
⚪️⚪️🔵 Edge#84: Snorkel Flow – One of the Most Comprehensive ML Platforms on the Market
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. Become smarter about ML and AI.
Check the Quiz below: after ten quizzes, we choose the winner who gets the Premium subscription.
💥 What’s New in AI: Snorkel Flow is One of the Most Comprehensive Machine Learning Platforms on the Market
In the current machine learning universe ruled by supervised learning models, access to high-quality labeled datasets remains one of the biggest challenges. Most recent breakthroughs in deep learning have produced data-hungry architectures such as transformers and reinforcement learning techniques which require large volumes of labeled data to achieve any decent level of generalization. This challenge is even more prominent outside the big AI labs as most enterprises and startups lack the infrastructure to curate and produce high-quality datasets. To solve this training data bottleneck, the team at Snorkel AI has developed novel programmatic labeling techniques based on research carried out over the past five years at Stanford AI Lab. Last year, Snorkel AI introduced Snorkel Flow, one of the most comprehensive machine learning platforms that uniquely supports programmatic labeling. It radically changes the rest of the ML pipe so data scientists and developers can train models efficiently, improve performance iteratively, and deploy AI applications rapidly.
The goal of Snorkel Flow is simple: Streamline the lifecycle of machine learning models by transitioning from hand-labeled training to programmatically labeled training datasets. However, programmatic data labeling is just the starting point. By leveraging programmatic labeling, the Snorkel Flow platform makes the entire lifecycle of machine learning models from training to monitoring a lot more integrated. The beginnings of Snorkel Flow trace back to research efforts at Stanford University, and the foundation of the platform is backed by over 40 academic papers presented at prestigious AI conferences.
The Challenge
Conventional approaches to AI application development rely on pre-trained, third-party models, rule-based systems, or armies of human labelers. Each of these approaches has its own set of drawbacks and limitations, especially in scenarios where:
Data is private and cannot be shared outside the organization.
Data is complex and requires purpose-built models trained with data labeled by subject matter experts, e.g., doctors, lawyers, financial analysts, network technicians, and alike.
Data changes rapidly, and models need frequent retraining to maintain quality.
Pre-trained models or APIs ignore the nuances of data and objectives and are difficult to customize, adapt, and audit. Rules-based approaches that have been used since the ’80s don’t generalize as well as ML models on complex data or adapt easily to changing data or goals. And machine learning workflows powered by hand-labeled data are notoriously expensive and slow.
To address these challenges, Snorkel AI has developed Snorkel Flow, an AI platform focused on enabling programmatic labeling, streamlining the lifecycle of machine learning applications.
Snorkel Flow: Rooted in Research
Snorkel AI’s core technology was developed by researchers at Stanford AI Lab in collaboration with organizations such as Google, Intel, IBM, Apple, Stanford Health, DARPA, and others. The Snorkel framework is an implementation of the data programming paradigm and training models with weak supervision. This approach uses a set of programmable labeling functions to express different weak supervision strategies and then generates a model based on the effectiveness of the different strategies. In that context, Snorkel streamlines the job of a data engineer by creating a weak supervision model that can be used to build an effective training dataset.
At the risk of overgeneralizing, we can think about the Snorkel framework in three fundamental steps:
Writing Labeling Functions: In this phase, users author labeling functions that express various weak supervision sources such as patterns, heuristics, external knowledge bases, and other organizational resources.
Modeling accuracies and correlations: After the labeling functions are ready, Snorkel learns a generative model that estimates specific accuracies and correlations. The generative model is essentially a re-weighted combination of the user-provided labeling functions.
Training the discriminative model: In this stage, Snorkel produces a set of probabilistic labels that are used to train a model machine learning model.
