
📝 Guest Post: Adala – The First Open Source Data-Labeling Agent*
In this guest post, Jimmy Whitaker, Data Scientist in Residence at Human Signal, introduces Adala, an Autonomous Data Labeling Agent framework that harmonizes AI's computational power with human judgment. It challenges conventional AI paradigms with dynamic agents that not only learn and adapt but also heavily rely on human-labeled data as a foundational bedrock. While the technology is still in its nascent stages, it aims to redefine data processing, model training, and the development of AI applications. It’s open-source and you can contribute to it!
Generative AI, exemplified by Large Language Models (LLMs) like ChatGPT, has moved beyond being a mere tool of natural-language chat to become an active collaborator in our day-to-day work. The concept of building agents with LLMs as their core runtime, or compute primitive, has emerged as a groundbreaking approach. These LLM-powered agents are not limited to generating well-articulated content but can be framed as potent general problem solvers.
Yet, one might assume that with such progress, the need for traditional tasks like data labeling would diminish, with agents and other generative AI techniques picking up that burden. However, these systems still need to deliver correct and consistent results. Consequently, LLM-based systems still need to be guided by human insight, especially when it comes to domain-specific, or more complex or nuanced tasks, to ensure the quality, reliability and robustness of AI models.
Enter Adala, a new Autonomous Data Labeling Agent framework. While it embodies the forefront of AI-driven data processing, Adala acknowledges and emphasizes the irreplaceable role of human-labeled data. It's not about replacing the human touch but harmonizing it with AI capabilities.
While the technology behind the open source Adala framework is still early, we’re excited for you to explore the project, provide feedback, and contribute back. We believe Adala has the potential to reshape the landscape of data processing, model training, fine-tuning, and building AI applications. To help understand why, let’s dive into the architecture and how you would use Adala to continuously train and fine-tune AI models.
Adala - A Data Labeling Agent Framework
At the heart of Adala lies a philosophy that challenges traditional AI paradigms. Unlike systems bound by static algorithms and predefined rules, Adala's agents are dynamic entities designed to learn, adapt, and evolve. This evolution is not random but is guided by experiences, data, and, most importantly, human feedback.
Iterative Acquisition and Refinement: Every interaction, every piece of feedback, and every new dataset adds a layer of knowledge to Adala's agents. They don't just acquire skills; they refine them, ensuring that their outputs align with the desired outcomes.
Versatility Across Tasks: Adala's agents are not limited to a single task. Whether it's data labeling, classification, summarization, or any other data processing task, they can adapt and deliver accurate results.
Human Feedback as the Guiding Light: While Adala's agents are autonomous, they are not isolated. They thrive on human feedback, using it as a beacon to guide their learning journey. This symbiotic relationship ensures that the agents' outputs are accurate and aligned with human values and expectations.

