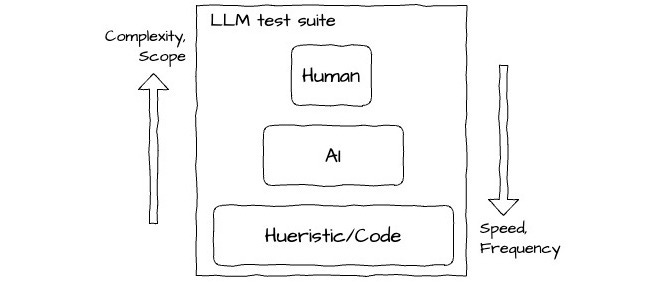
Model judgments in particular are increasingly promising and an active research area. The paper Judging LLM-as-a-Judge demonstrates that an appropriately prompted GPT-4 model achieves over 80% agreement with human judgments when rating LLM model responses to questions on a scale of 1-10; that's equivalent to the levels of agreement between humans.
I believe teams should consider shifting more of their human judgment efforts up a level to focus on helping improve model evaluators. This will ultimately lead to a more scalable, repeatable and cost-effective evaluation process. As well as one where the human expertise can be more targeted on the most important high-value scenarios.
Different stages of evaluation are necessary
Different stages of the app development lifecycle will have different evaluation needs. I've found this lifecycle to naturally still consist of some sort of planning and scoping exercise, followed by cycles of development, deployment and monitoring.
These cycles are then repeated during the lifetime of the LLM app in order to intervene and improve performance. The stronger the teams, the more agile and continuous this process tends to be.
Development here will include both the typical app development; orchestrating your LLM blocks in code, setting up your UIs, etc, as well more LLM specific interventions and experimentation; including prompt engineering, context tweaking, tool integration updates and fine-tuning - to name a few. Both the choices and quality of interventions to optimize your LLM performance are much improved if the right evaluation stages are in place. It facilitates a more data-driven, systematic approach.
From my experience there are 3 complementary stages of evaluation that are the give the highest ROI in supporting rapid iteration cycles of the LLM block-related interventions:
Interactive - it's useful to have an interactive playground-like editor environment that allows rapid experimentation with components of the model and provides immediate evaluator feedback. This usually works best on a relatively small number of scenarios. This allows teams (both technical and non-technical) to quickly explore the design space of the LLM app and get an informal sense of what works well.
Batch offline - benchmarking or regression testing the most promising variations over a larger curated set of scenarios to provide a more systematic evaluation. Ideally a range of different evaluators for different components of the app can contribute to this stage, some comparing against gold standard expected results for the task. This can fit naturally into existing CI processes.
Monitoring online - post-deployment, real user interactions can be evaluated continuously to monitor the performance of the model. This process can drive alerts, gather additional scenarios for offline evaluations and inform when to make further interventions. Staging deployments through internal environments, or beta testing with selected cohorts of users first, are usually super valuable.
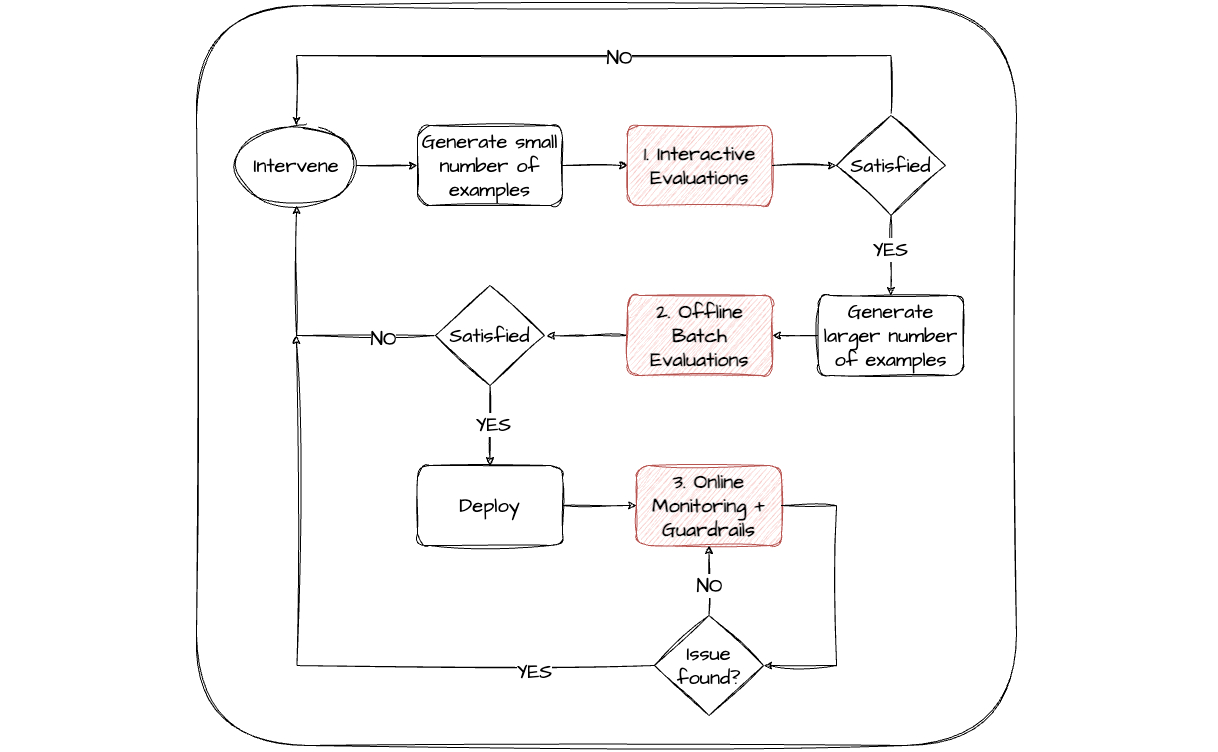
It's usually necessary to co-evolve to some degree the evaluation framework alongside the app development as more data becomes available and requirements are clarified. The ability to easily version control and share across stages and teams both the evaluators and the configuration of your app can significantly improve the efficiency of this process.
At Humanloop, we’ve developed a platform for enterprises to evaluate LLM applications at each step of the product development journey.
To read the full blog on Evaluating LLM Applications, or learn more about how help enterprises reliably put LLMs in production, you can visit our website.