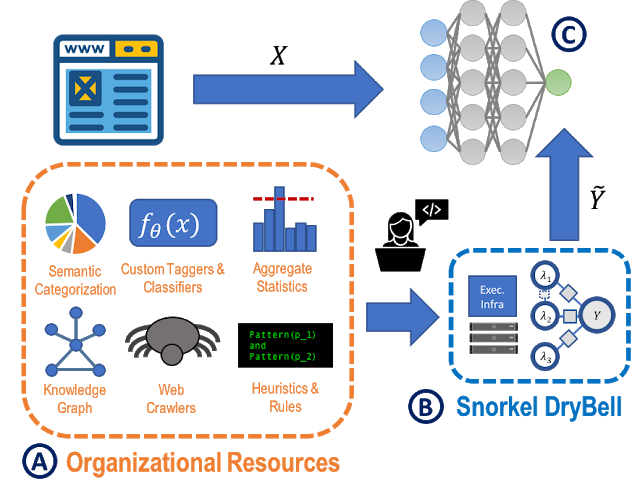
Image credit: Google
The Snorkel framework is one of the first successful initiatives that introduce programmatic data labeling as part of the lifecycle of machine learning models.
How Snorkel Flow Works
Following the popularity and market validation of the Snorkel project, there was an increasing need to productionize Snorkel’s framework and turn proof-of-concept open-source code into a complete, commercial AI workbench. A few leaders behind the Snorkel open-source project started Snorkel AI. Snorkel Flow – their flagship product – enables enterprise-grade capabilities for enhancing the training of machine learning models using programmatic data labeling and weak supervision. At a high level, it expands its capabilities across these fundamental areas of the lifecycle of machine learning models:
1) Label:
Rather than hand-labeling thousands of data points by hand, data scientists or subject matter experts programmatically label massive amounts of training data by writing labeling functions (LF) using a push-button UI or Python SDK using integrated notebooks. These LFs can be simple rules, heuristics, and other custom complex operators or existing organizational resources such as previously hand-labeled data, knowledge bases, or model predictions. Snorkel Flow makes it easy to get started quickly with ready-made labeling functions (LF) builders, like regex, keyword, numerical, or dictionary-based, data exploration tools, and auto-suggest features. Users receive instant feedback with coverage and accuracy estimates of your LFs to develop a high-quality training data set.

Training Data Creation with Snorkel Flow / Image credit: Snorkel AI
2) Manage:
Snorkel Flow automatically learns the different labeling functions’ accuracies, denoises and integrates them, and stores versioned LF packages and training data. Unlike with hand-labeled data, data scientists can create training data in Snorkel Flow using code, then audit, modify, and serve it almost instantly. This also makes it easy for users to share resources, both LFs and training data, with others on their team.

Training Data Management with Snorkel Flow/ Image Credit: Snorkel AI
3) Train:
Users can train state-of-the-art ML models with a visual interface or using the Python SDK in integrated notebooks to plug into existing modeling pipelines. Snorkel Flow provides access to popular open-source model libraries, such as Scikit-Learn, XGBoost, Huggingface Transformers, TensorFlow, and more, that you can train on CPU- or GPU-based computing infrastructure. Snorkel Flow makes it easy to tune models with automated hyperparameter search.

