
🔵⚪️Edge#136: Kili Technology and Its Automated Data-Centric Training Platform
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. On Thursdays, we do deep dives into one of the freshest research papers or technology frameworks that is worth your attention. It helps you become smarter about ML and AI.
💥 What’s New in AI: Kili Technology Presents an Automated Data-Centric Training Platform
Data training is one of the fastest-growing segments of the machine learning (ML) market. Supervised models’ dependency in labeled datasets has made data training one of the key components of modern ML pipelines. As a result, there has been an explosion of data training platforms looking to automate the creation of labeled datasets as well as its integration in training pipelines. In such a crowded space, it's hard to determine signals from noise and identify platforms that have meaningful traction, ambitious roadmap, and strong financial backing to remain relevant in years to come. Today, we would like to discuss Kili Technology. This automated data-centric AI training platform has been flying under the radar but has steadily become one of the most important automated data training stacks on the market.
While AI has focused mostly on models, the real-world experience of those who put models into production shows that, most of the time, data is more important. When a system isn't working well, many teams instinctively try to improve the code, whereas, for many practical applications, it's more effective to focus on improving the data because the training data is the new code.
What is an Automated Data-Centric Training Platform?
Data-centric is defined by Stanford Professor Andrew Ng as the practice of systematically engineering the data used to build AI systems.
Kili is designed to serve this approach with two key features:
- the ability to control the consistency of the data. It offers three key features: quality indicators such as consensus or honeypot to assess the consistency of the annotated data at all levels (project, asset, labeler, annotation), instructions to align annotators on a common definition of truths and a review workflow to disambiguate conflicts.
