
📝 Guest post: Elemeta: Metafeature extraction for unstructured data*

In this guest post, Lior Durahly, data & ML engineer @Superwise, introduces Elemeta, a brand new open-source library, currently in beta, for metafeature extraction from unstructured data.
What is Elemeta
With more and more models style DALLᐧE and ChatGPT hitting the shelves, we've reached incredible capabilities and results, fundamentally changing our ability to tap into and leverage unstructured data in machine learning. With that said, the general architectural understanding and intuition into how these models make decisions is vague at best, much less interpretable. So how can we as practitioners leverage NLP and vision while enjoying similar monitoring, interpretability, and explainability available to their tabular counterparts?
This is where Elemeta comes in! We're excited to open source the first version of Elemeta (focused on NLP) that will allow you to extract metafeatures from unstructured data so you can explore, model, and monitor NLP use cases through enriched tabular representations. Let’s dive in.
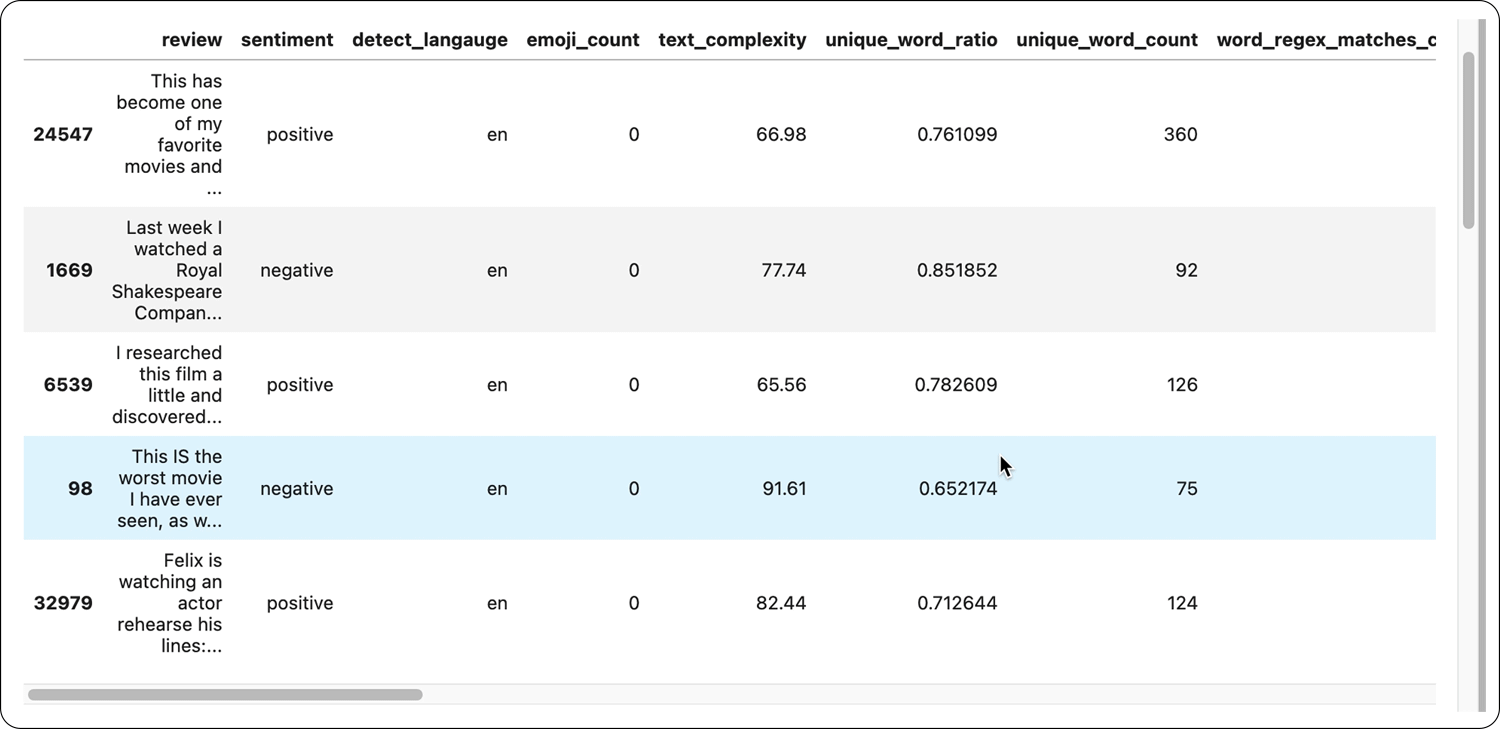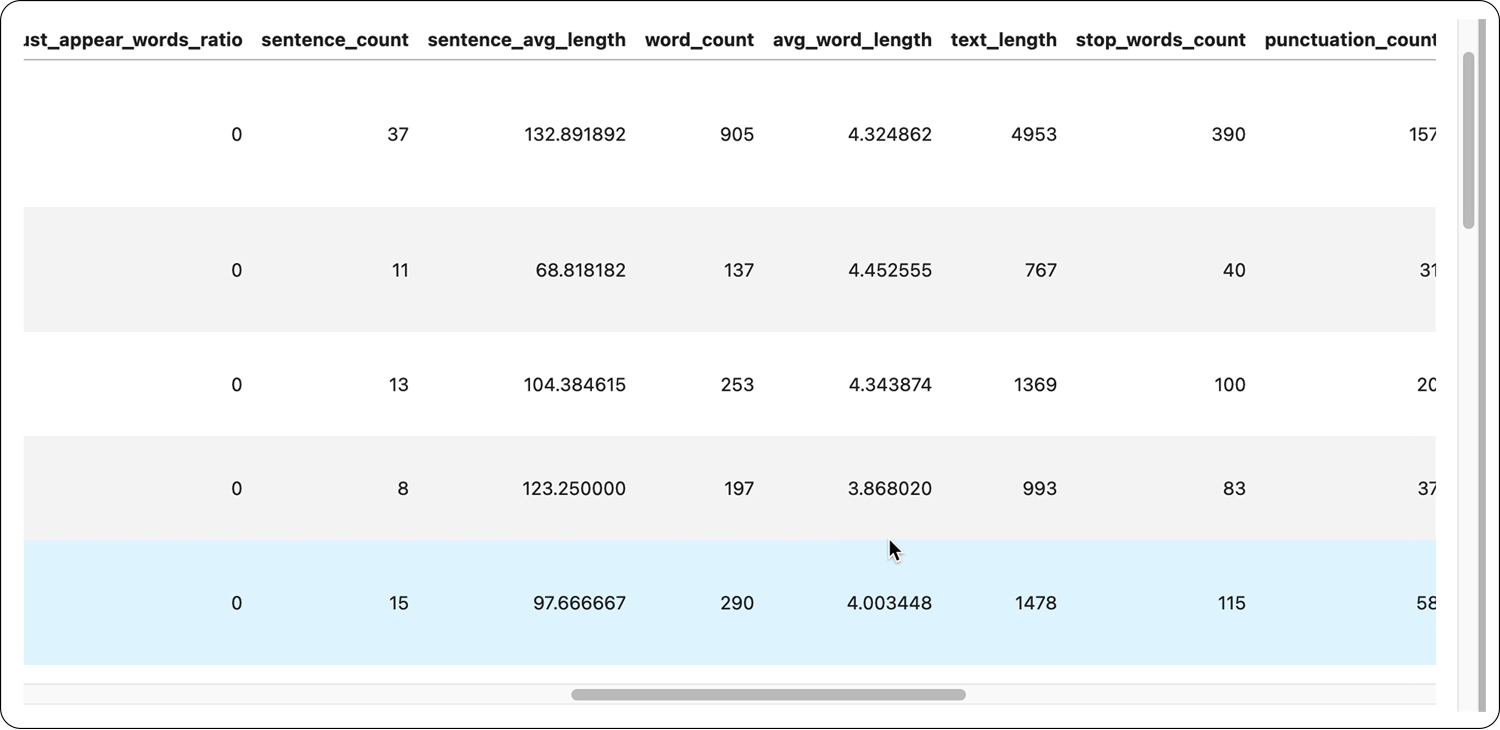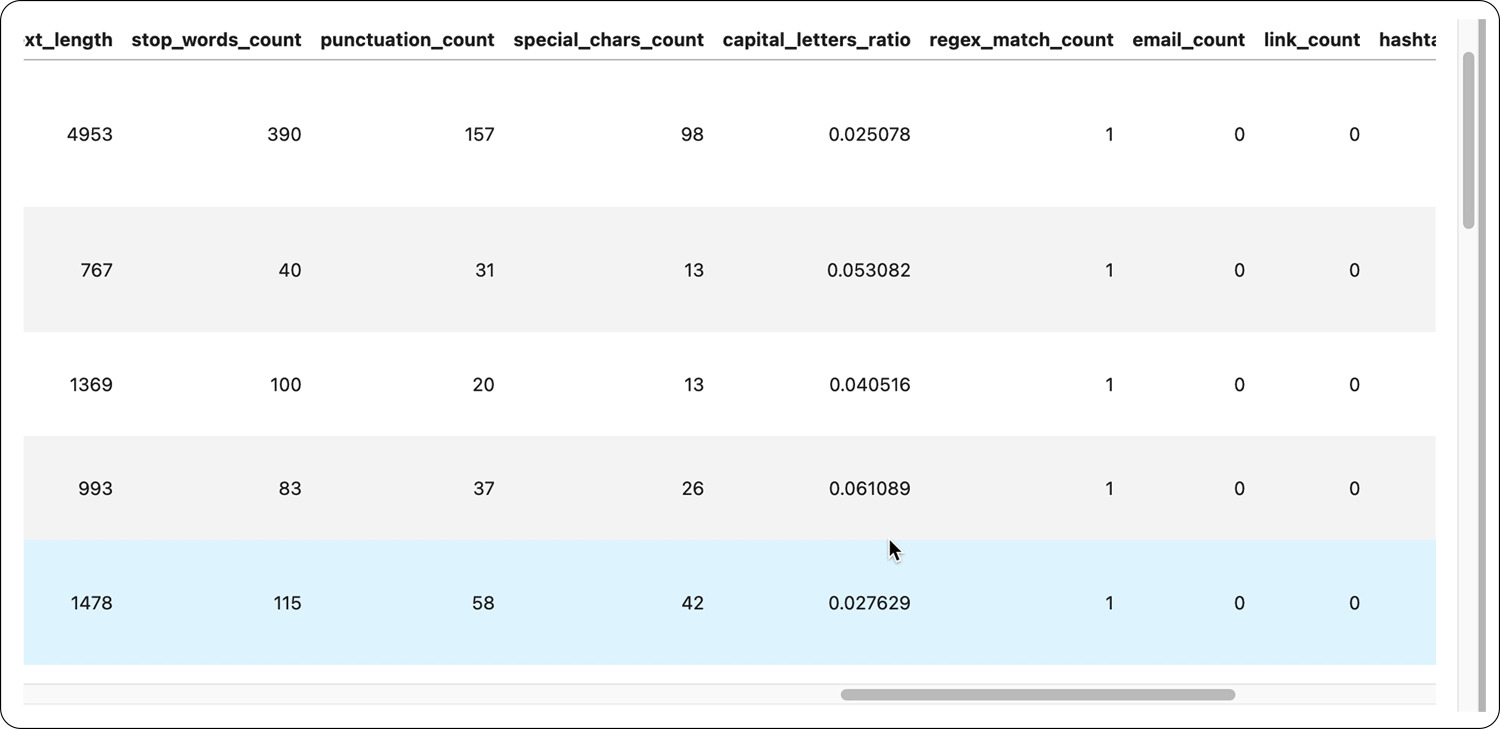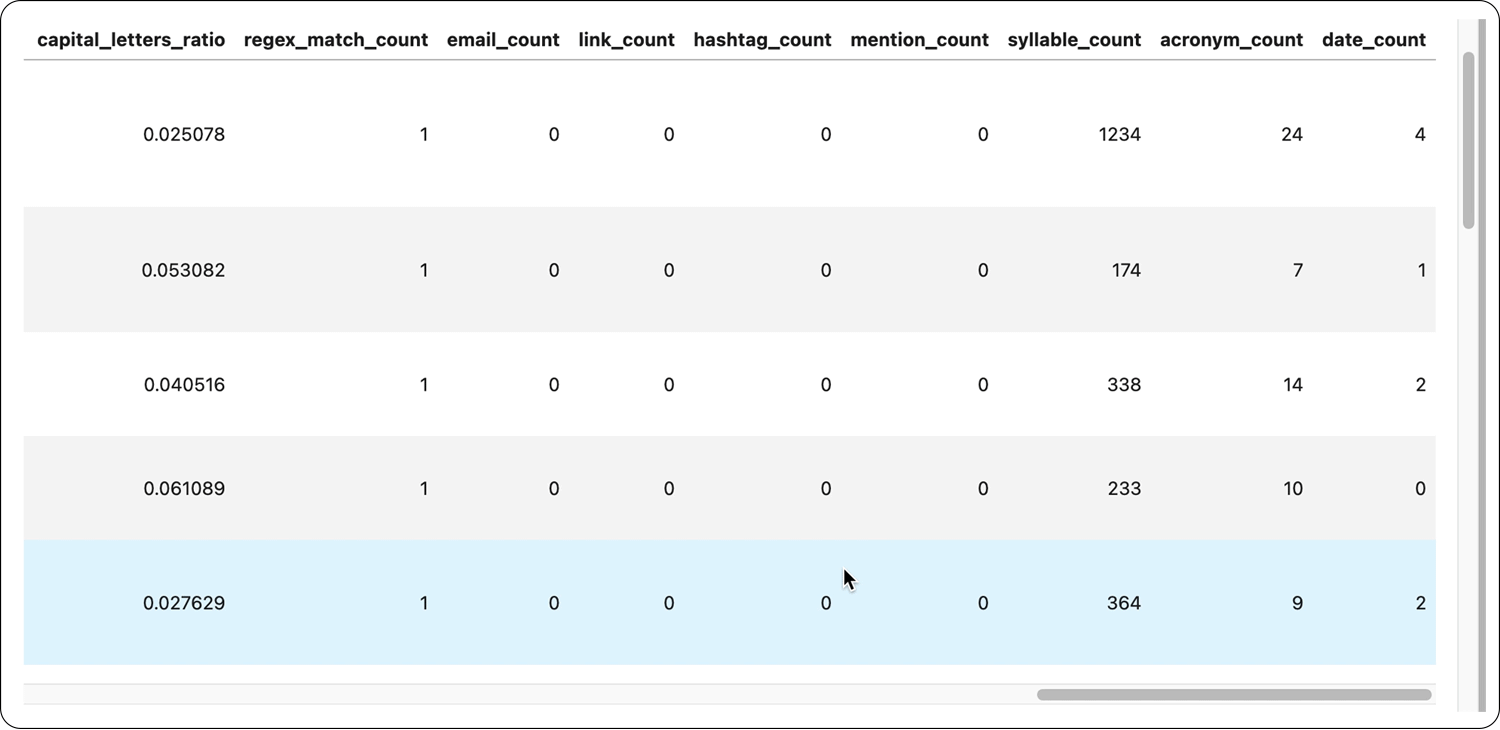
How to get started with Elemeta
To get started, simply run
pip install elemetaAnd use our getting started guide to get going.
From there, you'll find a set of colab notebooks that can help you dig deeper into the use cases and metafeatures and explore, model, and monitor NLP with Elemeta.
What can Elemeta be used for
We see Elemeta being applied to three core use cases: Exploratory Data Analysis (EDA), modeling, and model monitoring. But we've already heard of some additional potential use cases we didn't think about from beta testers, so don't stick to how we think Elemeta should be used; we're looking forward to seeing how the community puts it to use.
Exploratory Data Analysis (EDA) - extract useful metadata information on unstructured data to analyze, investigate, and summarize the main characteristics and employ data visualization methods.
