
🟧 Edge#192: Inside Predibase, the Enterprise Declarative ML Platform
On Thursdays, we do deep dives into one of the freshest research papers or technology frameworks that is worth your attention. Our goal is to keep you up to date with new developments in AI and introduce to you the platforms that deal with the ML challenges.
💥 Deep Dive: Inside Predibase, the enterprise declarative machine learning platform
Low-code ML platforms have received a lot of attention in the past few years, but haven’t yet achieved widespread adoption. Predibase looks to deliver a high-performance, low-code approach to machine learning (ML) for individuals and organizations who have tried operationalizing ML but found themselves re-inventing the wheel each step of the way. Like infrastructure-as-code simplified IT, Predibase’s declarative approach allows users to focus on the “what” of their ML tasks while leaving its system to figure out the “how”.
Where things go wrong today
Building ML solutions at organizations today is time-consuming and requires specialized expertise. After several months of development, the result is typically a bespoke solution that is handed over to other engineers, is often hard to maintain in the long term and creates technical debt. The founders of Predibase see this as the COBOL era of machine learning, and believe the field needs its “SQL moment”.

This is a familiar pain for data science leaders, but many have been equally disenchanted by low-code/no-code automated machine learning solutions that haven’t scaled to the needs of their organization. Often, these tools are used for prototyping but fall short of being promoted to production.
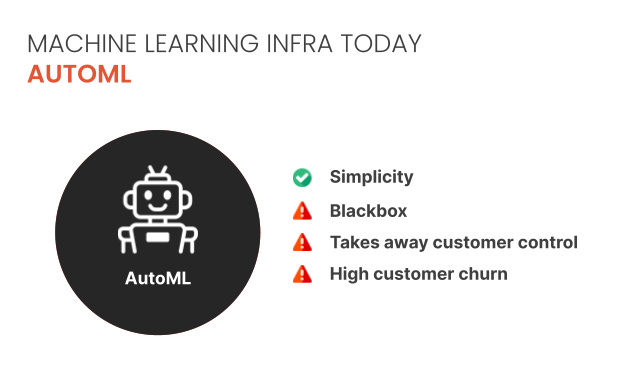
Furthermore, the tools that are built-for-scale (Spark, Airflow, Kubeflow) are not the same tools that are built-for experimentation. The path of least resistance in most data science teams becomes downloading some subset of the data to a local laptop and training a model using some amalgamation of Python libraries like Jupyter, Pandas, and PyTorch, and then throwing a model over the wall to an engineer tased with putting it in production.
The solution is to strike the right abstraction for both ML modeling and infrastructure – one that provides an easy out-of-the-box experience while supporting increasingly complex use cases and allowing the users to iterate and improve their solutions.
Declarative ML Systems: LEGO for Machine Learning
The basic idea behind declarative ML systems is to let users specify entire model pipelines as configurations and be intentional about the parts they care about while automating the rest. These configurations allow users to focus on the “what” rather than the “how” and have the potential to dramatically increase access and lower time-to-value.

Declarative ML systems were pioneered by Ludwig at Uber and Overton at Apple. (check this interview about Ludwig and the importance of low-code ML we did with Piero Molino, creator of Ludwig, CEO of Predibase, last year). Ludwig served many different applications in production ranging from customer support automation, fraud detection and product recommendation while Overton processed billions of queries across multiple applications. Both frameworks made ML more accessible across stakeholders, especially engineers, and accelerated the pace of projects.
Predibase is built on top of Ludwig, which allows users to define deep learning pipelines with a flexible and straightforward configuration system, suitable for a wide variety of tasks. Depending on the types of the data schema, users can compose and train state-of-the-art model pipelines on multiple modalities at once.
