
Edge 273: Horizontal Federated Learning
Horizontal federated learning, Google’s research on personalized federated learning Syft framework.

In this issue:
The principles of horizontal federated learning.
Google’s research on personalized federated learning.
The Syft framework.
💡 ML Concept of the Day: Understanding Horizontal Federated Learning
In the previous edition of this series, we introduced a taxonomy to understand the different types of federated learning architectures. Today, we would like to dive into one of the most relevant architectures in that taxonomy: horizontal federal learning(HFL).
Conceptually, HFL is a type of architecture in which the datasets distributed across all nodes in the federation share the same feature space but different sample space. For instance, imagine a federated learning model applied to a group of social networks or blogging platforms. While the feature set of the dataset is relatively identical, there might be very small interception points across the sample based. Not surprisingly HFL is also known as sample-based federated learning or homogeneous federated learning.

Google’s architecture proposed in the original federated learning paper could be considered HFL as the feature space across the different Android users was common but the users were obviously different. HFL architectures typically consists of large number of nodes that produce different types of updates in terms of volumes or data distribution. Those results are aggregated by a centralized server and the updates distributed back to the nodes. One of the interesting architectures derived from HFL is known as multi-task federated learning in which different nodes are optimized to master different tasks and share the updates with the rest of the federation.
🔎 ML Research You Should Know About: Personalized Federated Learning
In “Federated Reconstruction: Partially Local Federated Learning”, researchers from Google Brain proposes partially local federated learning which enables personalizing models at the node level.
The objective: Google’s research enables the use of a global model in a federated learning architecture with tailored modifications for specific nodes.
Why it is so important? The method unveiled in this research addresses one of the most important privacy challenges in federated learning architectures and has been applied at scale in platforms like GBoard.
Diving Deeper: Most federated learning architectures relied on training a global model based on the parameters captured by different nodes in a federation. However, in many scenarios, there are strong privacy considerations that prohibit learning a fully global model. For instance, many recommendation systems might require access to individual user’s embeddings for training which might not be an option in different privacy settings.
In their research, Google pioneered a method known as federated reconstruction that avoids sharing a subset of sensitive parameters with the centralized server. The key contribution of the federated reconstruction technique is that it avoids storing the parameters locally and, instead, it can reconstruct them whenever required. During training, the global parameters are sent to each node which “freezes ” that dataset and infers the local parameters using gradient descent. After that they can update the global parameters using a frozen representation of the local parameters. The following picture illustrates a round of the federated reconstruction algorithm.

Google’s applied the federated reconstruction algorithm in several large scale system such as GBoard. In that specific setting, federated reconstruction was used in a matrix factorization model keeping the user’s embeddings locally. The method was applied across hundreds of millions of users with impressive results.
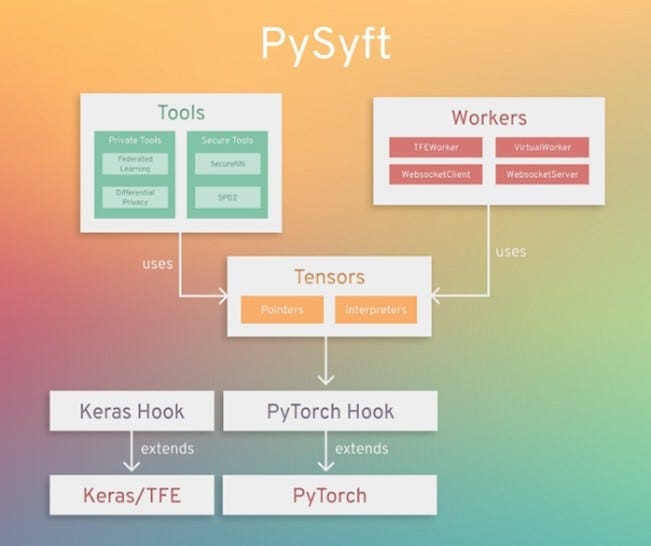
🤖 ML Technology to Follow: Syft Combines Federated Learning and Privacy in a Single Framework
Why should I know about this: Syft is one of the most advanced frameworks in the market for building private federated learning models.
What is it: Syft is a framework that enables secured, private computations in federated learning models. Syft combines several privacy techniques such as federated learning, secured multiple-party computations and differential privacy in a single programming model integrated into different deep learning frameworks such as PyTorch, Keras or TensorFlow. The principles of Syft were originally outlined in a research paper and were then implemented in its open source release. In simple terms, Syft allows to query a dataset within strong privacy boundaries.
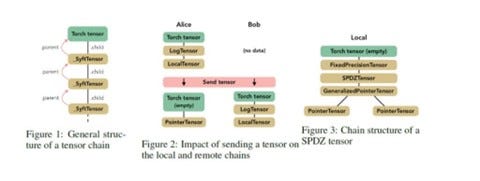
The core component of Syft is an abstraction called the SyftTensor. SyftTensors are meant to represent a state or transformation of the data and can be chained together. The chain structure always has at its head the PyTorch tensor, and the transformations or states embodied by the SyftTensors are accessed downward using the child attribute and upward using the parent attribute.
Syft rich collection of privacy technique represent a unique differentiator but even more impressive is its simple programming model. Incorporating Syft into models in Keras or PyTorch is relatively seamless and it doesn’t require deviating from the core structure of the program. Is not a surprise that Syft has been widely adopted within the deep learning community and integrated into many frameworks and platforms.
How can I use it: Syft is open source and available at https://github.com/OpenMined/Syft