
🟢⚪️ Edge#210: Hopsworks 3.0, Connecting Python to the Modern Data Stack
On Thursdays, we deep dive into one of the freshest research papers or technology frameworks that is worth your attention. Our goal is to keep you up to date with new developments in AI and introduce to you the platforms that deal with the ML challenges.
💥 Deep Dive: Hopsworks 3.0, Connecting Python to the Modern Data Stack
The rise of big data, cloud computing, and artificial intelligence (AI) is transforming the way businesses operate. The ability to collect, store, and process large amounts of data is opening up new opportunities for insights and decision-making.
The so-called “Modern Data Stack” (MDS) is a suite of frameworks and tools that has emerged in recent years to help businesses take advantage of these opportunities. The Modern Data Stack includes data lakes and warehouses, ETL and reverse tools, orchestration, monitoring, and much more.
One vast unfilled need in the MDS is enterprise AI. Machine learning is dominated by Python tools and libraries, which are insufficient for the increasingly demanding needs of data scientists. Attempts to transpile Python code to SQL for the MDS have been made, but these efforts fall short, as data scientists are unlikely to want to perform dimensionality reduction, variable encodings, and model training/evaluation in user-defined functions and SQL.
In this deep dive, we will take a look at the difference between the MDS and ML worlds, and how Hopsworks tackles the problem by building a Python-to-SQL bridge.
MDS; a SQL-centric paradigm

The Modern Data Stack is heavily focused on SQL. This declarative language is relatively straightforward to learn and use, and it is the lingua franca for interacting with data warehouses, lakes, and BI tools. SQL is also well suited for distributed computing, which is necessary for processing large amounts of data.
Further, the declarative nature of SQL makes it easier to scale out compute to process large volumes of data, compared to a general-purpose programming language like Python – which lacks native distributed computing support.
As the Modern Data Stack continues to grow and evolve, it is clear that there is a need for a Python-to-SQL bridge that will allow data scientists to take advantage of the benefits of both worlds.
Machine Learning; a Python-centric world
While the world of analytics is dominated by SQL, the world of machine learning is dominated by Python. This programming language has become the de facto standard for data science due to its flexibility, ease of use, and rich set of libraries and frameworks.
Python's grip on machine learning is so pervasive that Stack Overflow's survey results from June 2022 show that Pandas, NumPy, TensorFlow, Scikit-Learn, and PyTorch are all in the top 11 of the most popular frameworks and libraries across all languages.
Python has shown itself to be flexible enough for use within notebooks for prototyping and reporting, for production workflows (such as in Airflow), for parallel processing (PySpark, Ray, Dask), and now even for data-driven user interfaces (Streamlit). In fact, even entire serverless ML systems with feature pipelines, batch prediction pipelines, and a user interface can be written in Python, such as seen in this Surf Prediction System from PyData London.
Modern Data Stack vs Modern AI Stack: Closing The Gap
Countless machine learning models are never deployed into production. Only about 10-15% make it into production. These sky-high failure rates are often attributed to a lack of talent or resources. In light of an ongoing labor shortage and tightening IT budgets, these explanations seem plausible, but they don't get to the root of the problem.
The core issue lies in the lack of production-ready tools and infrastructure for machine learning within the MDS. The majority of machine learning models are written in Python, but the production MDS stack is not designed to make it easy to productionize Python-based machine learning models. Data scientists and ML engineers are often left with prototypes that work on data dumps, which cannot be easily connected to the rest of the MDS. Without access to features within the MDS, these prototypes are severely limited and cannot take advantage of historical or contextual data. This lack of connectivity is a major reason why so many machine learning models never make it into production.
Meaningfully empowering data scientists means providing them with the tools and infrastructure they need to be successful. In particular, data scientists need to be able to access data within the MDS from Python without having to master the complexities of SQL and data access control. The Feature Store is one part of the solution to this problem. It is a new layer that bridges some of the infrastructural gap.
While the likes of Snowflake's Snowpark have tried to address this problem, they fall short because they don't provide a complete solution. Without its own Feature Store, Snowpark by itself is not enough.
The first Feature Stores were introduced by the Big Data community and were primarily designed for Spark and Flink. However, there has been a noticeable lack of a Python-centric Feature Store that bridges the gap between the SQL world and the Python world. Hopsworks addresses exactly that problem in order to empower data scientists to take full advantage of the Modern Data Stack.
