
📝 Guest post: The Original Open Source Feature Store - Hopsworks*
In TheSequence Guest Post our partners explain in detail what machine learning (ML) challenges they help deal with. This article reintroduces the core concepts of a Feature Store; the dual storage logic (online and offline) and how data scientists and ML practitioners can use APIs to establish a DevOps process for feature pipelines.
Intro
Feature stores for machine learning have become a key piece of data infrastructure for putting models in production. As with all key data infrastructure, there is demand for open source feature stores, and Feast has gained much attention as a framework for building your own feature store. But, if you need an open-source feature store that, out of the box, comes with its own offline and online stores, a user interface, enterprise-level security, high availability, and scalability, Hopsworks might be what you are looking for.
Stand Alone Feature Store

Hopsworks is widely used as a stand-alone feature store. A feature store provides Offline and Online Stores for large volumes of historical feature values and real-time access for current feature values. A feature store also provides an API for creating, reading, updating, and deleting feature values, and retrieving training data and feature vectors.
Offline Store
Hopsworks comes with its own offline store, based on Apache Hudi, but you can also use your own data warehouse/lake as an offline store. The offline store contains historical feature values and is used to create training data and provide features for offline batch scoring. Features stored in Hudi are known as cached features, while features stored in external stores are known as on-demand features, and the Hopsworks offline feature store can have a mix of cached and on-demand features. Maybe you already have all of your features in Snowflake or Redshift or Delta Lake, then you just need to mount them in Hopsworks as on-demand features. Or maybe you prefer the low-cost, high-performance cached features, that are stored in object stores in the cloud (S3, ADSL, GCS) or on commodity servers on-premises using the award-winning, HDFS-compatible, HopsFS file system.
Online Store
Hopsworks online feature store is built on RonDB, the only database optimized for feature store use cases. The online store contains the latest feature values and is used to provide feature vectors to deployed models at runtime. Any historical or context data that is used by your models to make predictions is typically stored as pre-engineered features in the online store, and retrieved using entity ids. For example, you might retrieve a customer’s recent history using a customer or session ID.
Hopsworks Online Store provides sub-millisecond feature vector lookups, high throughput (scales to 10s of millions of reads or writes per second), high availability (with 7 nines availability in the telecom space), disaster recovery, elastic scalability, and MySQL support.
The Hopsworks Feature Store (HSFS) API
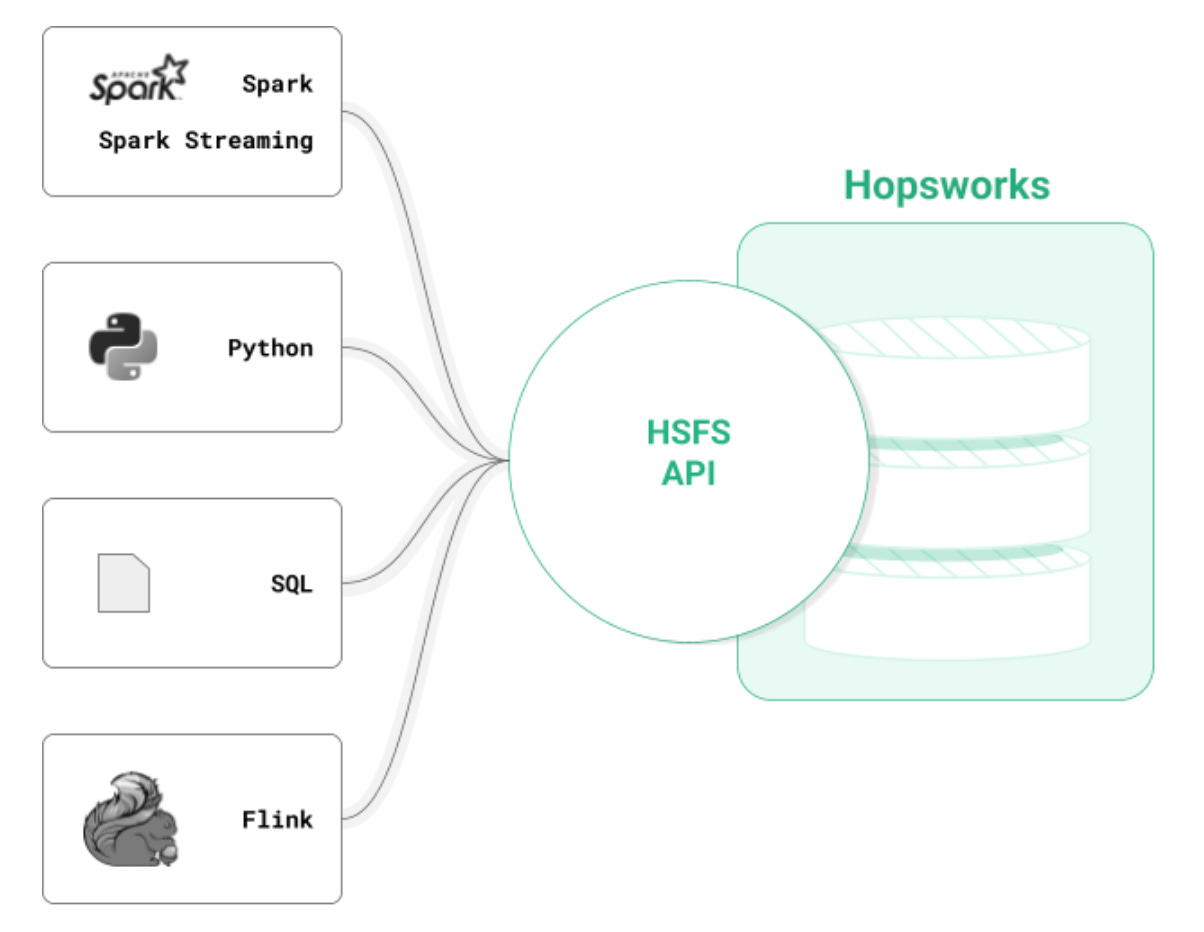
