

🗣🤖 Edge#88: How IBM Uses Weak Supervision to Bootstrap Chatbots and How You Can Do It Too With Snorkel Flow
🗣🤖 Edge#88: How IBM Uses Weak Supervision to Bootstrap Chatbots and How You Can Do It Too With Snorkel Flow
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. Become smarter about ML and AI.
Check the Quiz below: after ten quizzes, we choose the winner who gets the Premium subscription.
💥 What’s New in AI: How IBM Uses Weak Supervision to Bootstrap Chatbots and How You Can Do It Too With Snorkel Flow
Conversational agents and chatbots have been some of the most popular applications of deep learning techniques in the last few years. Despite its increasing popularity, building large-scale chatbots remains a very time-consuming process. In general, the paradigm for building conversational agents relies heavily on training classifiers to recognize specific text inputs. Almost without exception, the vast majority of popular chatbot frameworks such as Google Dialogflow, RASA, Azure Bot Services, and Watson Assistant are built on the premise of defining intents and building intent classifiers. Conceptually, an intent is a semantic construct that clearly identifies a purpose in the conversation. For instance, in a customer service chatbot scenario, phrases such as “I am having a technical issue” or “the system is failing” can be mapped to the intent Problem Report. Although effective, this process requires large training datasets which becomes a roadblock for most data science teams.
To address the limitations of the traditional approach, the data science community have turned their attention to weak supervision methods that can generate labels in large datasets and iterate on training data alongside model training. Research on weak supervision carried out at Stanford AI Lab became the main inspiration behind IBM Research’s paper “Bootstrapping Conversational Agents with Weak Supervision”. In this paper, they proposed an architecture that applies weak supervision methods to logs produced by chatbots in order to train intent classifiers in a cost-effective way. The proposed architecture soon became available in Snorkel Flow, an AI application development platform that uniquely supports programmatic labeling of training datasets. While the IBM Research paper provides a strong theoretical foundation for applying weak supervision methods in conversational agents, Snorkel Flow represents a practical implementation of these ideas that allow data scientists to incorporate those methods as part of their current machine learning pipelines.
What is Weak Supervision?
Conceptually, weak supervision belongs to the family of machine learning techniques that attempt to remove the dependencies from high-quality, large labeled datasets in order to effectively train models. However, different from other techniques, weak supervision does not attempt to achieve generalization using smaller datasets. Instead, weak supervision methods try to leverage higher level, lower-quality and noisier training datasets. The main thesis is that, when used correctly, noisy labels can still help improve the performance of a machine learning model. To illustrate this in the context of an example close to the research we are discussing today, imagine a chatbot that, in addition to being trained in a dataset of intent-classified records, can be regularly retrained using live conversations in order to improve its performance.