Data and model monitoring - utilize structured ML monitoring techniques in addition to the typical latent embedding visualizations.
Feature extraction & modeling - engineer alternative features to be utilized in simpler models such as decision trees (Coming soon).
What are metafeatures
Elemeta already has an extensive set of out-of-the-box meta features such as SpecialCharsCount, EmojiCount, OutOfVocabularyCount, SentimentSubjectivity, etc. Additionally, you can create both low-level API extractors and custom metafeature extractors to fit your specific needs.
For example, if we want to create IsPalindromeExtractor, that will return if the given text is a palindrome:

And it will return:

Within Elemeta, metafeatures are currently split into two groups of metrics, statistical metrics and contextual metrics. Statistical metrics calculate technical values such as word length, word count, etc., and contextual metrics extract information regarding the context of the text. Statistical metrics are language agnostic, while contextual metrics currently support English and, to some extent, Indo-European languages (not tested).
What's on the roadmap for Elemeta
We've only just gotten started with Elemeta. And while there are already a few areas we know we're going to invest in, such as image extractors and additional language coverage, we've already had input from beta users on expansions that we didn't initially think about. That's precisely why we decided to shift Elemeta into a free, open-source project for the community. We want to know what metafeatures you need for your use cases and domains, and we are more than happy to accept community contributions!
So if you're working with NLP and need better exploratory data analysis, feature extraction, or monitoring, check out the Elemeta repo, take it for a spin with our colab notebooks, and if you star/follow the repo (show some ♥️), you'll get notified as soon as there's a new release.