Meet Hopsworks 3.0, the Python-centric feature store
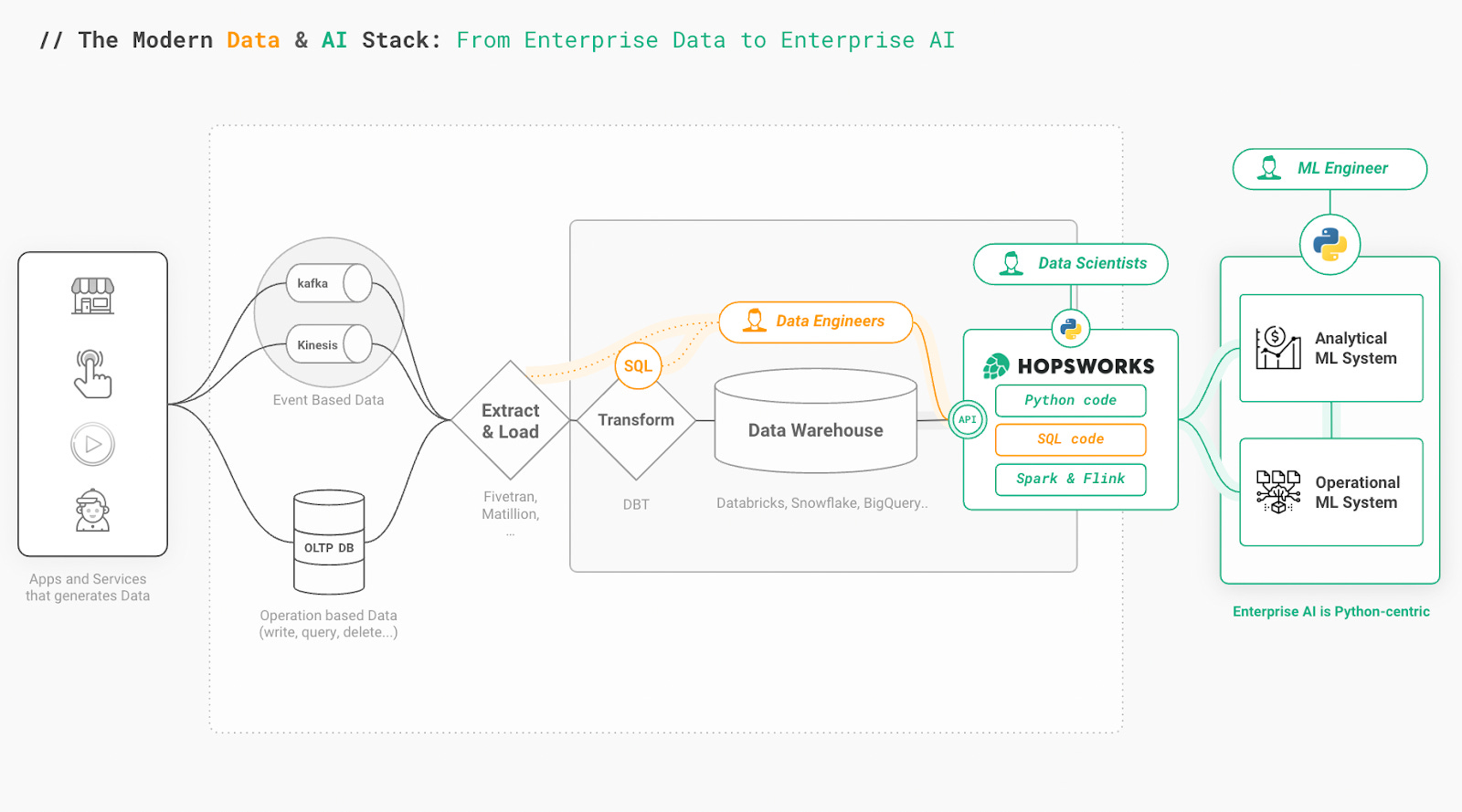
Hopsworks was the first open-source feature store, released at the end of 2018, and now with the version 3.0 release, it takes a big step to bridge the Modern Data Stack with the machine learning stack in Python.
With improved Read and Write APIs for Python, Hopsworks 3.0 allows data scientists to work, share, and interact with production and prototype environments in a Python-centric manner. Hopsworks uses transpilation, or source-to-source compilation, to bring the power of SQL to their Python SDK. This enables the seamless transfer of data from warehouses to Python for feature engineering and model training. It also provides a Pandas DataFrame API for writing features and ensures the consistent replication of features between Online and Offline Stores.
Hopsworks 3.0 also comes with support for Great Expectations, a shared, open standard for data quality that allows for data validation in feature pipelines. Custom transformation functions can be written as Python user-defined functions and applied consistently between training and inference.
To use Hopsworks 3.0 without any infrastructure requirements, try their newly released serverless app.hopsworks.ai.