
📝 Guest post: 4 Types of ML Data Errors You Can Fix Right Now*
In this article, Galileo founding engineer Nikita Demir discusses common data errors that NLP teams run into and how Galileo helps fix these errors in minutes with a few lines of code. A very helpful read!
Introduction
Over the past year, we’ve seen an explosion of interest in improving ML data quality. While parts of the MLOps ecosystem have matured, ML data quality has been dramatically underserved.
In this article, we’ll walk you through four of the most prominent types of data errors and show you techniques for fixing them.
In the end, we’ll point out how your errors can be found and fixed in minutes with a tool like Galileo!
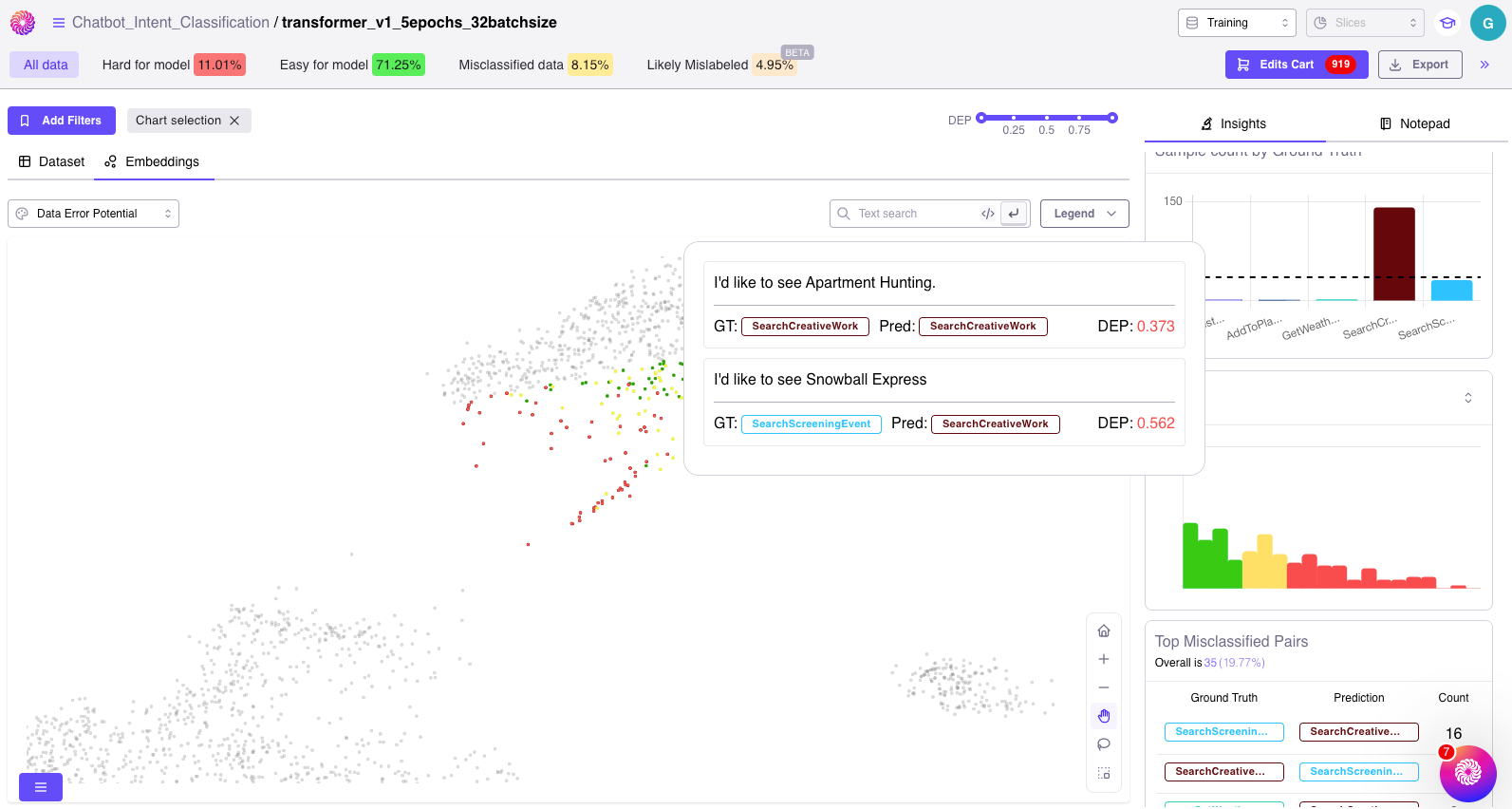
❗️ ML Data Error #1: Mislabels
The correctness of your ground truth labels can vary depending on how they were labeled. Most public datasets, including canonical benchmark ones, have been shown to have mislabeled samples. Although deep learning models can be robust to some random noise, labelers often make errors between specifically confusing classes: “cheetah” vs “leopard”, “SearchCreativeWork” and “SearchScreeningEvent”, “talk.religion.misc” and “soc.religion.christian”. Repeated errors are likely to degrade the model’s performance on confusing classes.