- the ability to control the completeness of the data, i.e., build a training dataset iteratively as a collection of scenarios to be covered. On the one hand, it offers a search engine that allows fine-tuning of model quality parameters to identify data slices on which the model systematically underperforms and, on the other hand, annotation automation tools (e.g., interactive annotation) to quickly fill in the poorly covered data scenarios.
Kili Technology is a platform for automating the creation of high-quality training datasets for image, video, documents, time series, and voice datasets. Providing simple and easy-to-use user experiences for different datasets has been one of the main limitations of data labeling platforms. Kili addresses this limitation head-on by enabling a set of intuitive user experiences to automate data annotation tasks in a collaborative fashion. Additionally, Kili simplifies the end-to-end training data management process while enforcing robust access control and security policies. The startup has meaningful customer adoption with companies such as IBM, SAP, OVH and Blue Prism and recently raised a $25 million Series A.
Customer traction and funding are a great validation of a company, but the most important part is to evaluate the platform in its technical merits. Let's dive in.
Capabilities
A way to think about Kili Technology is as automation workflows for the two main stages of ML models: training and production. During the training phase, users create a project using Kili's web interface and upload their target datasets. Depending on the type of data they require to annotate (image, videos, text, audio), Kili will leverage user interfaces optimized for the specifics of that dataset. Using those interfaces, users can collaborate in the labeling process that culminates with the creation of the training dataset.
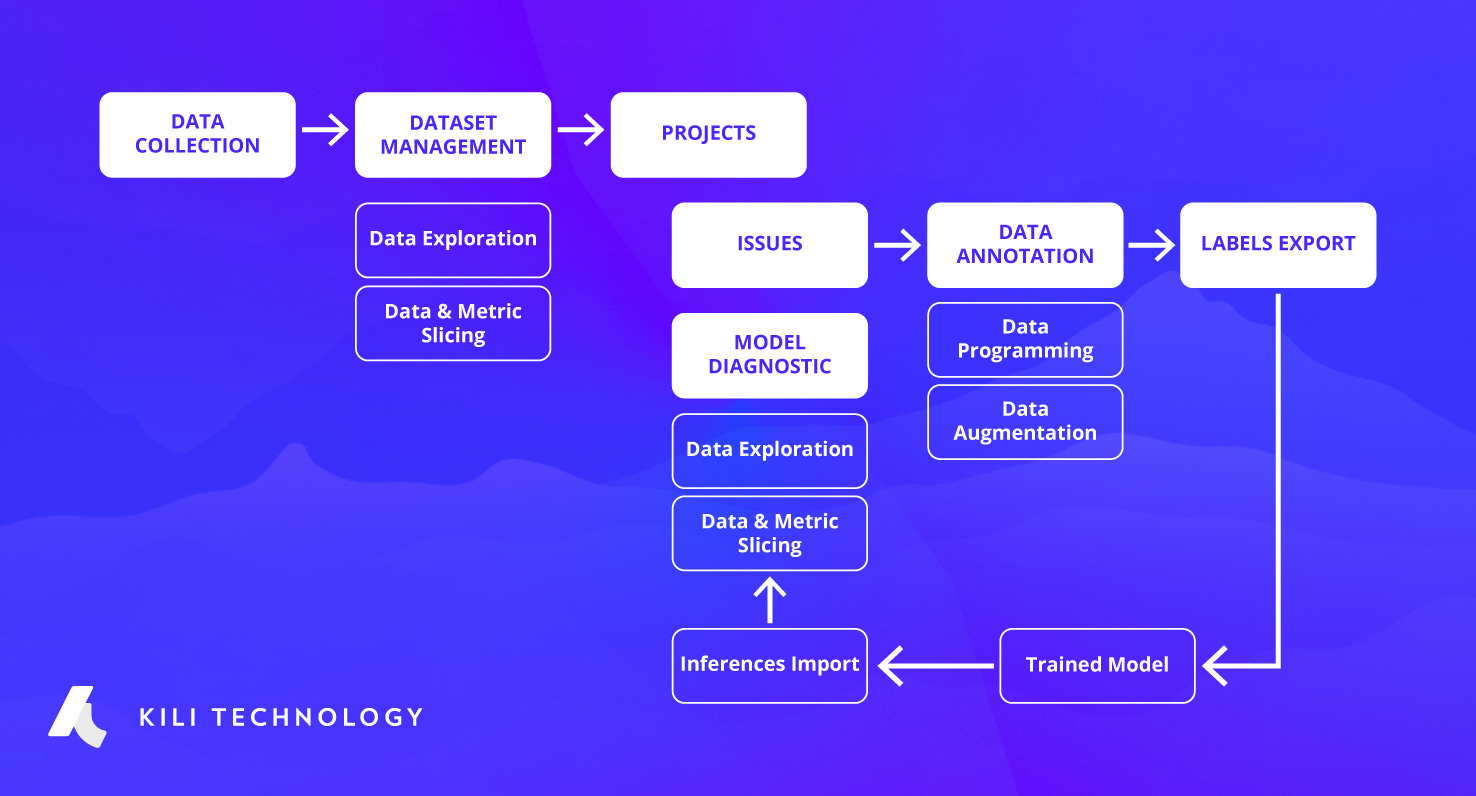
As a training data management tool, Kili fits into the MLOps value chain between upstream data storage and downstream model training.
It offers to:
1. explore a dataset and select the data to annotate
2. launch an annotation campaign within a project
3. export annotations to train a model
4. import the predictions of a model to diagnose them and create issues on the failure modes
6. correct these issues by remediation actions which can be a new annotation campaign or a data increase
Highly Versatile Platform
The previous workflows are complemented with a series of intuitive user experiences and tools that streamline labeling tasks for different types of datasets, such as the following:
