
🥛 Edge#81: Zero-Shot Learning and How It Can Be Used
In this issue:
we discuss Zero-Shot Learning;
we explain LASER – Facebook uses Zero-Shot Learning to Master NLU Tasks Across 93 Languages;
we explore the Hugging Face library that includes an awesome pipeline for Zero-Shot classification.
💡 ML Concept of the Day: What is Zero-Shot Learning?
In this issue of our series about N-shot Learning methods (Edge#79 - Few-Shot Learning, Edge#75 - N-Shot Learning), we would like to discuss the popular new field of zero-shot learning (ZSL). Like many of its N-shot learning alternatives, ZSL methods are extremely useful in scenarios with small labeled datasets for training. Specifically, ZSL tackles a type of problem in which the learner agent is able to classify data instances from classes not seen during training. It is important to note that ZSL is not a form of unsupervised learning. ZSL models are supervised methods that are effectively trained but are able to extrapolate knowledge beyond the basic training dataset.
To put ZSL in context, let’s use the example of an image classifier trained on a dataset that contains images and textual descriptions of animals. For instance, the dataset could contain images of birds and textual descriptions of flamingos. Using those two data vectors, a ZSL model is able to effectively classify images of flamingos even if they were not included in the training dataset. Obviously, this example requires a little bit of multi-modal learning as the agent will have to understand both images and text, but it clearly illustrates the difference between ZSL and unsupervised methods.

Image Credit: Facebook
ZSL was first introduced under the term zero-data learning in a 2008 paper by researchers from the University of Montreal. Since then, ZSL research has skyrocketed, deriving in the creation of different ZSL variations such as the following:
Inductive ZSL: This is the scenario described in our example in which the ZSL agent is trained using two types of data structures, such as images and text, and needs to transfer knowledge between them.
Transductive ZSL: In this scenario, the ZSL agent is trained in labeled and unlabeled datasets and needs to extrapolate the attributes learned from the labeled instances onto the unlabeled ones.
Conventional ZSL: This type of ZSL method applies to scenarios in which the examples presented at test time were never seen during training time.
Generalized ZSL: In this scenario, the ZSL agent is presented with examples of both seen and unseen data at test time.
The field of ZSL is one of the fastest-growing areas of deep learning research and can play a relevant role in the next generation of deep learning applications.
🔎 ML Research You Should Know: With LASER, Facebook Uses Zero-Shot Learning to Master NLU Tasks Across 93 Languages
In the paper “Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond”, Facebook AI Research (FAIR) proposed a multi-language sentence representation method that works across 93 different languages. The implementation of this method was open-sourced under the code-name LASER.
The objective: LASER leverages NLP datasets from popular languages, such as English or French, to master knowledge in languages where large labeled datasets are not available.
Why is it so important: LASER remains one of the most public applications of ZSL techniques available.
Diving deeper: Natural Language Understanding (NLU) is one of the most rapidly developing areas in the deep learning space. However, mastering language tasks for low-resource languages and dialects remains a challenge, given the lack of large labeled datasets. Wouldn’t it be great if we could reuse knowledge from NLU models trained in popular languages such as English, Spanish or French to master tasks in those low-resource languages? With the LASER (Language-Agnostic SEntence Representations) toolkit, the FAIR team was able to leverage ZSL methods to achieve state-of-the-art performance in tasks across 93 languages.
The ZSL architecture used in LASER is based on an encoder-decoder model very similar to the ones used in machine translation tasks. The key difference is that the model uses vector representations of sentences that are generic with respect to both the input language and the NLU task. The idea is to map any sentence to point in a high-dimensional space that translations in any language will be in close proximity to. Using that principle, LASER relies on a five-layer bidirectional LSTM to generate a 1024-dimension vector from a given input sentence. The language-independent embedding is then passed to the decoder which can generate the equivalent sentence in a different language.

LASER achieved state-of-the-art performance in language inference and cross-lingual document classifications across different languages. The FAIR team open-sourced the core library with the model trained in 93 languages as well as a test set for more than 100 languages.
🤖 ML Technology to Follow: Hugging Face Includes an Awesome Pipeline for Zero-Shot Classification
Why should I know about this: There are not many ZSL libraries available to developers yet. Hugging Face has been one of the pioneers in the space operationalizing state-of-the-art ZSL language models.
What is it: If you get excited about ZSL after reading today’s issue of TheSequence Edge, I have some bad news: implementing ZSL models is still incredibly difficult in today’s deep learning ecosystem. This is partly due to the fact that ZSL remains in a relatively experimental phase and not many libraries are available for mainstream applications. One of the exceptions to that rule is Hugging Face. The amazing natural language understanding (NLU) research platform recently added zero-shot classification techniques to its transformers library. Using these models, developers can enable classification tasks in language datasets without any prior training.
