

🐍🦎 Edge#73: Meta-Learning and AutoML, OpenAI’s Reptile Model, and the Auto-Keras Framework
🐍🦎 Edge#73: Meta-Learning and AutoML, OpenAI’s Reptile Model, and the Auto-Keras Framework
In this issue:
we discuss meta-learning as a form of AutoML;
we explain OpenAI’s Reptile model for efficient meta-learning;
we explore the Auto-Keras framework.
💡 ML Concept of the Day: Meta-Learning and AutoML
In the final issue of our series about AutoML, we would like to discuss the perspective of meta-learning as a form of AutoML. This position is a bit controversial because, conceptually, meta-learning encompasses a bigger universe of techniques focused on “learning to learn.” However, many meta-learning methods end up generating new machine learning models for a given task, which is a clear definition of AutoML.
Conceptually, meta-learning typically refers to the ability of a model to improve the learning of sophisticated tasks by reusing knowledge learned in previous tasks. That level of knowledge acquisition and reusability can be foundational in many AutoML methods. While there is a very broad set of meta-learning methods, we can identify three main forms that are relevant to AutoML.
Meta-Learning Methods Based on Model Evaluations: This group of meta-learning methods focuses on learning new tasks based on the configuration of models based on similar tasks. By configuration we refer to elements such as hyperparameter settings, pipeline components and/or network architecture components, which can form a discrete or continuous search space. The output of this type of meta-learning technique are new models that are similar to the models in the search space.
Meta-Learning Methods Based on Task Properties: Another family of meta-learning methods relevant to AutoML are those that can transfer knowledge between empirically similar tasks. More specifically, this type of meta-learning method describes tasks as a set of meta-features and predicts the outcome of similar tasks by evaluating the distance with its meta-feature vector and other tasks.
Meta-Learning Methods Based on Previous Models: The third group of meta-learning techniques used in AutoML tasks consists of methods that can learn from prior machine learning models themselves, using aspects such as their structure and learned model parameters. This school of meta-learning has major overlaps with transfer learning as it focuses on transferring trained model parameters between tasks that are inherently similar and share the same input features.
These forms of meta-learning methods are highly applicable to AutoML scenarios, as they learn to discover new models based on existing models and task configurations. Thinking about meta-learning in the context of AutoML is incredibly helpful for materializing what can otherwise be considered a super abstract machine learning discipline.
🔎 ML Research You Should Know: OpenAI’s Reptile is One of the Most Efficient Meta-Learning Methods Ever Created
In the paper “On First-Order Meta-Learning Algorithms”, researchers from OpenAI propose a super clever meta-learning algorithm called Reptile that can quickly learn new tasks from a given distribution.
The objective: Reptile builds on the principles of the famous model-agnostic meta-learning (MAML) algorithm developed by Berkeley University, but it simplifies its approach to master unseen tasks from a base distribution.
Why is it so important: Reptile is one of the most important meta-learning algorithms published in recent years.
Diving deeper: Meta-learning is a broad discipline with many types of methods and algorithms. A very common form of meta-learning algorithms takes in a distribution of tasks, where each task is a learning problem, and it produces a quick learner — a learner that can generalize from a small number of examples. Meta-learning is a brand new area of research in the deep learning space. In 2017, the Berkeley research lab produced a new meta-learning algorithm called model-agnostic-meta-learning (MAML) that sort of set the bar for the space. MAML is widely recognized as one of the most important advancements in meta-learning in the last few years (we covered MAML in detail in Edge#11). Building on the progress of MAML, researchers at OpenAI created a new meta-learning algorithm called Reptile that builds on the principles of MAML to determine the right learning path from the distribution of learning tasks.
Conceptually, Reptile works by repeatedly sampling a task, performing stochastic gradient descent on it, and updating the initial parameters towards the final parameters learned on that task. The Reptile algorithm learns an initialization for the parameters of a neural network, such that the network can be fine-tuned using a small amount of data from a new task. For every given task, Reptile simply performs stochastic gradient descent (SGD) to evaluate its performance and adjust accordingly. This makes Reptile take less computation and memory than predecessors like MAML that rely on calculating second-order derivatives in the computation graph. In the research paper you can find a pseudo-code for the Reptile algorithm:

When I first read about Reptile, I was surprised that this method worked at all. At first glance, Reptile seems like the type of meta-learning model that could only work in problems where zero-shot learning is possible, as it basically relies on performing SGD on a mixture of tasks. However, the OpenAI paper shows that Reptile’s constant SGD optimizations lead to maximizing the inner product between gradients of different minibatches from the same task, which in turn leads to improved and faster generalization. In many meta-learning tasks, Reptile showed similar performance to MAML but was able to achieve faster generalizations.
Since its initial publication, there have been several implementations of the Reptile algorithm in frameworks such as TensorFlow and JavaScript. Reptile remains one of the most interesting meta-learning algorithms created in recent years.
🤖 ML Technology to Follow: Auto-Keras is an AutoML Framework Every Data Scientists Should Know
Why should I know about this: Auto-Keras is one of the simplest and most widely-used AutoML libraries in the data science space.
What is it: If you are looking for a simple Auto-ML framework, Auto-Keras should be at the top of your list. Auto-Keras is an AutoML library designed to provide an alternative to neural architecture search (NAS) approaches. Initially developed by the DATA Lab at Texas A&M University, Auto-Keras leverages Bayesian optimization to develop a neural network kernel and a tree-structured acquisition function optimization algorithm to efficiently explore the model search space. This method sort of translates into a more efficient NAS technique.
Differently from other AutoML frameworks in the market, Auto-Keras focuses on deep learning tasks. Its architecture is based on five fundamental components:
Searcher: This is a module that includes several NAS capabilities based on Bayesian Optimizer and Gaussian Process.
Trainer: This module enables computations on a GPU topology. The model trainer uses parallelism to train neural networks in separate processes, optimizing the performance of the entire lifecycle.
Graph: This module is responsible for processing the computational graphs of neural networks, which are controlled by the Searcher for the network morphism operations.
Storage: This component persists a pool of trained models so that they can easily be accessed by the other layers of the framework.
API: Abstracts the core functionalities of the Auto-Keras components.
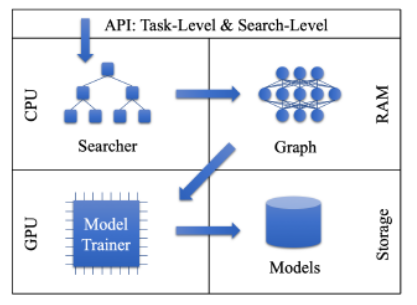
Image credit: Auto_Keras
Auto-Keras provides a simple programming model that enables the creation of Auto-ML tasks in a few lines of code. The framework includes a rich portfolio of baseline architectures for tasks such as classification and regression. Auto-Keras has been built with extensibility in mind, which has allowed the community to actively contribute new functionalities to the framework.
How can I use it: Auto-Keras is open source and available at https://github.com/keras-team/autokeras
🧠 The Quiz
Now, to our regular quiz. After ten quizzes, we will reward the winners. The questions are the following:
Which of the following statements best describes OpenAI’s Reptile meta-learning algorithm?
What is the main innovation of Auto-Keras compared to other NAS or AutoML stacks?
That was fun! 👏 Thank you.