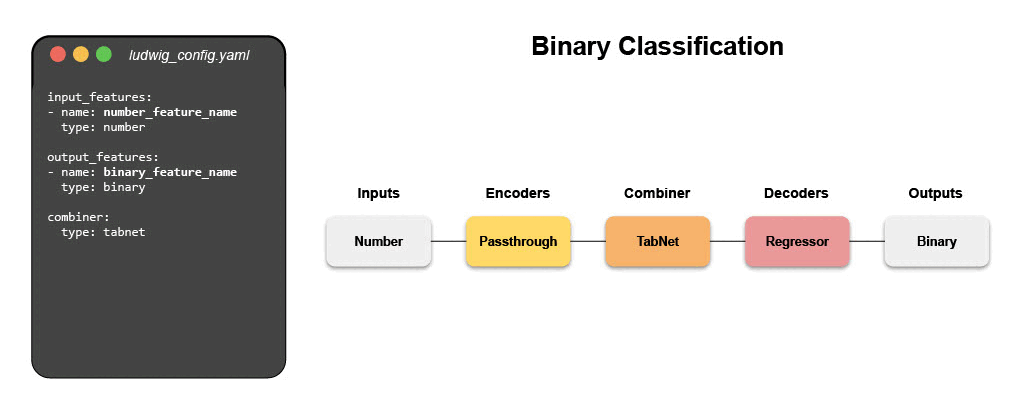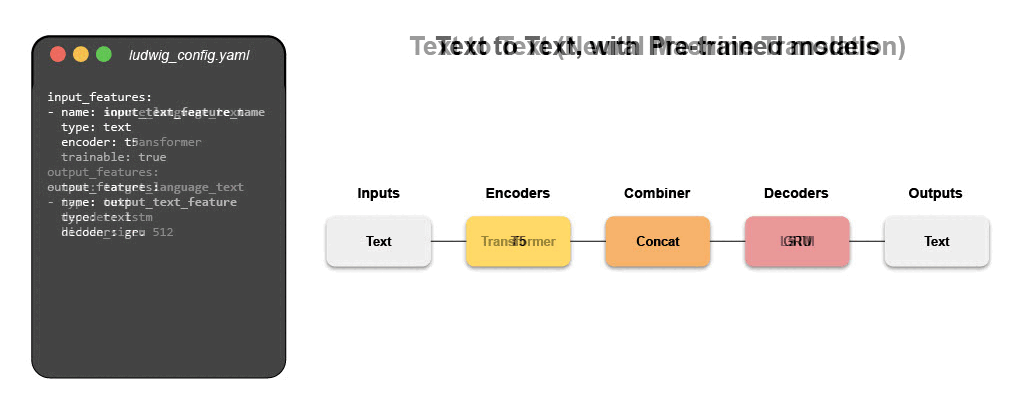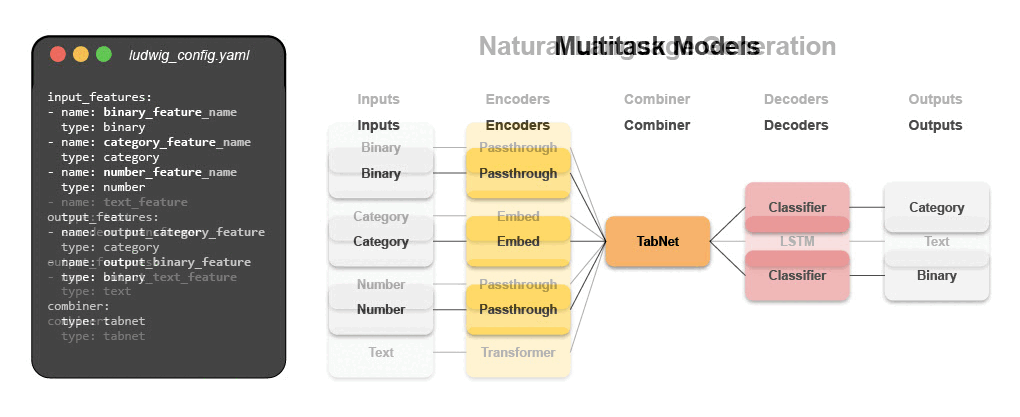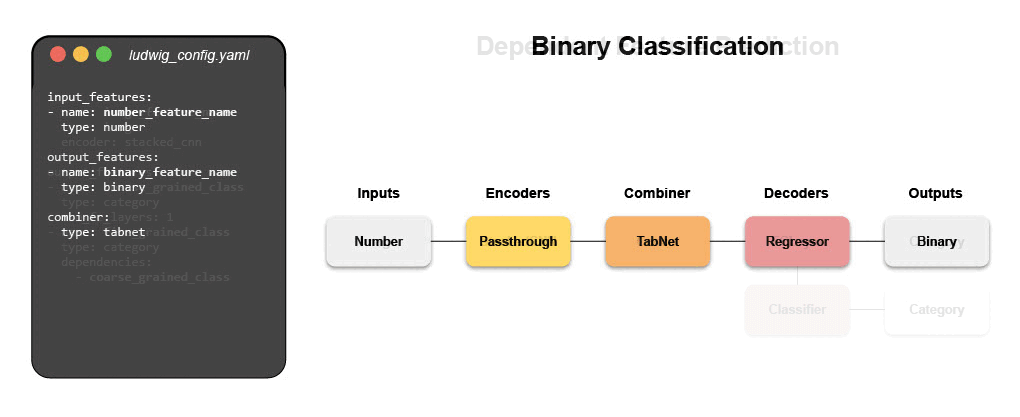
Writing a configuration file for Ludwig is easy, and provides users with ML best practices out-of-the-box, without sacrificing control. Users can choose which part of the pipeline they want to swap new pieces in for, including choosing among state-of-the-art model architectures and training parameters, deciding how to preprocess data and running a hyperparameter search, all via simple config changes. This declarative approach increases the speed of development, makes it easy to improve model quality through rapid iteration, and makes it effortless to reproduce results without the need to write any complex code. One of Ludwig’s open-source users referred to composing these configurations as “LEGO for deep learning”.