Model Training with Snorkel Flow / Image Credit: Snorkel AI
4) Analyze:
Snorkel Flow includes several commonly used and custom analysis tools to compare multiple models over different data splits. It offers suggestions on improving model quality by adding or editing LFs or optimizing the model to target specific errors
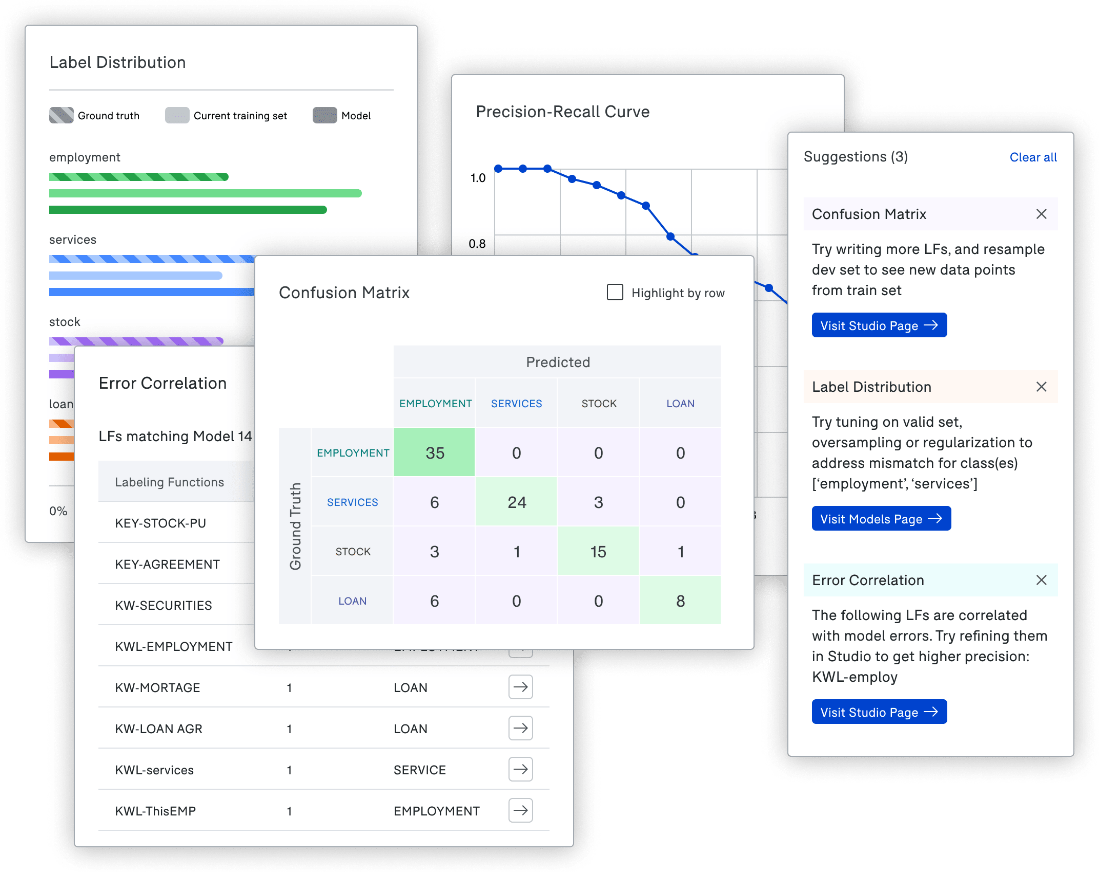
Analysis with Snorkel Flow / Image Credit: Snorkel AI
5) Deploy and Monitor:
Once desired accuracy is achieved by iterating on the model and training data, data scientists can deploy these high-accuracy models immediately as real-time or batch APIs or via the SDK directly from Snorkel Flow. Data scientists can also monitor performance drifts in LFs and the model and rapidly adapt to changes without relabeling from scratch. One of the unique features of Snorkel Flow is that it ties the model's efficiency back to the training processes facilitating the interpretability of the model.
💥 Recent developments
Some recent additions to the Snorkel Flow platform include a new Application Studio, a visual builder with templated solutions for common AI use cases. The objective of the Application Studio is to accelerate AI application development by providing a range of critical components and best practices–including various labeling functions, data visualizations, model classes, application graphs, error analyses, and more. Application Studio is currently in preview and will be generally available later this year within Snorkel Flow.

Application Studio in Snorkel Flow / Image Credit: Snorkel AI
Conclusion
Snorkel Flow addresses the complex data labeling challenge in modern ML solutions. Currently, the Snorkel Flow platform is powering several machine learning production systems for two out of the top three US banks, global insurance, biotech, and telecommunications providers, as well as several government agencies. Snorkel Flow has definitely benefited from the lessons learned from the large-scale deployments of the Snorkel project by sophisticated technology companies, such as Google, Intel, and Apple, Uber, and several others. In addition to the programmatic data labeling capabilities, the current version of Snorkel Flow includes some very tangible benefits in areas such as auditability, interpretability, privacy, and collaboration that makes it a very appealing building block of enterprise-grade ML pipelines.
🧠 The Quiz
Every ten quizzes we reward two random people. Participate! The question is the following:
What is the core concept underpinning the Snorkel Flow platform?
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms, followed by 80,000+ specialists from top AI labs and companies of the world.
