🟠🟣 Edge#132: WhyLabs, AI Observability as a Service
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. On Thursdays, we do deep dives into one of the freshest research papers or technology frameworks that is worth your attention. It helps you become smarter about ML and AI.
💥 What’s New in AI: WhyLabs, AI Observability as a Service
MLOps, a term that didn’t exist two years ago, is one of the fastest-growing software categories of 2021. It happened with the shift in enterprise AI adoption: model post-deployment became the number one challenge enterprises face. In the past 18 months, hundreds of companies have stepped up to shape the newly emerging MLOps category. The new tools incorporate methods and features from best practices in DevOps. The entire CI/CD paradigm is being extended to build ML-specific analogs of testing, deployment, security, monitoring, and observability tools.
Concurrent with the explosion of MLOps tools, the AI community is experiencing an outbreak of concerns about the robustness and reliability of AI systems. The fact that AI systems are fickle and can lead to disasters when faced with real-world data has been well-known since the Tay bot faced Twitter in 2016. Challenges with operating AI in real-world environments occur daily, with the significant failures being captured in the ever-growing Partnership on AI incident database.
As soon as an AI application hits production, it directly impacts customer experiences and enterprise ROI. No matter how robust the model is, it will decay in performance as the real world around the model evolves and changes. A common approach has been to monitor model performance. However, by the time a model’s degradation is visible to its performance monitors, the damage to customer experience has been done. This is where AI Observability comes in. An AI Observability solution captures all possible signals about model and data health, both at the model inference stage, as well as upstream and downstream. Coupled with monitoring, observability is the mechanism for creating a feedback loop between the ML pipeline and human operators that builds trust and transparency.

Among such ML-first monitoring and observability solutions, WhyLabs stands out for achieving real traction and providing a complete feature set to enable observability in ML pipelines.
WhyLabs
WhyLabs Platform is an end-to-end AI observability and monitoring solution that enables transparency across the different stages of ML pipelines. The technology behind WhyLabs was incubated at the Allen Institute for Artificial Intelligence by a team of Amazon veterans who built the early iterations of AWS’s ML tools. The platform they built was shaped by their expertise in human-centered design, distributed systems, and developer tools. As pioneers of the category, the team believes in giving access to this technology to every practitioner. To achieve their mission, the WhyLabs team has:
Created and is maintaining the open standard for data logging, also known as whylogs;
Opened access to the WhyLabs Observability Platform to all practitioners with a free self-serve edition.
whylogs: The Open Standard for Data Logging
Today, WhyLabs is best known in the MLOps community for the open-source library called whylogs. The library is designed to enable a fundamental requirement in any software system: the process of logging. For ML systems, standard logging is insufficient because standard logs do not capture the most important aspect of the ML system – the data that powers the models. whylogs automatically creates statistical summaries of that data, called profiles, which emulate the logs produced by non-ML software applications. The library is privacy-preserving, running in a completely offline mode and never moves raw data for processing.
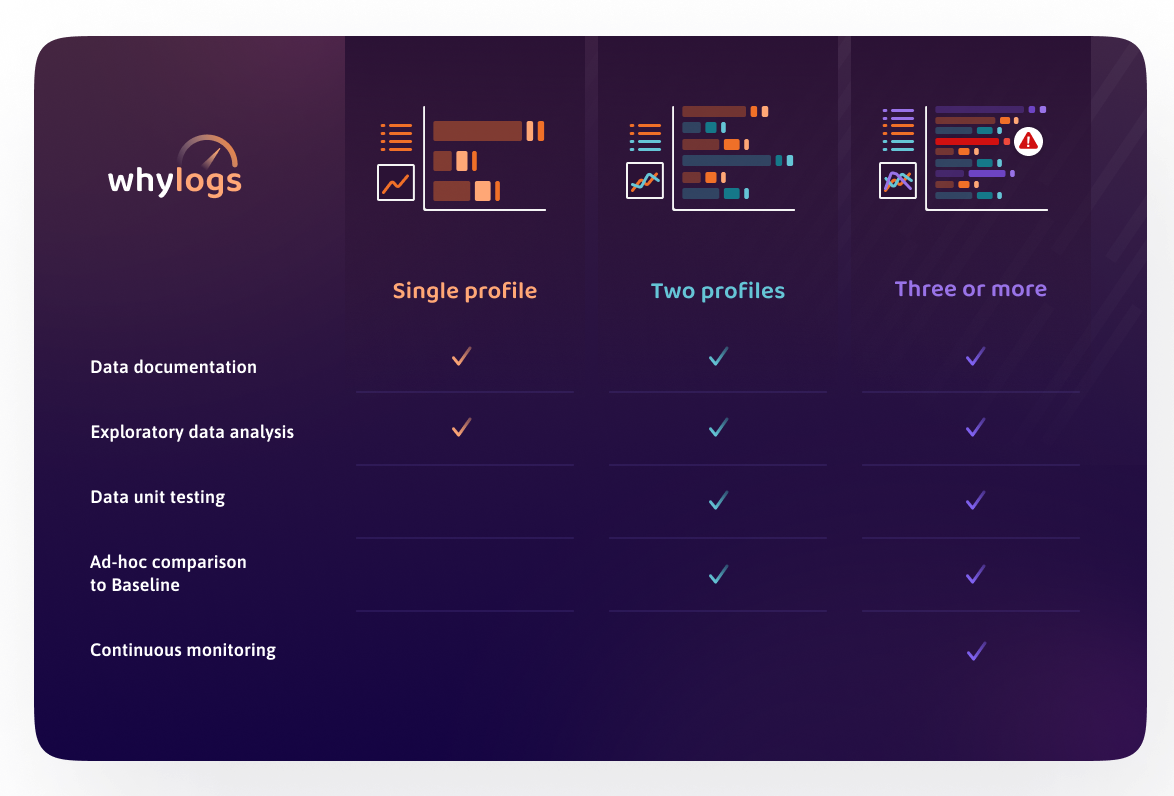
The whylogs library produces outputs that have a unique set of properties:
Descriptive: whylogs captures all essential statistical information about an ML dataset. The library enables users to capture statistics from both structured and unstructured data by offering default statistics per data type as well as the flexibility to define custom statistics.