One of the main distinctions of weak supervision is that it complements noisy training datasets with inputs from subject matter experts (SMEs) in the form of heuristics, business rules, and external knowledge bases which can help enhance the effectiveness of the data. This element is one of the key distinctions between weak supervised models and other disciplines such as active learning, transfer learning, and semi-supervised learning.
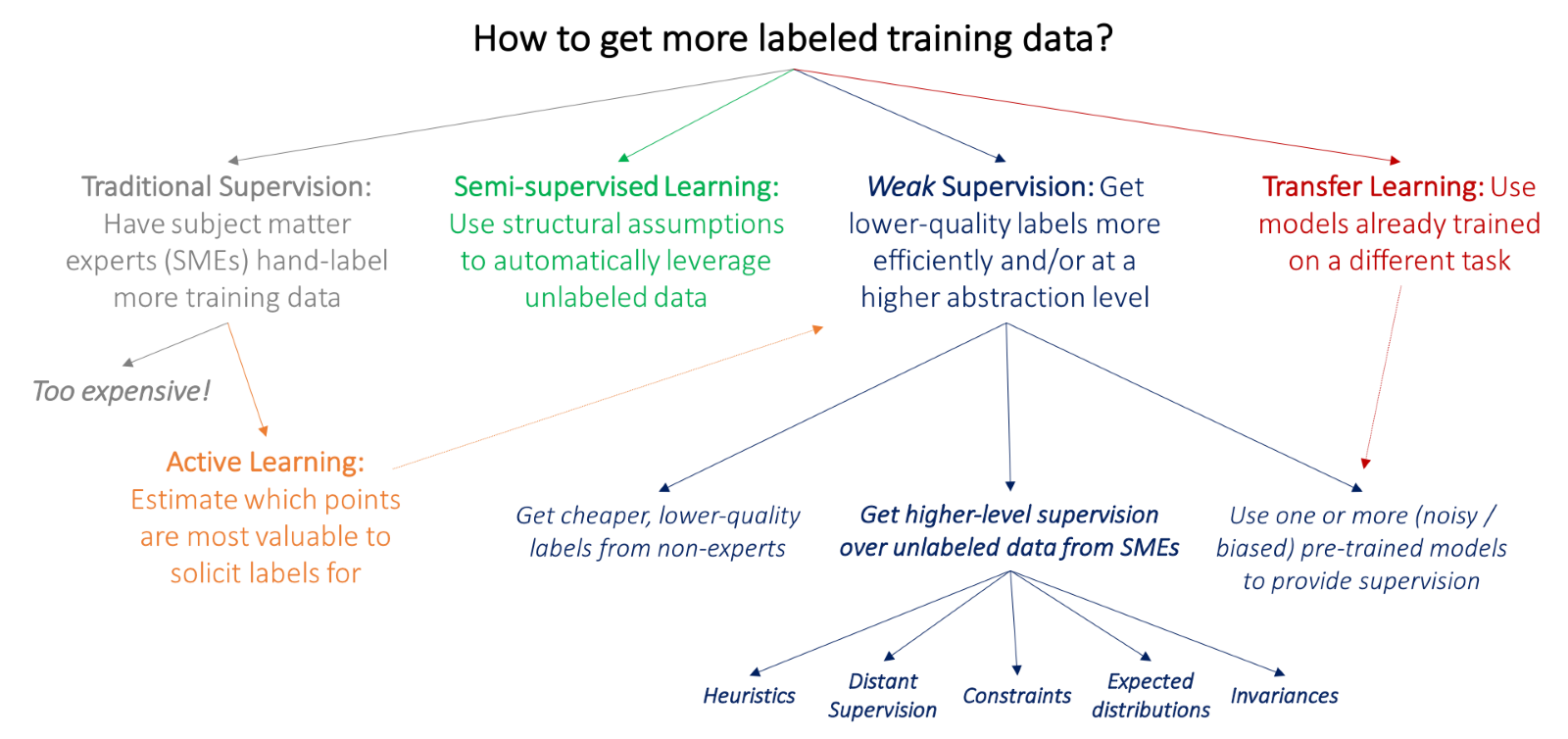
Image Credit: Stanford AI Lab
IBM’s SLP Architecture Conversational Agents
In the paper “Bootstrapping Conversational Agents with Weak Supervision”, IBM Research proposes a framework that uses weak supervision methods to enhance the training process of conversational agents. As outlined before, creating large datasets with intent labels to train conversational models is often cost-prohibited for data science teams. To address this challenge, IBM Research uses a weak supervised method frameworks search, label, and propagate (SLP) that bootstraps intent classification using existing chat logs.
IBM Research’s SLP framework works by defining labeling functions that operate against a subset of the chat logs dataset. You can think of these functions as mini-classifiers that all contribute to extract knowledge from noisy data. As the SLP name indicates, the labeling process is based on three fundamental steps:
Search: This phase uses a search engine to find relevant intent examples based on the chatbot logs. The idea is to select a set of candidate examples for a given intent that can be used to improve the training of the ongoing conversational agent. The first implementation of the SLP framework relies on Elasticsearch as the underlying search engine.
Label: After a set of candidate examples have been selected by the search process, a subset of the dataset is presented to SMEs for labeling. The user labels and simple “in” or “out” classification indicating whether the example belongs to the target class or not. The result of this process is used in the propagation phase. This input paired with search results is essentially heuristic rules. For instance, in the case of the Snorkel Framework, these heuristics are called labeling functions and can range from keyword matching to using a noisy model trained on a small number of examples to distance-based metrics on vector embeddings.
Propagate: Having the results of the SME classification, the propagate phase uses a generative model to expand those labels to the complete set of examples retrieved in the search process. After the propagation is complete, the result can be used to improve the training of the conversational agent.
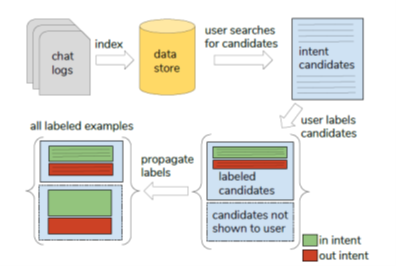
Image Credit: IBM
IBM Research’s SLP architecture is a clear example of weak supervision methods in action. The framework enhances the training of conversational agents by converting noisy labels into strong labels as part of the search-labeling process as well as by de-noising noisy labels during the propagation phase. IBM Research benchmarked the SLP approach against various label-only methods with outstanding results: improvement in accuracy from 0.507 without weak supervision to 0.963 with weak supervision.
If, like me, you are fascinated by IBM Research’s clever weak supervision approach, you might be wondering how you can apply it in real-world scenarios. While the SLP architecture seems very creative, its implementation also seems like a lot of work. One of the most complete solutions that addresses that challenge on the current machine learning market is Snorkel Flow, an enterprise-grade platform developed by the team behind the Snorkel framework.
