
☕️ Edge#42: What’s New in AI: LinkedIn's Dagli
TheSequence is a convenient way to build and reinforce your knowledge about machine learning and AI
Recently we introduced a new format – What’s New in AI, a deep dive into one of the freshest research papers or technology frameworks that’s worth your attention. Our goal is to keep you up to date with new developments in AI in a way that complements the concepts we are debating in other editions of our newsletter.
💥 What’s New in AI: Dagli is a New, Open Source, Java-Based Framework that Powers Machine Learning at LinkedIn
Java is one of the most popular programming languages in the world with millions of developers and a rich community. However, the support for machine learning stacks for Java Virtual Machine (JVM) languages has paled in comparison to that of Python’s. LinkedIn recently open-sourced Dagli, a new framework for simplifying the implementation of machine learning models in JVM-based languages. Let’s take a look.
LinkedIn’s Dagli: A Machine Learning Framework for Java Developers
Java has been part of the core DNA of LinkedIn since its inception. The technology giant remains one of the fastest adopters of the JVM-based platform. Like any large technology company, LinkedIn uses different machine learning stacks such as TensorFlow or Spark ML. However, it’s only natural that they invested more in empowering the implementation of ML models in Java in order to leverage their existing infrastructure and development talent. Dagli is one of the results of that effort.
If you are a Java developer trying to get into the machine learning space, Dagli is an option to consider. It’s not that there are no alternatives. Frameworks such as DeepLearning4J and the recently released Tribuo (we will be covering this in a future issue) offer very viable options for implementing ML models in JVM languages. While those frameworks provide solid programming models and rich ML libraries, the implementation of end-to-end ML pipelines remains incredibly challenging. Aspects such as training, feature extraction and model deployment require quite a bit of effort when using those frameworks.
With Dagli, LinkedIn tries to streamline the implementation of ML models in Java and other JVM-based languages. Conceptually, Dagli was designed with three main objectives:
Build an easy-to-use, bug-resistant Java-based ML framework.
Add a rich collection of models, statistical building blocks and feature transformers that can be rapidly incorporated into ML models.
Enable a simple abstraction.
As you can probably guess by the name, Dagli represents machine learning programs as directed acyclic graphs (DAGs). Dagli’s DAG structure is based on a very simple structure composed of four fundamental types of root and child nodes:
Root Node – Placeholder: Placeholders represent values that will be filled during the training phase or generators that transfer values to the other nodes.
Root Node – Generator: Generator is a root that transfers data to its children.
Child Node – Transformer: Transformers are nodes that transform the inputs received by the parent nodes in order to produce a result.
Child Node – Views: Views are similar to Transformers but they contain a single parent and simply pass the input information to its children.
These four types of nodes represent the core abstraction of any Dagli program. Not only does Dagli leverage DAGs as a simple level of abstraction of machine learning programs, but also as a structure to execute complex inference workloads and provide transparency about the inner workings of ML models. For instance, consider the following Java code (Python developers please don’t leave yet 😉) that implements a simple logistic classifier:

Image credit: LinkedIn
The program produces the following Dagli DAG:
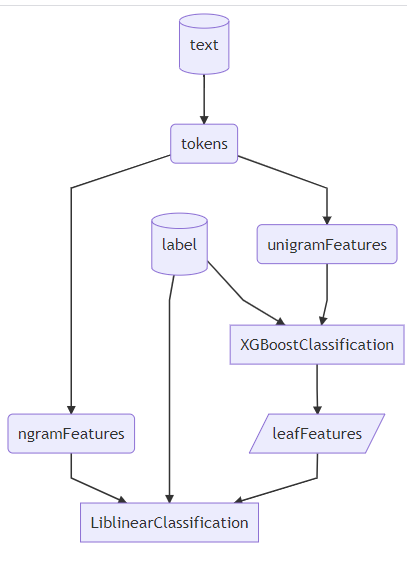
Image credit: LinkedIn
In addition to the flexible DAG structures for representing Java ML programs, Dagli brings some tangible benefits to Java developers:
ML Artifacts: Dagli includes rich libraries of ML components that simplify the implementation of ML models. Examples of these artifacts include neural networks, logistic regression, gradient boosted decision trees, FastText, cross-validation, cross-training, feature selection, data readers, evaluation, and feature transformation.
Portability: Dagli can be executed on several JVM runtimes ranging from Hadoop servers to a local computer.
Training-Inference Pipeline: Dagli defines a single DAG for both training and inference, which simplifies the interpretability of models.
Deployment: Dagli programs are very simple to deploy as they are, essentially, serialized as a single object.
Maybe the most important benefit of Dagli is the possibility of attracting Java developers into the ML world. The fact that Dagli has been incubated and tested at scale in LinkedIn certainly brings much-needed credibility into the ecosystem of Java ML frameworks.
Additional Resources: The first version of Dagli has been open-sourced and available at https://github.com/linkedin/dagli. The LinkedIn engineering team wrote an insightful blog post accompanying the release https://engineering.linkedin.com/blog/2020/open-sourcing-dagli
🧠 The Quiz
Now, to our regular quiz. Participate to check your knowledge. The question is the following:
What is the main specific data structure used by LinkedIn’s Dagli framework to represent machine learning programs?
Thank you. See you on Sunday 😉
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. TheSequence keeps you up to date with the news, trends, and technology developments in the AI field.
5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space.
