
⚒ Edge#119: Data Labeling – Build vs. Buy vs. Customize
Contemplating on the choice one needs to make choosing a data labeling software
In this issue:
we discuss the topic “Data Labeling - Build vs. Buy vs. Customize”;
we explore how by identifying behaviors in previously labeled data we can build a pipeline to label the rest of the data;
we overview Label Studio.
💡 ML Concept of the Day: Data Labeling - Build vs. Buy vs. Customize
Data labeling is a regular topic in this newsletter. It is the first step in the machine learning development cycle and is constantly on the mind of any data scientist. Today we would like to discuss the aspect of building vs. buying a data labeling pipeline. ‘Build or buy’ is indeed an age-old debate in the software industry. It’s always a trade-off between building something for your exact need with unlimited features, in-house control, and compatibility vs. buying where you save on time, resources, and costs.
The build vs. buy debate certainly applies to data labeling. Many companies found themselves in a situation where they tried using the open-source tools available for labeling their data but had to move to build their own platform from scratch due to lack of options. Or buying commercial software and dealing with the downside when it doesn’t align perfectly with the internal processes. But what if instead of ‘buying’ or ‘building’ data labeling software, you could do both and leverage an open-source solution with in-built customization?
With data labeling being an essential element of any machine learning workflow, it was just a matter of time for some open-source tools to evolve and start offering necessary building blocks to fit different requirements better and provide a high degree of flexibility.
Like Sloth (for labeling image and video data), where the labeling styles could be changed from a Python configuration file, or Label Studio (for labeling image, video and audio), where customizing is as simple as using a bunch of XML tags.
There are a lot of challenges that data science teams come across when dealing with data labeling. So many that data labeling has already become a standalone and highly competitive market in the machine learning space. Though there is no one-tool-fits-all solution, it’s exciting to see the development of open-source tools that allow more flexibility. By nature of the concept, open-source solutions are easier to integrate into any workflow. Introducing customization options can alleviate the ‘buy’ vs. ‘build’ dilemma and significantly simplify the machine learning workflow.
🔎 ML Research You Should Know: Leveraging patterns in labelers behavior for automatic labeling
In the paper Automatically Labeling Low-Quality Content on Wikipedia by Leveraging Patterns in Editing Behaviors by the Computational HCI lab at the University of Michigan, the authors introduce how by identifying behaviors in previously labeled data we can build a pipeline to label the rest of the data.
The objective: Automated labeling of Wikipedia articles using previous edits.
Why is it so important: Wikipedia is an online encyclopedia and an ultimate source for high-quality knowledge, but despite this only 0.6% of Wikipedia articles have high-quality. Automating the labeling pipeline is an important step towards ensuring the quality of information available.
Diving deeper: To maintain the quality of Wikipedia's information and lower the load on manual editing, there is a necessity for automatic quality detection and control. In this paper, the authors present sentence-level quality detection, which works by learning from the behavior of editors who manually flag a sentence for improvement. The process of extracting the training data is divided into the following parts:
Identify the semantic intent. Rule-based approach with regular expression was used to identify Wikipedia edits on three semantic categories:
Citations ("add or modify references and citations; remove unverified text")
Point-of-View (POV) ("rewrite using encyclopedic, neutral tone; remove bias; apply due weight")
Clarifications ("specify or explain an existing fact or meaning by example or discussion without adding new information").
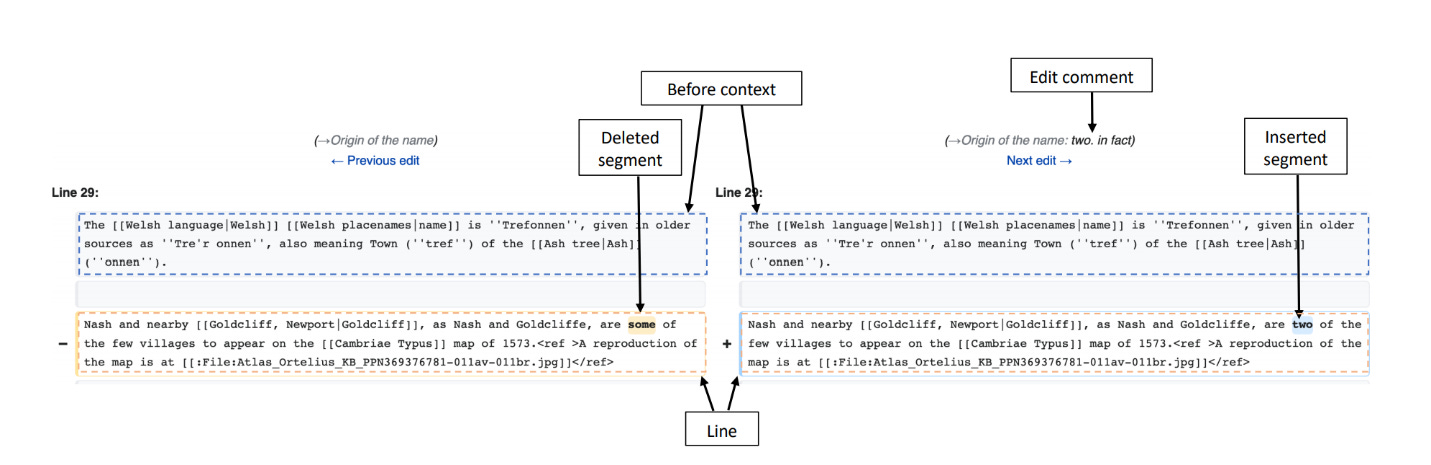
Division of Data. The data is divided into two sets for training:
Negative samples. Sentences that do not need improvement. These are the sentences from articles that have already been ‘featured’ on Wikipedia (with the underlying assumption that those articles do not require an improvement).