You interact with the Hopsworks Feature Store using the Hopsworks Feature Store (HSFS) API, with implementations in Python, PySpark, and Spark (Scala and SQL). For programs that run outside Hopsworks, you need to know the endpoint for Hopsworks, which feature store you are connecting to, and an API key to be able to connect.
Python developers can create features in Pandas and write the Dataframe directly to the feature store. You can create training data by joining features together with Pandas-like commands, ensuring point-in-time correctness.
When you have a deployed model, you can retrieve individual feature vectors from the feature store with a Python or Scala method call.
If you have large volumes of data, you can use Spark to engineer your features and write them to the feature store as dataframes. If your features reside in a table in an external data warehouse or data lake, like Snowflake or Parquet on S3, respectively, you can use SQL to compute your features as aggregations. And if you need very fresh features, you can use Spark Streaming or Flink to compute your features on real-time data,
HSFS provides a data-scientist-friendly Python API to create training data by joining features together (with no data leakage), filtering feature values, and applying transformations on features from the feature store before they are returned as training data. The transformation functions, defined in Python, are re-used both to create training data to transform feature vectors retrieved with the Online API when serving a model online.
DevOps for Feature Pipelines
One of the challenges in writing feature pipelines is testing both the feature computation logic and also validating the data that passes through the pipeline. The HSFS API enables you to develop your features on any Python or Spark environment, and test those features in a local development environment as well as test them with a continuous integration platform, like Github Actions or Jenkins. Feature pipelines commonly include three different types of tests:
unit tests of feature logic;
data validation tests to ensure features are correct and complete;
and end-to-end integration tests that ensure data is written correctly to the feature store and tests for feature drift work correctly.

Open Source Installation
Hopsworks consists of a number of open-source services, including HopsFS, RonDB/MySQL, Apache Spark, Apache Flink, Conda, Docker, Apache Hive, OpenSearch, Kafka, Prometheus, and Grafana. The recommended way to install Hopsworks is with a bash script that downloads all the software and configures the services. Hopsworks currently runs on Linux (Ubuntu, RHEL/Centos). If you have access to GCP or Azure command-line utilities, and you have privileges to create virtual machines, you can also create the virtual machines and install the platform in a single script. This script also allows you to stop, start, and suspend (GCP-only) your Hopsworks cluster, so you only pay for the compute you use.
Managed Platform
Like most open-source projects, Hopsworks is also available as a managed platform on AWS, Azure, and soon GCP at www.hopsworks.ai. It is the quickest way to get started and try out Hopsworks.