Lightweight: the library runs in parallel with existing data workflows. It doesn’t require the user’s raw data to move anywhere for post-processing. All statistics are captured using stochastic streaming algorithms, so only one pass over the data is required, and the compute footprint of the library is minimal.
Mergeable: the resulting log files are mergeable with each other. In a distributed system, profiles can be captured on every instance and merged for a full view of the data. In streaming systems, profiles can be captured over a mini-batch and merged into hourly/daily/weekly snapshots of data without losing statistical accuracy. This is made possible through a technique called data sketching.
The library seamlessly integrates with a wide range of data and ML platforms. For those who are looking to dive deeper, the GitHub repository has tutorials for using whylogs to detect data drift in Kafka topics, profile TBs of data with Spark, create data unit tests with GitHub Actions, log image data, or even track data statistics across the model lifecycle with MLflow.
WhyLabs Platform for Everyone
The capabilities of the WhyLabs platform are powered by an underlying architecture that includes key components to enable model and data instrumentation, monitoring, and interpretability in ML pipelines. The platform is built on top of whylogs, which means that to integrate the WhyLabs Platform, users first set up whylogs on their ML or data pipeline. Such integration means that no raw data is ever captured by the platform, which is pretty great. All of its features operate on statistical profiles, which are the only data that leave a user’s system.
From a functional standpoint, WhyLabs enables a series of capabilities for streamlining the monitoring and observability of ML applications through a purpose-built user interface:
Model Health Monitoring: WhyLabs actively monitors the distribution of model predictions for concept drift, as well as a wide range of model performance metrics and any associated business KPIs.

Data Health Monitoring: One of our favorite features of the WhyLabs platform is data monitoring. WhyLabs users are notified early of any data drifts, training-serving skews, or data quality issues through this feature. Monitoring model inputs creates an early alert system that will notify model operators of deviations in data before they impact the customer experience. Alerts in model inputs can be correlated with the alerts in model outputs to speed up debugging.
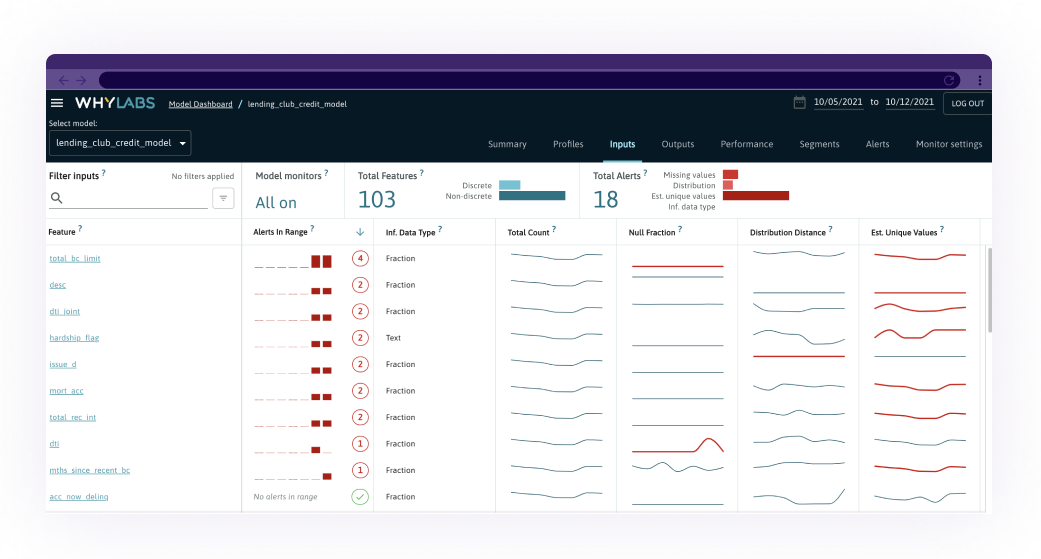
Zero maintenance: The WhyLabs team tries to make the platform one-click simple, from onboarding to experiences inside the platform. The user only needs a single line of code to capture all data statistics — no schema configurations. To deploy the platform, the user only needs to get an API key. To configure monitoring, the user only needs to specify a baseline from a drop-down. For expert users, YAML configurations and custom deployments are also available.
Privacy-preservation: Perhaps the most interesting aspect of the platform is that it operates only on statistical profiles of data. The raw data that flows through ML pipelines never leaves the workflow. This is key for every AI team since AI applications often run on highly proprietary data.
No data volume limits: Finally, the platform does not limit the number of data points or model predictions captured for monitoring. The platform uses whylogs to capture all statistical profiles, and whylogs process 100% of the data to capture the most accurate distributions.
Conclusion
Just like previous technology trends, the ML space is likely to spark the creation of a new generation of monitoring and observability solutions. WhyLabs is one of the ML observability platforms that achieved meaningful traction and opened up to the broad AI community as a SaaS. Starting with the whylogs open data logging standard and complemented by a rich set of enterprise-grade capabilities of the platform, WhyLabs provides essential mechanisms to instrument and gather insights into ML models' behavior.