We’ve seen the industry mitigate these errors in a few painstaking ways:
Using multiple labelers for each sample and manually reviewing the ones with the most disagreement.
Reviewing the model’s misclassified samples.
Sorting by some ranking metric like self-confidence or margin and taking some percentage.
❗️ML Data Error #2: Class Overlap
Another common data error we see, especially for problems with many ground truth classes, is an overlap in the class definitions. Your dataset might have multiple classes that mean the same thing like “billing.refund” and “account.refund”, multiple classes that apply to the same input like “appointment.cancel” and “appointment.reschedule” for the input of “I would like to cancel and reschedule my appointment”, or unclear definitions for specific data cohorts.
Finding the problematic classes when there are 20+ classes in your dataset can be challenging and tedious, but that is also the scenario where the class overlap is most likely to occur. Try:
Ordering the model’s confusion matrix to see what classes might be most commonly confused with each other.
Scanning through the model’s misclassified samples ranked by margin to bring the most confusing samples to the top.
Ultimately, you will have to educate your labelers or change the classes by either merging them or creating new ones.
❗️ML Data Error #3: Imbalance
By itself having an imbalanced dataset might not be a problem, but often model performance can correlate with that imbalance. ML practitioners tend to be trained to look at class imbalance but often don’t consider imbalances in the inputs themselves. For example, if a training dataset has hundred subtle variants of “I need to repair my Jeep” but only one example of “I need to repair my Honda,” a model might not have enough signal to associate a Honda with a car and not a microwave, which would matter if your two classes are “repair.car” and “repair.microwave”. Similar imbalances in the test dataset can lead to misleadingly inflated accuracy numbers.
Detecting class or any other metadata column’s imbalance is pretty easy to do and should be a standard part of a practitioner’s workflow. However, detecting imbalances in the patterns of your data is generally pretty hard. Some things to try are:
Finding duplicate samples.
Similar to the above, but using embeddings and clustering to group similar patterns of samples together.
Once you detect imbalance, it can be reduced by downsampling frequent samples and increasing the number of less frequent samples through data augmentation or using embeddings to select similar samples from an unlabeled dataset and labeling.
❗️ML Data Error #4: Drift
A model deployed in production only knows to make predictions based on what you trained it on. As the real-world data “drifts”, the model’s predictions veer into uncharted territory. Covid, for example, broke facial recognition models with the usage of masks. New words enter our lexicon daily, and old terms can change their meanings drastically. This is especially problematic for datasets that are hand-curated.
Drift can be detected by looking for changes in the model’s predictions or the composition of production data. A mature ML workflow would send some of the drifted data to labelers and use the results in a retraining job.
⚡️ Better Data in Minutes
Data-centric techniques are not well documented or taught in the industry. Finding data errors is a very time-consuming process. It can feel like finding a needle in a haystack. Except, you have a ton of needles in a really large haystack of tens or hundreds of thousands of data samples.
We’ve built Galileo to take that pain away. We want to empower you to find and fix data errors in minutes instead of hours without worrying about the technical details. With Galileo, you can find likely mislabeled samples, samples with class overlap, drift in your real-world data, or you can use it to explore your data’s patterns through their embeddings!
Try it out yourself by signing up for free here.
We would love to discuss what you find in our Slack community.
Here’s to building better models, faster, with better data!
Team Galileo
(PS: we are hiring!)