
📝 Guest post: It's Time to Use Semi-Supervised Learning for Your CV models*
In this article, Masterful AI’s team suggests that instead of throwing more training data at a deep learning model, one should consider semi-supervised learning (SSL) to unlock the information in unlabeled data.
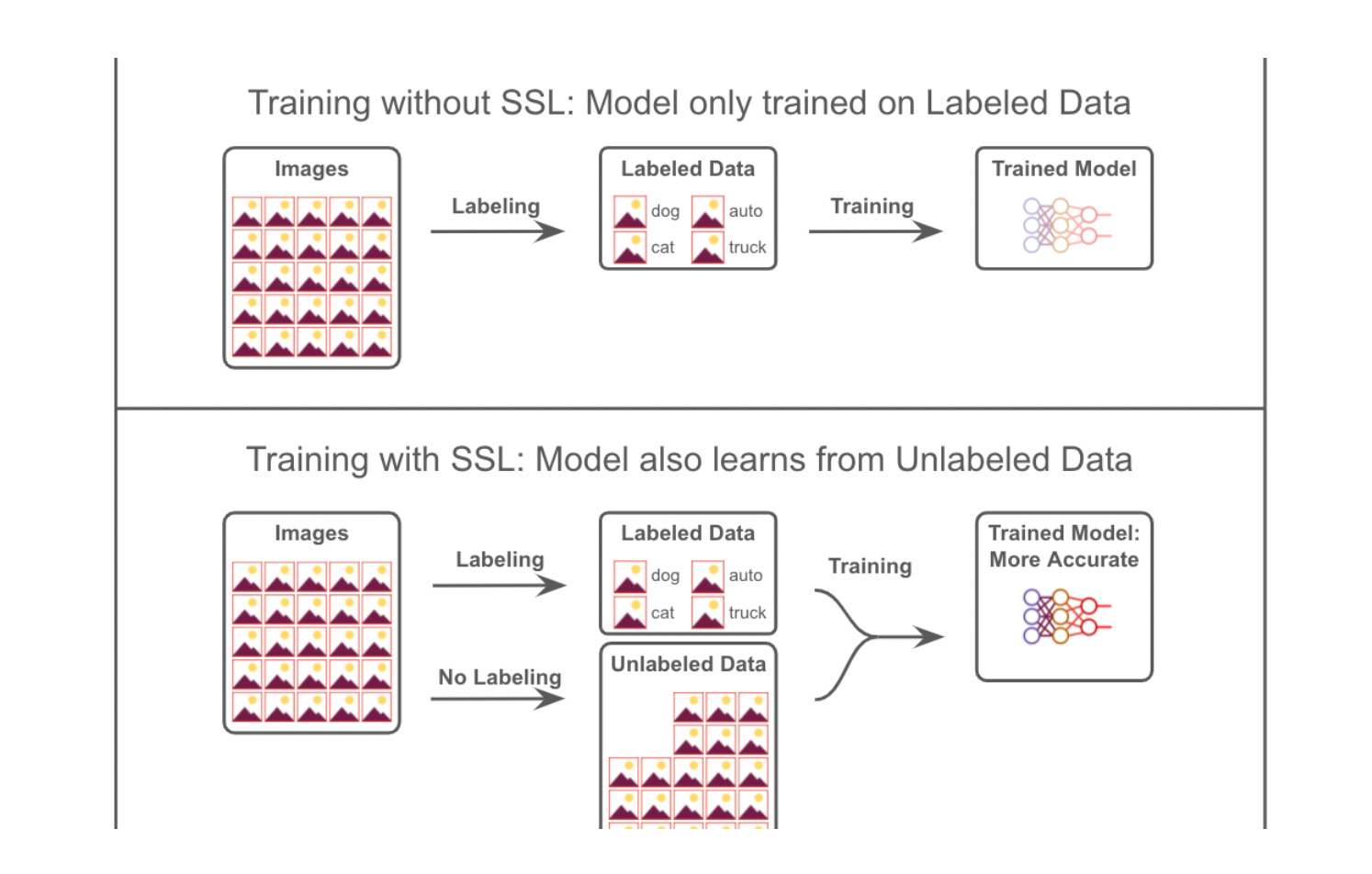
Intro
Previously, we showed that throwing more training data at a deep learning model has rapidly diminishing returns. If doubling your labeling budget won’t move the needle, what to do next?
Try SSL
Semi-supervised learning (SSL) means learning from both labeled and unlabeled data. First, make sure you are getting the most out of your labeled data. Try a bigger model architecture and tune your regularization hyperparameters. (plug alert: executing on these two steps is hard, and the Masterful platform can help you). Once you have a big enough model architecture and optimal regularization hyperparameters, the limiting factor is now information. An even bigger, more regularized model won’t deliver better results until you train with more information.
No more labeling budget but need more information?
But wait – it seems like we are stuck between a rock and a hard place. There’s no more labeling budget and yet the model needs information. How do we resolve this? The key insight: labeling is not your only source of information... unlabeled data also has information! Semi-supervised learning is the key to unlocking the information in unlabeled data.
SSL is great because there is usually a lot more unlabeled data than labeled, especially once you deploy into production. Avoiding labeling also means avoiding the time, cost, and effort of labeling.
Is SSL Good Enough?
SSL has been an academic topic for decades. But until about 18 months ago, it did not outperform traditional techniques for CV on standard benchmarks. All that changed with a series of papers published in 2020 and 2021, including Unsupervised Data Augmentation, Noisy Student Training, SimCLR, and Barlow Twins. Today, SSL techniques are responsible for training the most accurate convolutional neural networks (convnets). And transformers are also primarily trained using SSL techniques, in case someday transformers replace convnets as the workhorse CV architecture.
