


🎙 Iskandar Sitdikov/Provectus: Healthcare has it all: NLP, computer vision, recommendations, and a whole lot more
TheSequence interviews ML practitioners to merge you into the real world of machine learning and artificial intelligence
There is nothing more inspiring than to learn from practitioners. Getting to know the experience gained by researchers, engineers and entrepreneurs doing real ML work can become a great source of insights and inspiration. Please share this interview if you find it enriching. No subscription is needed.

👤 Quick bio / Iskandar Sitdikov
Tell us a bit about yourself. Your background, current role and how did you get started in machine learning?
Iskandar Sitdikov (IS): I am Principal AI/ML Solutions Architect at Provectus. I lead ML/MLOps and research efforts for the company and a number of clients ranging from healthcare to adtech.
My first degree was management, but I quickly realized that I want to take an applied sciences path, so I got my bachelor's in mathematics and my master's in computer science.
I actually remember the moment I got interested in ML. It was about 2010 and I was talking to my professor and a classmate, and the topic of artificial neural networks popped up in our conversation. And after dozens of projects, conferences, and meetups I am talking to you right now.
🛠 ML Work
Provectus works with large organizations helping to incorporate ML as part of their digital infrastructure. What are the main challenges that organizations encounter when starting to build ML solutions in real world environments?
IS: That is a complex question, and the answer is multifaceted. Simply building a model is not enough. Since models are the very important components of larger systems, their requirements should be the same, and even more so given the specifics of the machine learning domain.
We need to understand the models’ behavior and be able to experiment and keep a record of all actions executed by the models – what we call the ML environment. There are two main challenges when building such environment:
Selecting the right tools for building the environment;
Fostering an engineering culture for using tools in ML/data science teams. This could result in a big learning curve, primarily because the concepts of environment components are still maturing, and not all ML specialists have enough experience with them.
Also, environments are not built in a vacuum; they rely on existing infrastructures. Some of them are still in a nascent stage. What matters here is how the data gets into the system, and how it is processed, stored, cataloged, and discovered.
There is a wide and growing gap between machine learning research and practical applications in the current market and many of the techniques that are published in research papers are simply not practical in real-world applications. What are some of the things data science teams should consider when trying to adopt cutting edge ML research methods in practical applications?
IS: The beauty and shortcoming of research are that it does not have to be linked to real-world applications. The main thing is to continue generating ideas and discussing them in research articles. This is how we build the legacy of our industry.
Not all ideas will get recognition, but certain ideas will generate others, fueling an ongoing evolution in technology. Reading papers and experimenting can give you a new perspective on an existing problem and help you solve it. Neural networks are a good example. At the time this technique was created, it wasn't directly applicable to real-world situations.
All industries have their unique laws. We have deadlines, KPIs, ROIs, and other standard metrics used in business, but that doesn't mean we should follow a single well-trodden path. We need to be a little more cunning, experiment more, collect metrics and track everything. We need to add new developments to robust proven methods and test them against existing options. It’s important to share the findings and experimental methods as open-source projects.
Our advice is to experiment with new methods, but conduct the experiments in a controlled manner, using a carefully created environment.
Provectus seems to do a lot of work in the healthcare space, which I consider one of the most fascinating environments for ML solutions. What makes healthcare so unique and challenging when comes to ML solutions?
IS: I love the healthcare industry because it has a direct impact on people's lives. But its unique role is also its biggest challenge. We all know the Peter Parker principle – with great power comes great responsibility – and it applies perfectly to healthcare. Mistakes in healthcare are often costly, so the requirements for high-quality and robust solutions are much higher.
There is also a perception of ML models as black boxes, and this in part prevents machine learning from making its way into highly regulated areas like healthcare. Breaking down these barriers is partly resolved by innovations that allow us to "explain" what is going on inside models, and why they behave as they do.
Computer vision seems to dominate the headlines when comes to ML solutions in healthcare. What are other areas of ML that are gaining rapid adoption in healthcare environments?
IS: It's true, computer vision does occupy a large field in healthcare. A lot of procedures in medicine rely on the visual inspection of images. These images can be retinal scans or CT-scans of the lungs, where the main task is to classify diseases or highlight malignant areas. As it happens, we have learned how to execute these tasks with machine learning. Read this case study to learn how: ML Helps Combat Preventable Vision Loss in Infants.
Document processing is another growing concern in healthcare. In fact, it is one of the largest tasks the industry has encountered to date. Document processing encompasses multiple disciplines, including ML, automation, human interaction interfaces, and others.
For example, medical report processing involves digitization of the document, its direct processing via machine learning tasks like recognition of texts, tables, forms, and images, and human-in-the-loop for continuous verification, storage, and integration.