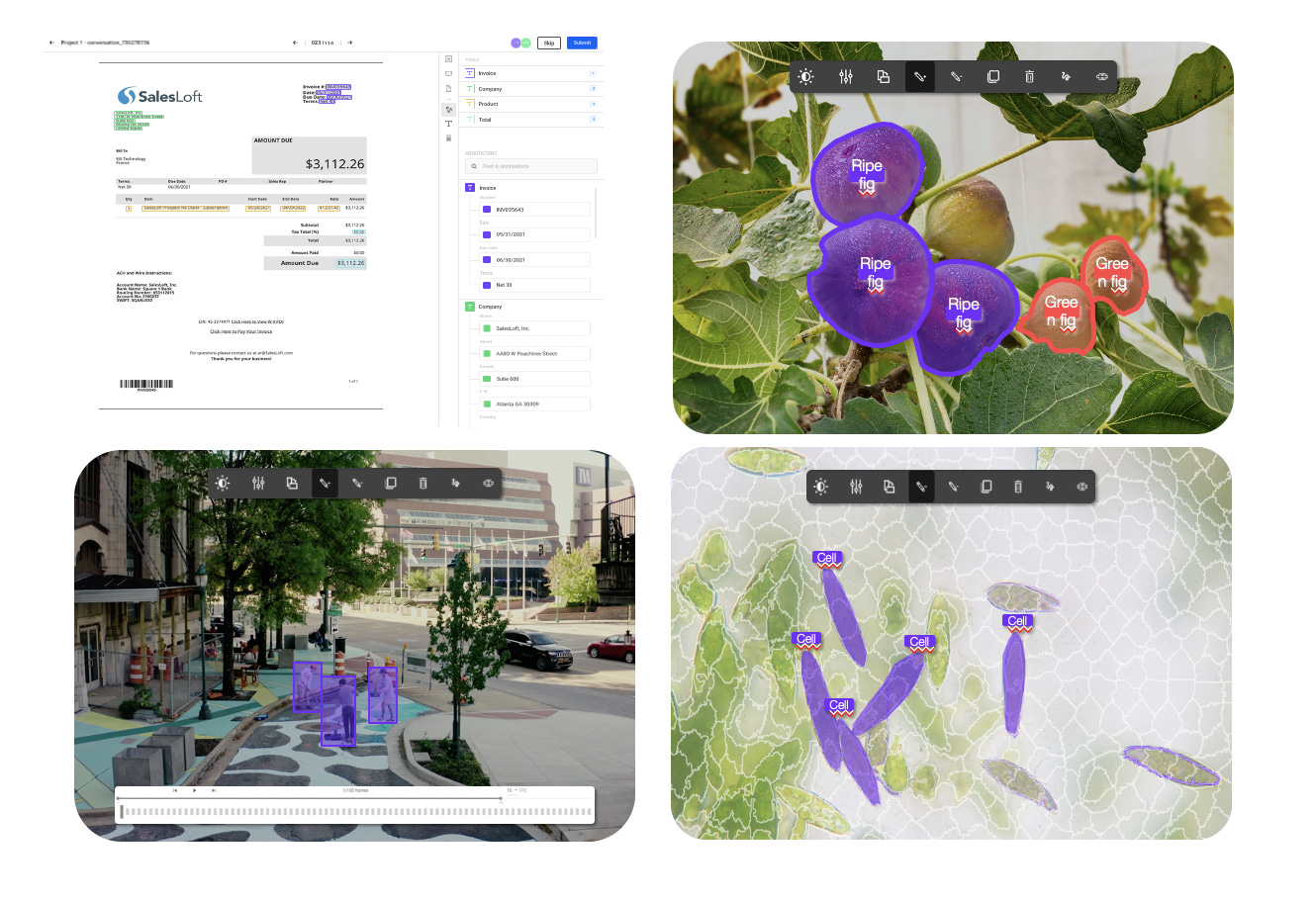
Image: includes tasks such as object recognition, segmentation, classification, transcription.
Text: automates tasks such as named entities recognition, relations extraction, classification, transcription.
Video: streamlines features such as transcription and classification.
Audio: similarly to video, includes tasks like transcription and classification.
Architecture
Powering the tools and workflows in the Kili Technology platform, there is an architecture that works in on-premise and cloud deployments. Here are a few interesting points about the Kili's architecture:
Kili organizes the assets of each data labeling workflow in units known as projects.
The definition of projects is stored in PostgreSQL fronted with a GraphQL API.
The datasets associated with specific projects are stored in file storage engines, such as Amazon S3, Azure Blob Storage and Google Cloud Storage.
Apache Airflow is the main orchestration engine used for data labeling jobs.
Authentication and access control are enabled via the Auth0 platform.
Kili Playground is the main programmable client interface to interact with the Kili platform.
This modern architecture allows Kili Technology to adapt to different infrastructures. The platform can be provisioned in a SaaS model using Google Cloud as well as on hybrid or on-premise models.
Kili Playground
One of the most interesting components of the Kili Technology architecture is the Kili Playground. Released as an open-source stack, Kili Playground is a Python library that abstracts the interaction with Kili’s GraphQL API making it easier for data scientists and machine learning engineers to build data labeling processes using a few lines of code.

Conclusion
Three years ago, the annotation market was embryonic. Today, the first end-to-end data-centric AI platforms are starting to appear. They allow to radically simplify annotation, better control the quality of the training data, iterate faster in training cycles, and ultimately complete AI projects 2-10 times faster. A flexible, modern architecture supporting state-of-the-art data labeling tools and workflows for audio, image, video and text datasets, together with meaningful customer traction and investor backing, are some of the factors making Kili one of the most relevant companies in this new area of machine learning.