Agents are profoundly influenced by the context set for them. Typically, this context takes the shape of the prompts and skills provided to them. In the case of Adala, this context is primarily provided by a ground truth dataset. Such datasets, which can be created using platforms like Label Studio, serve as a foundational bedrock, guiding the agent's initial understanding and subsequent learning trajectories. As the environment evolves, perhaps by incorporating new ground truth data, agents further refine their skills, ensuring they remain relevant and accurate.
Let’s look at an example. For a simple classification problem, we may create an agent with a “classification skill” to perform subjectivity detection. Initially, this skill may look as simple as defining instructions to retrieve labels from an LLM.
skills=ClassificationSkill(
name='subjectivity_detection',
description='Understanding subjective and objective statements from text.',
instructions='Classify a product review as either expressing "Subjective" or "Objective" statements.',
labels=['Subjective', 'Objective'],
input_data_field='text'
)
This skill may be sufficient for simple tasks, but it will likely miss the nuance in more complex examples. At this point, we could manually incorporate techniques like Chain of thought or ReAct. But a better way is to ground the skill with a ground truth dataset.
During this process, the agent uses an evaluation stage to compute metrics for the ground truth data and automatically incorporates nuanced examples into the skill as a form of few-shot learning to improve the agent’s classification predictions. We can see an improved skill prompt learned from our ground truth data below.
subjectivity_detection
Identify if the provided product review is "Subjective" (expressing personal feelings, tastes, or opinions) or
"Objective" (based on factual information). Consider a statement as subjective if it reflects personal judgment or
preference, and as objective if it states verifiable facts or features.
Examples:
Input: Not loud enough and doesn't turn on like it should.
Output: Objective
Input: I personally think the sound quality is not up to the mark.
Output: Subjective
Input: The phone's battery lasts for 10 hours.
Output: Objective
Input: The mic is great.
Output: Subjective
Input: Will order from them again!
Output: Subjective
The key here is that we leverage human input to direct the agent’s learning process and constrain the agent’s direction. The agent's learning process is controlled and refined by incorporating human feedback. Human annotators can further enhance the data curated by the agent, focusing on predictions that demand greater discernment and feeding this refined data back into the agent's learning cycle.
The Building Blocks of Adala: Flexibility and Extensibility at its Core
The strength of Adala lies in its modular architecture. Whether you’re looking to process data, generate synthetic data, or curate multimodal datasets, Adala provides the tools and framework to make it happen. At the core of Adala are three fundamental components: the environment, the agent, and the runtime.
The Environment: Defined by Data
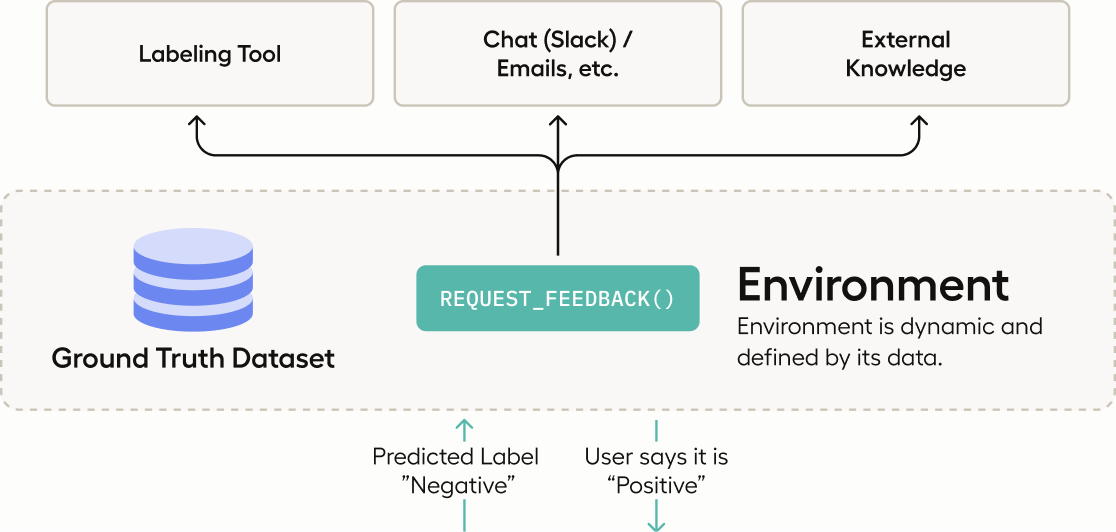
The environment in Adala is akin to the real-world context in which the agent operates. It supplies the essential data and sets the boundaries for the agent's operations. Crucially, this is the realm where human feedback is integrated, ensuring the agent operates with a clear and relevant context.
The Agent: The Heart of Adala

The agent is where the magic happens. It processes data, learns from it, and refines its actions based on environmental interactions.
A standout feature of Adala's agents is their capability to craft custom skills. For instance, a classification skill can assess a dataset, scrutinize ground truth data, and enhance its performance based on human feedback. The versatility of these skills means they can be expanded to handle complex tasks, from intricate data curation to integrating student-teacher architectures or even tools tailored for computer vision. Additionally, agents can be equipped with a memory component, enabling them to tackle more advanced tasks.
The Runtime: Powering Adala's Operations

The runtime, or the LLM where the code executes, is the engine that drives Adala. It's the platform where the agent's skills come to life, ensuring Adala's seamless and efficient operation. Today, Adala supports OpenAI, but we are actively working to support more runtimes and are also seeking contributions to expand the library of available runtimes. The runtimes are designed for adaptability, allowing for integrating new tools, plugins, and features. Fundamentally, Adala's runtime is crafted to effortlessly incorporate into existing workflows, ensuring a smooth fit within data processing pipelines.
Adala - Pioneering the Future of Human-AI Collaboration
The quest for efficiency and quality often comes with a hefty price tag. Traditional data processing methods, while effective, can be resource-intensive and costly. Adala’s vision is compelling: a future where AI doesn't replace humans but collaborates with them. A future where the computational prowess of AI agents and the nuanced understanding of humans come together in perfect harmony, ensuring outputs that are efficient, cost-effective, and of the highest quality.
The journey for Adala is just beginning. The potential of this technology is yet to be fully realized, and we can all contribute to shaping what’s possible. Explore Adala, and join us virtually on Nov 7th for a live demo and overview of Adala’s agent-based approach to data labeling.
So the labeling is assigned to AI responses? How does this interact with prompt engineering?