Machine learning tasks for a single medical report would include OCR (fetching text), NLP (semantic understanding for data extraction from raw text data, ontology mapping, etc.), and object detection/segmentation (for medical images in the report). So, to answer your question, healthcare has it all: NLP, computer vision, recommendations, and a whole lot more. Watch this webcast to learn what it takes to Choose the Right Document Processing Solution for Healthcare.

There are many aspects of ML solutions such as model compression, model serving or real-time model execution that are often ignored until it's too late. In your experience, what are the top 3-5 practical components of modern ML solutions that most data science teams tend to overlook?
IS: Lack of market research is a big one. Whether you are building your own solution or want to buy an existing solution, you need quality market research. If you are building a custom solution, you have to consider its advantages and disadvantages compared to similar solutions already on the market. Forrester and Gartner do a great job in outlining markets, but you need to dig deeper and gather specific evaluation metrics for your use case. For example, how Google’s computer vision products are compared to yours in terms of accuracy of extraction information from images.
MLOps elements are key in ML solutions. Aspects such as model monitoring, experimentation tracking, deployment are frequently overlooked by many companies. To make your solution transparent, reproducible, and understandable for everyone and empower parallel exploration of multiple use cases you must check those boxes. Watch this webcast to learn more about MLOps and Deploying Reliable ML Models in Production.
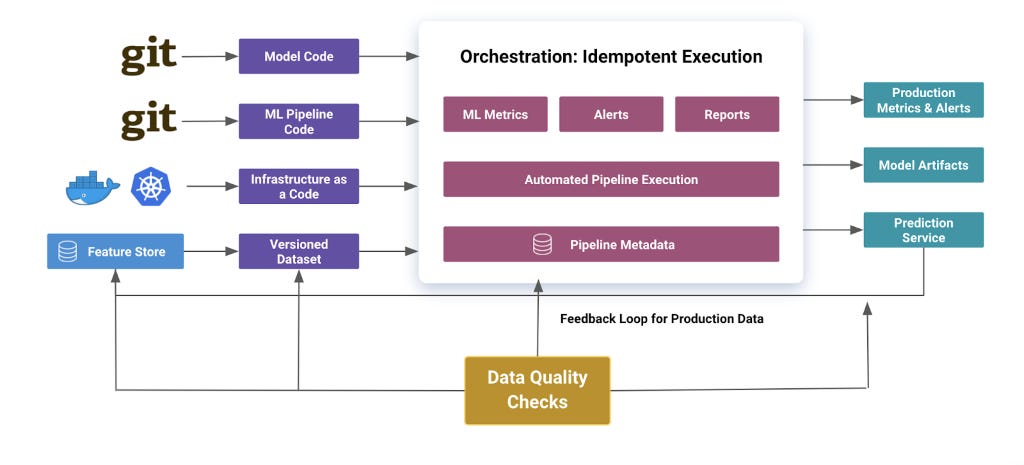
Documentation is critical. This is one of the most important aspects of any ML project. ML straddles on the border between software engineering and research, so you need to make extra efforts to preserve information about how to run your model while also explain the methodology behind it. And as always, follow engineering best practices; it will never hurt anyone.
Subscribing, you support TheSequence’s mission to simplify AI education, one newsletter at a time. You can also give the subscription as a gift.
💥 Miscellaneous – a set of rapid-fire questions
Is the Turing Test still relevant? Is there a better alternative?
IS: I think, it is still relevant, but with some modifications. We can call a modified version an alternative, but I prefer to respect the author by calling the ultimate AI test a Turing test :)
Favorite math paradox?
IS: Since we are talking about Turing, let’s pick the Turing paradox also known as the Quantum Zeno effect. It is an effect when you can “arrest” the time evolution of particles by measuring them. Technically, it is physics, but to me, math and physics are a dynamic duo.
Any book you would recommend to aspiring data scientists?
IS: “Linear Algebra and Analytic Geometry” by Ilyin and Kim, which is one of the first books you study as a mathematics faculty student at Moscow State University.
Third time for Turing, I guess. Try “Computing Machinery and Intelligence” by Alan Turing if you feel philosophical today.
Overall, I think you should read as much literature on the sciences as possible. Some of it will fit your perceptions, and some will challenge them.
Is P equals NP?
A million-dollar question! For now, only Gregori Perelman is qualified to answer those types of questions ;)