The specific ZSL method implemented by the Hugging Face library is based on neural language inference (NLI) tasks. This type of method takes two sequences as input and determines whether they contradict each other, entail each other, or neither. NLI tasks can be adapted as zero-shot classification by simply setting up the target text we would like to classify as one of the input sequences, in this case called the premise, and the set of candidate labels as the other sequence, called the hypothesis. If the NLI model predicts that the premise entails the hypothesis then it infers that the labels correctly classify the text.
The Hugging Face ZSL pipeline abstracts the complexity of zero-shot classification behind an incredibly simple developer experience. Literally, you can implement a complex zero-shot classification task in 4-5 lines of code as illustrated in the following example.
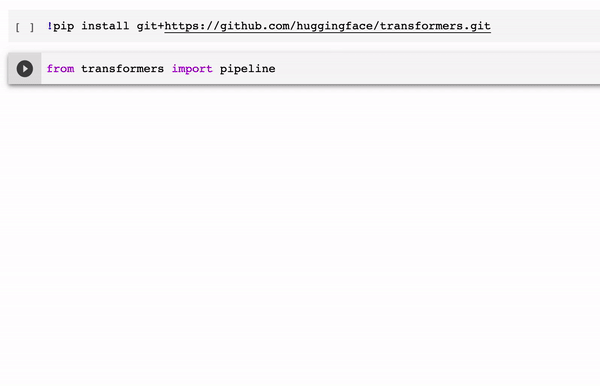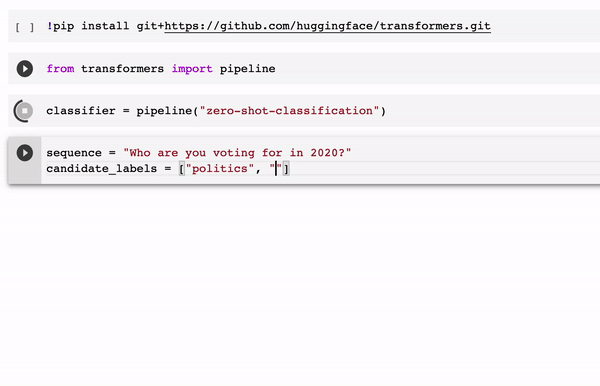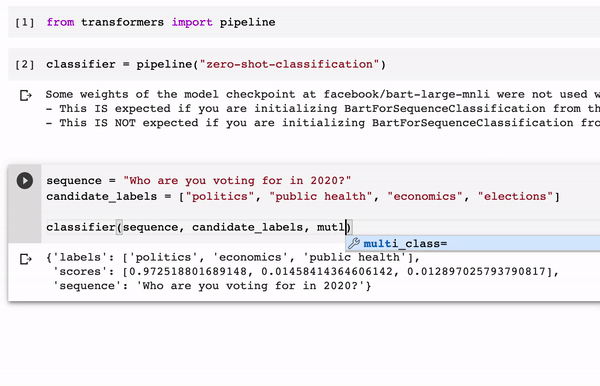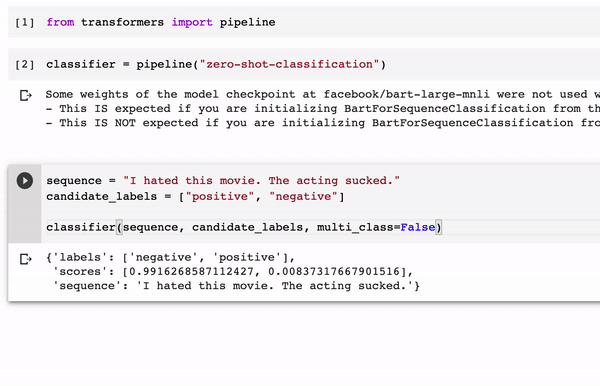
The Hugging Face zero-shot classification pipeline is one of the main implementations of ZSL methods available to mainstream developers. As this space evolves, we should see new ZSL methods incorporated into popular deep learning frameworks such as TensorFlow or PyTorch. For now, the Hugging Face team is off to a great start.
How can I use it: Hugging Face’s zero-shot classification pipeline is open source and available at https://github.com/huggingface/transformers/pull/5760
🧠 The Quiz
Now, to our regular quiz. After ten quizzes, we will reward the winners. The questions are the following:
Which of the following definitions better describes zero-shot-learning?
How does Facebook’s LASER method uses zero-shot-learning to master tasks across many languages?
That was fun! 👏 Thank you.
Are you on Twitter? Follow us there, we post our favorite math paradoxes, history threads, important recaps, and do retweets of the events and accounts worth following.