Positive samples. Sentences that need improvement. (Through the identified semantic intent)

For training, the model Gated Recurrent Unit (GRU) with global attention was used. GloVe word embeddings were used to represent each word along with their Part of speech tags given as an input to the model.
Evaluation. For evaluation, the ground truth labels were obtained from the Wikipedia editors. A custom data labeling platform was built to label the sentences of the articles. The evaluation was done on:
Effectiveness of automated rules. The rules for the extracted positive and negative samples were evaluated by comparing them to the ground truth. The highest precision and recall were achieved on citations.
Understand the variance of choices made by Wikipedia editors. Krippendorff alpha was used to calculate the inter-annotator agreement with more than two raters. The numbers were 0.59,0.02,0.017 for citations, point of view and clarifications. Indicating medium agreement for citations but low or no agreement for the other two categories.
Sentence quality labels. Precision and recall of the different edits were reported.
This approach gives a new direction to data labeling where we can leverage the patterns of grading manually to further label our data.
🙌 Let’s connect
Follow us on Twitter. We share useful information, events, educational materials, and informative threads that help you strengthen your knowledge about ML and AI.
🤖 ML Technology to Follow: Label Studio – Open-Source Software With Customization
Why should I know about this: Label Studio is an open-source data labeling tool for multiple types of data labeling with ‘build your own customizations.’
What is it: Label Studio is a collaborative, easy-to-install (with Docker or pip) data labeling platform. It is built using React and MST at the front end and Python as the backend. It can be accessed from any web browser and even embedded in personal applications. It comes with several default configurations for labeling NLP, Computer Vision, Audio Transcription, and several other use cases. It can also be used for conversational AI data (sequential and skip) labeling, ranking & scoring, and data parsing. Importing the data is a simple drag and drop, with multiple templates available for every category:

For designing your custom template, there are XML-like tags. The tags can be of the three types:
Object tags. Data sources: Image, Text, Audio;
Control tags. To label the objects: Labels, Choices, Rating, Text area;
Visual tags. Non-interactive elements are used to add some additional meta-data that can enrich the information of a specific dataset.
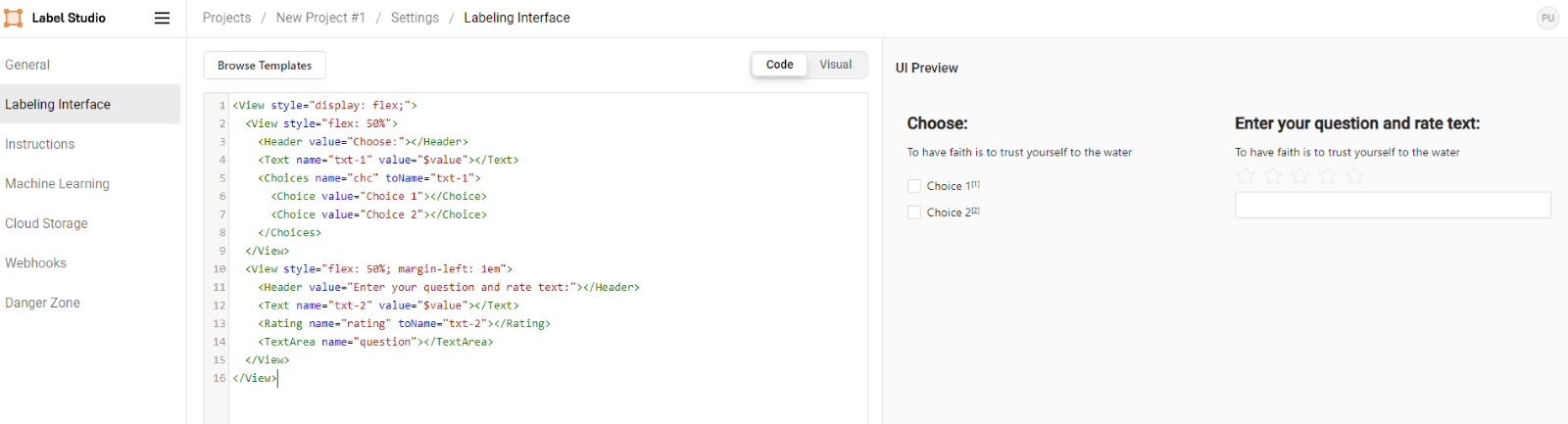
The view tag also supports CSS styles hence allowing customized visual representation. The given image is an example of a two-column labeling interface with multiple control elements. There are ways you can add instructions, ML models, webhooks, and even cloud storage to your custom project.
There are three versions for the software – community, teams, and enterprise.
Community is the open-source version, teams for the smaller organizations and enterprise for teams with robust data labeling needs. It’s easy to start with the open-source version and, if it feels like a good fit, eventually move to Teams or Enterprise version for your organization.
Further Information: More information can be found on their GitHub: https://github.com/heartexlabs/label-studio