
🔬 Edge#145: MLOPs – model observability
plus an architecture for debugging ML models and overview of Arize AI
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. On Tuesdays, we cover important ML concepts, keep you up-to-date with relevant research papers and explain the most prominent tech frameworks.
In this issue:
we discuss model observability and its difference from model monitoring;
we discuss Manifold, an architecture for debugging ML models;
we overview Arize AI that enables the foundation for ML observability.
💡 ML Concept of the Day: Model Observability
In 🩺 Edge#141, we discussed the topic of model monitoring. Today, we would like to dive into a relatively similar capability of ML pipelines known as model observability. While many ML teams will use the terms monitoring and observability interchangeably, there are relevant differences between the two, and they are evolving as separate aspects of ML stacks. At a high level, we can think of ML monitoring capabilities as a way to identify what could be wrong in an ML pipeline. In contrast, ML observability features are more interested to understand why something is happening. That what vs. why focus is what fundamentally differentiates monitoring versus observability. For instance, let’s take a simple scenario of model performance drift. An ML monitoring stack will be able to detect the performance degradation in the model. In contrast, an ML observability stack will compare data distributions and other key indicators to help pinpoint the cause of the drift.
The difference between monitoring and observability is not unique to the ML space and can be traced back to the origins of control theory and has been present in most relevant trends in the software industry. However, ML adds a different dimension to it. While most observability technologies have focused on code and infrastructure, ML observability focuses on ML models and the datasets used to train and validate them. In general, robust observability is a combination of high-quality statistical metrics in the datasets, explainability techniques in the models as well as statistical validations on the output predictions. Robust ML observability should include:
Model lineage, validation, comparison
Data quality monitoring and troubleshooting
Drift monitoring/troubleshooting
Performance monitoring/troubleshooting
Business impact analysis

As ML models gravitate towards more complex structures, observability will become a more relevant component of MLOps stacks. In the long term, we should expect most ML monitoring stacks to incorporate observability capabilities as a first-class citizen. For now, several platforms are already pioneering observability capabilities in ML pipelines.
🔎 ML Research You Should Know: Manifold, an Architecture for Debugging Machine Learning Models
In the paper Manifold: A Model-Agnostic Framework for Interpretation and Diagnosis of Machine Learning Models, researchers from Uber outlined an architecture for the visual interpretation of ML models.
Why is it so important: Uber has adopted the Manifold architecture to enable the debugging of machine learning models at scale.
Diving deeper: Manifold segments the machine learning analysis process into three main phases: Inspection, Explanation, Refinement.
Inspection: In the first part of the analysis process, the user designs a model and attempts to investigate and compare the model outcome with other existing ones. During this phase, the user compares typical performance metrics, such as accuracy, precision/recall, and receiver operating characteristic curve (ROC), to have coarse-grained information of whether the new model outperforms the existing ones.
Explanation: This phase of the analysis process attempts to explain the different hypotheses formulated in the previous phase. This phase relies on comparative analysis to explain some of the symptoms of the specific models.
Refinement: In this phase, the user attempts to verify the explanations generated from the previous phase by encoding the knowledge extracted from the explanation into the model and testing the performance.
The three steps of the machine learning analysis process materialize on a simple user interface that streamlines the debugging of machine learning models. The Manifold user interface consists of two main dialogs:
Performance Comparison View visually compares model pairs using a small multiple design and a local feature interpreter view.
Feature Attribution View reveals a feature-wise comparison between user-defined subsets and provides a similarity measure of feature distributions.
From an architecture standpoint, the Manifold workflow takes a group of ML models as input and produces different data segments based on feature engineering. The feature segments are then processed by a group of encoders that produces a set of new features with intrinsic structures that were not captured by the original models, helping users iterate new models and obtain better performance.
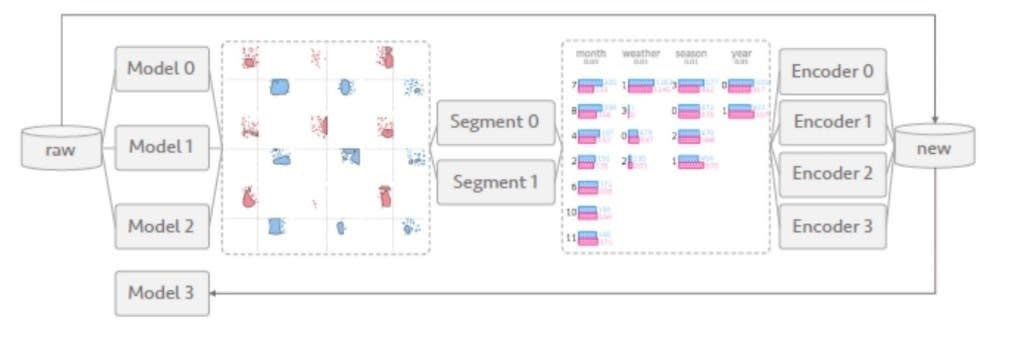
Manifold is not only a reference architecture, but it has also been implemented at scale at Uber. Furthermore, some of Manifold’s principles can be applied to many learning debugging processes.