But as any ML team knows, training a deep learning model alone isn’t the only hard part – building the infrastructure to operationalize the model from data to deployment is often even more complex. That’s where Predibase comes in.
Predibase – Bringing declarative ML to the enterprise
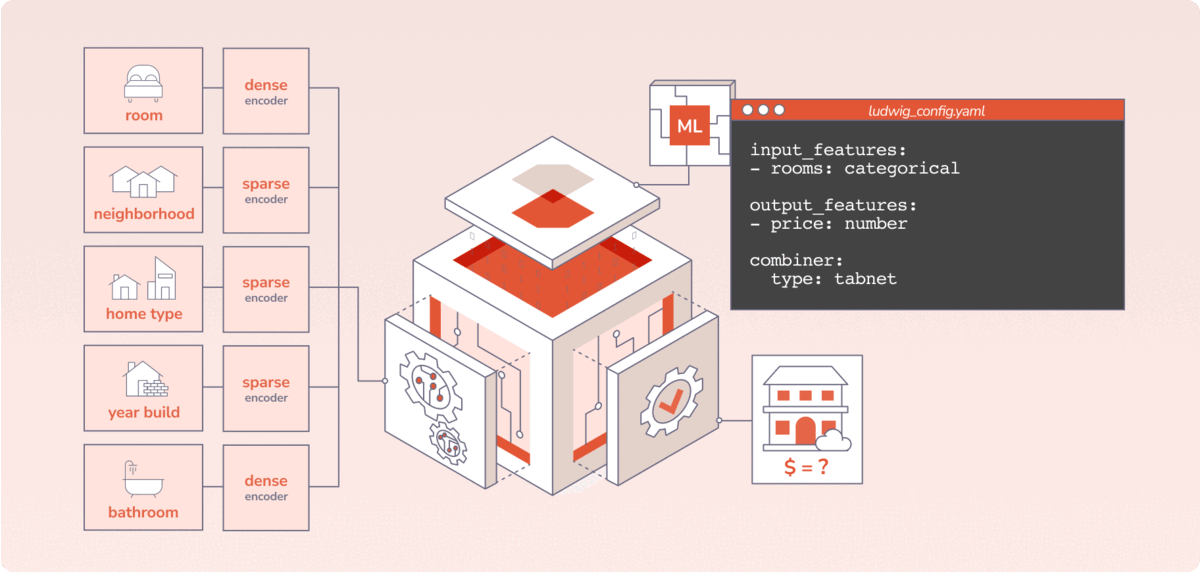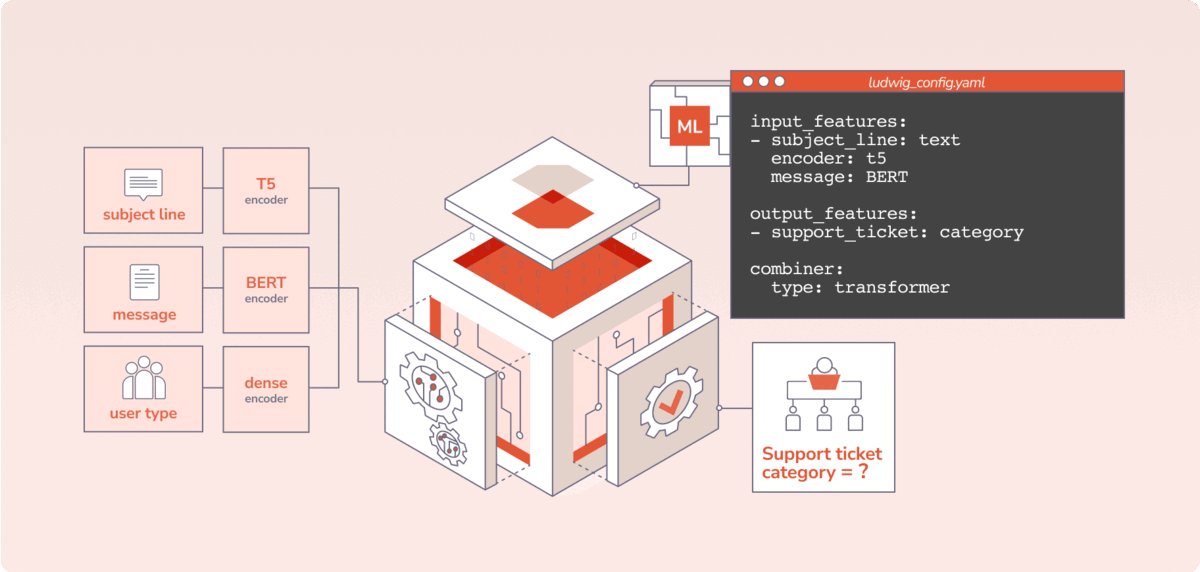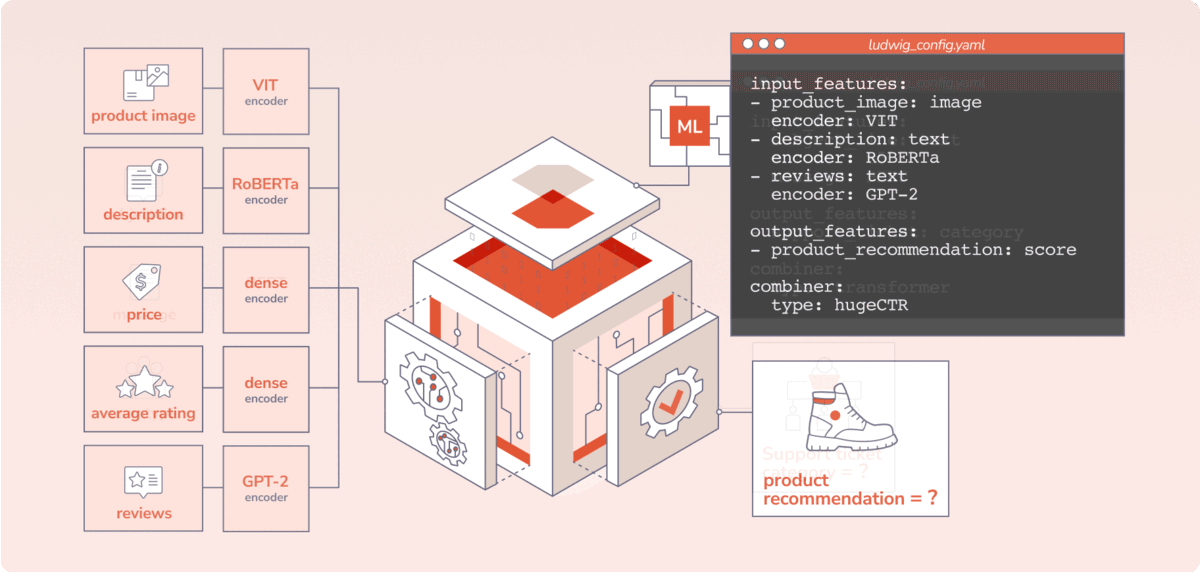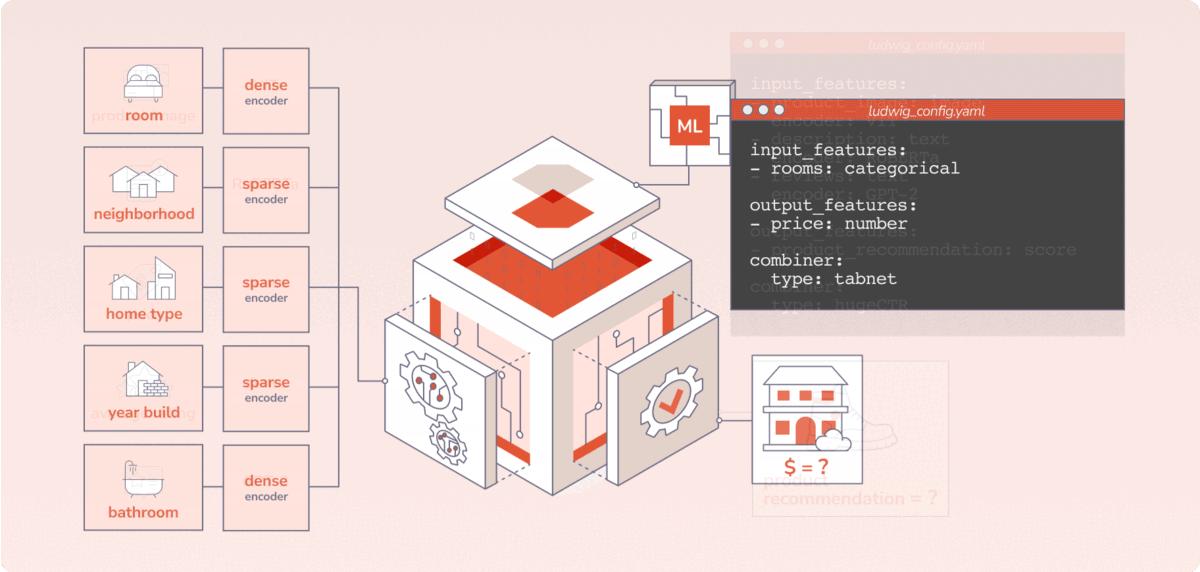
Predibase brings the benefits of declarative ML systems to market with an enterprise-grade platform. There are three key things users do in Predibase:
Connect data – structured & unstructured data, from the modern-data-stack.
Declaratively build models – provide model pipeline configurations and run on a scalable distributed infrastructure as easily as on a single machine.
Operationalize models – deploy model pipelines at the click of a button.