A Quick Overview of Snorkel Flow
The challenges with creating high-quality training datasets are very real and not constrained to research efforts. In the last few years, a number of frameworks and platforms have emerged with the idea of automating the labeling process of training data. One of the most popular efforts in this area was developed at Stanford University’s AI Lab. The team published a highly popular open-source library of research code under the name The Snorkel Project as a proof of concept. This framework has been deployed at scale at some of the world’s largest organizations such as Google, Intel, and Apple. Given the increasing popularity and market validation of this approach, the project has evolved into a commercial platform known as Snorkel Flow. Snorkel AI, the company behind Snorkel Flow, has leveraged cutting-edge research on weak supervision and programmatic data labeling to create an end-to-end AI application development platform.
At a high level, the Snorkel Flow platform expands its capabilities across four fundamental areas of the MLOps lifecycle:
Training Data Creation: Snorkel Flow Data Studio allows data scientists to use programmatic functions to automate the labeling of training datasets. The label functions abstract heuristics, business rules as well as other contextual constructs that are relevant to the training of machine learning agents.
Training Data Management: Snorkel Flow Data Manager actively learns the efficacy of different labeling functions and integrates them as part of the training pipeline.
Model Training: Snorkel Flow Python SDK streamlines the training of machine learning models using different GPU and CPU computation frameworks. The training experience is compatible with popular frameworks such as TensorFlow or Scikit-learn.
Analysis and Monitoring: Snorkel Flow analyzes and monitors the performance of machine learning models identifying potential improvements to the labeling functions that can result in better generalization. Differently from other model monitoring toolsets, Snorkel Flows ties the efficiency of the model all the way back to the training processes.
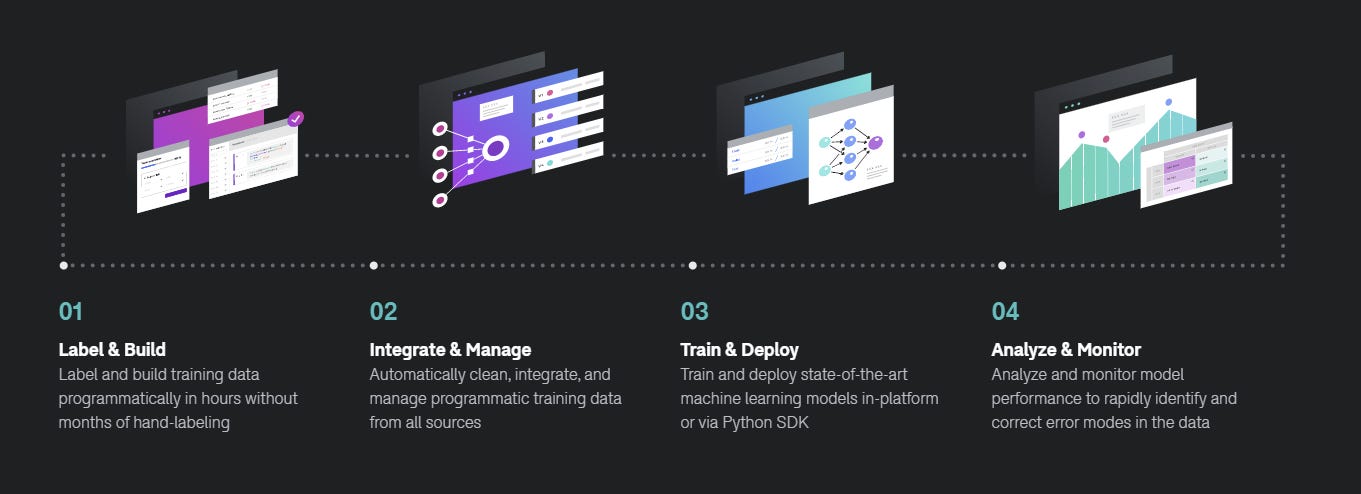
Image Credit: Snorkel AI
Snorkel Flow follows the typical playbook of enhancing an open-source framework with enterprise-grade capabilities. It seems to work really well. At the moment, Snorkel Flow is powering several production-ready systems for high-profile companies across diverse industries such as financial services, global telecommunications, insurance and biotech, and even government agencies. Furthermore, Snorkel Flow keeps advancing techniques such as weak supervision and other concepts outlined in IBM’s SLP architecture that are likely to play a role in the next decade of deep learning.
Conclusion
The dependencies in high-quality labeling datasets represent one of the major bottlenecks in the lifecycle of machine learning solutions. IBM Research’s SLP framework proves that novel approaches like weak supervision can address these limitations for conversational agents type of applications. An architecture based on weak supervision and programmatic data-labelings used to enhance the training of chatbots using noisy log data and improve model accuracy significantly. Snorkel Flow represents one of the most practical implementations of weak supervision and programmatic data labeling methods that is available to data science teams today.
🧠 The Quiz
Every ten quizzes we reward two random people. Participate! The question is the following:
What is the main idea of weakly supervised methods?