🤖 ML Technology to Follow: Arize AI Enables the Foundation for ML Observability
Why should I know about this: Arize AI is one of the most innovative ML observability platforms in the market.
What is it: The rapid growth in the adoption of ML technologies has accelerated the number of ML monitoring platforms entering the space, making it one of the most crowded segments of the ML market. Despite the proliferation in ML monitoring stacks, ML observability remains in very early stages, with only a few platforms providing comprehensive solutions. Arize AI has been one of the platforms enabling end-to-end observability features in ML solutions.
As a platform, Arize AI provides a broader feature set than just ML observability, but it indeed excels in this area. The key innovation of Arize AI is its Evaluation Store that can be seen as an inference store optimized for data, feature, and model analysis across training, validation, and production datasets. The Evaluation Store powers the observability capabilities of the Arize AI platform key areas such as the following:
Model performance analysis and comparison across environments
Data drift analysis across different datasets
Prediction drift analysis without ground truth
Evaluation of model performance metrics against ground truth
Root cause, facet-based analysis of model, feature, data performance drift
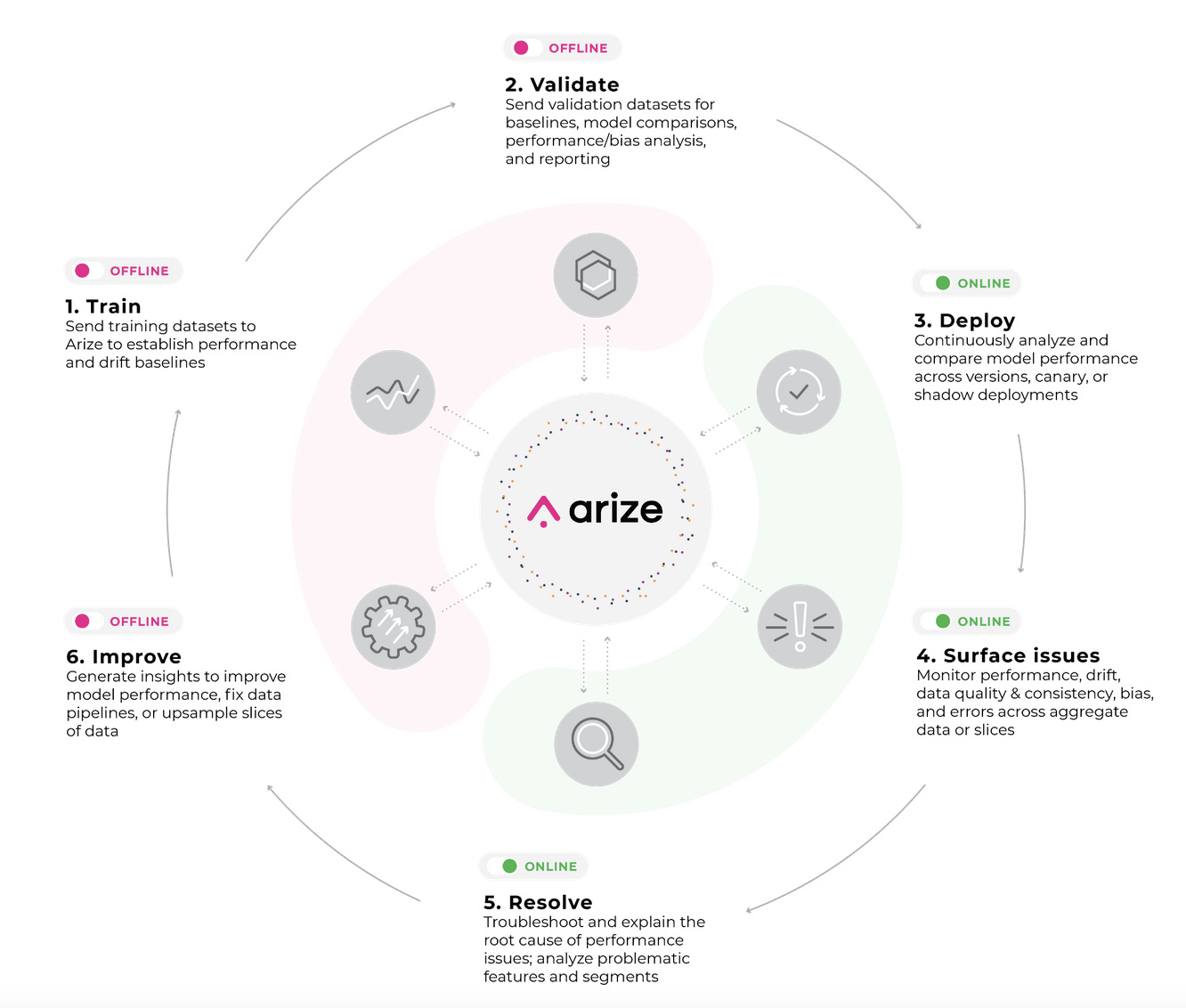
As ML evolves, the line between ML monitoring, interpretability, and observability is likely to become less relevant. However, there is a clear delineation between these types of capabilities in this early stage of the ML market. Arize AI is certainly one of the companies pioneering the adoption of observability best practices in ML pipelines. We will discuss Arize AI in more detail in the next issue of this newsletter.