Predibase's vision is to bring all the stakeholders of data & AI organizations together in one place, making collaboration seamless between data scientists working on models, data engineers working on deployments and product engineers using the models. The four pillars that were added on top of their open source foundations to make this reality are:
1. Integrated platform: the fastest path from data-to-deployment
Predibase connects directly to your data sources, both structured data warehouses and unstructured data lakes. Any model trained in Predibase can be deployed to production with zero code changes and configured to automatically retrain as new data comes in because both experimentation and productionization go through the same unified declarative configuration.
2. Cutting-edge infra made painless
Predibase features a cloud-native serverless infrastructure layer built on top of Horovod, Ray, and Kubernetes. It provides the ability to autoscale workloads across multi-node and multi-GPU systems in a way that is cost-effective and tailored to the model and dataset. This combines highly parallel data processing, distributed training, and hyperparameter optimization into a single workload, and supports both high throughput batch prediction as well as low-latency real-time prediction via REST.
3. A new way to do iterative modeling
The declarative abstraction that Predibase adopts makes it easy for users to modify model pipelines by editing their configuration. Defining models as configs allows Predibase to show differences between model versions over time in a concise way, making it easier to iterate and improve them. That also allows to introduce a unique alternative to AutoML: instead of running expensive experiments, Predibase suggests the best subsequent configurations to train depending on the explorations already conducted, creating a virtuous cycle of improvement.
4. Supporting multi-personas with PQL
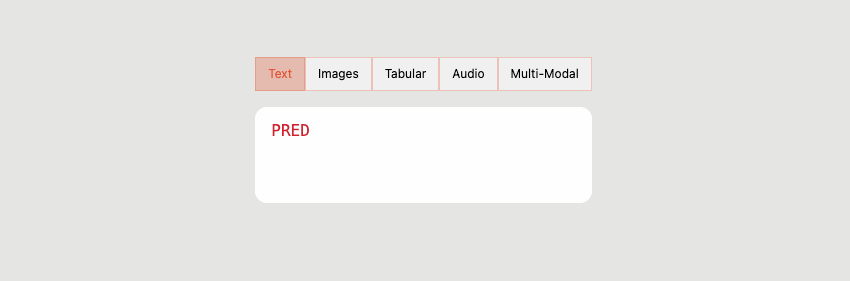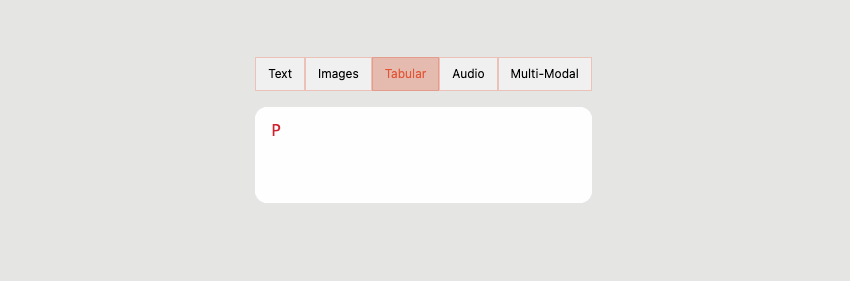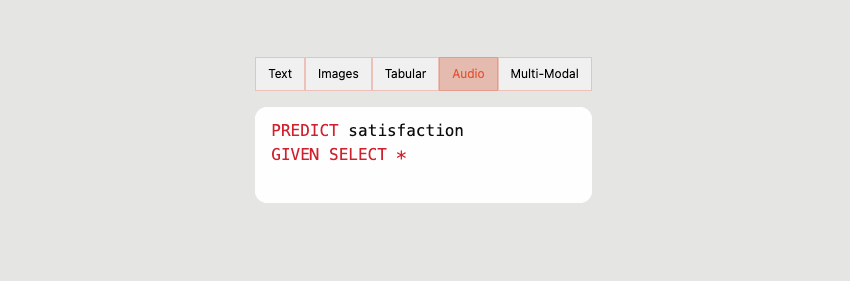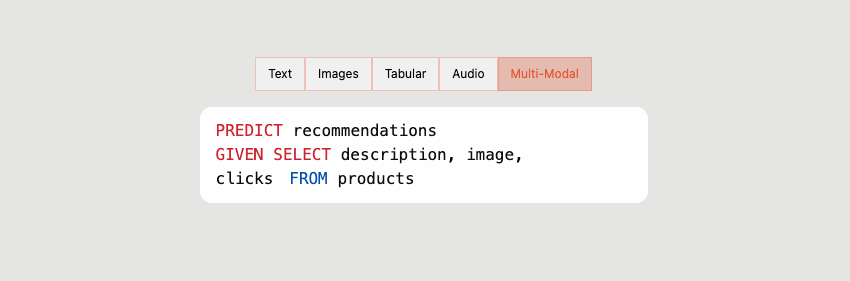
With the rise of the modern data stack, the number of data professionals comfortable with SQL has also grown. So, alongside its Python SDK and UI, Predibase also introduces PQL – Predictive Query Language – as an interface that brings ML closer to the data. Using PQL, users can train models and run predictive queries through a SQL-like syntax they are already familiar with.
Conclusion
Declarative machine learning systems have dramatically increased the velocity and lowered the barrier-to-entry for machine learning projects at leading tech companies, and now Predibase is bringing the approach to all organizations with its enterprise platform built on open-source foundations. Predibase is currently available by invitation only, you can request a demo here: https://predibase.com/request-early-access