How SSL Works
An Algorithmic View
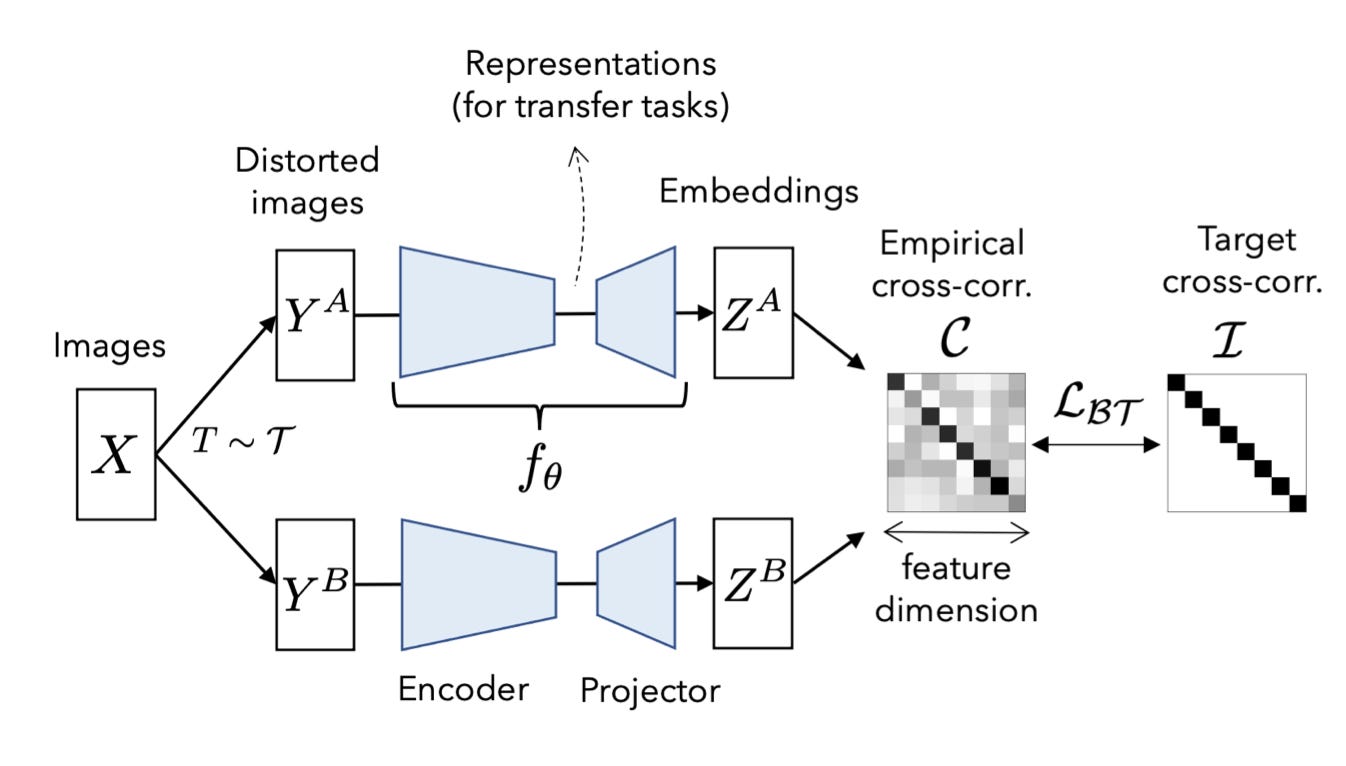
There are a lot of SSL algorithms, but most of the recent approaches loosely share these attributes:
Strong noise to make the two versions from the same source data.
The same model architecture is called on each version of the data.
The outputs of the model are used to solve a special problem.
Training a model on that special problem also improves the model accuracy at inference time.
The special problem can be making the pair of outputs consistent with each other. Or using the pair of outputs to solve a pretextual problem, like contrasting between pairs of images, that either do come from the same source image or don't. Sometimes the final output of the model is used, and sometimes a feature embedding. Some algorithms place additional layers between the features and the loss function, while others feed the outputs to the loss function directly. And different techniques work better for low-shot data vs high cardinalities. Most techniques require two training phases, and sometimes the weights of the two models are shared while in other approaches, one model slowly receives weights from the other. Here are a few great walkthroughs by Spyros Gidaris of Valeo.ai and Thang Luong of Google.
An Intuitive View

An intuitive view of how these algorithms work focuses on clustering the feature embeddings.
In concrete terms, the feature embedding is often the output of the penultimate layer of a convnet before the final linear/dense/logistic layer. For algorithms that directly train consistency, differently noised views of the same image must generate similar embeddings.
If the feature embeddings are clustered together in the high-dimensional feature embedding space, the feature extractor has learned a useful representation of the data.
If the noising function is able to move one image into the feature embedding space of another image, then it's also true that two different images now generate similar feature embeddings. This suggests that the noising function's goal isn't to be confusing, but rather, to transform a single image enough to collide with the feature embedding of other images in the same class, but not so far as to push it to collide with the feature embeddings of images from different classes. Indeed, when projecting the feature embeddings of one SSL algorithm, we see well-clustered feature embeddings.
One place to start: research repos
If you want to try these approaches, VISSL from Meta AI and Tensorflow Similarity are two solid repos to start with for PyTorch and Tensorflow respectively. We've worked with both and they are awesome! But like any research repo, they are focused on experimentation, not production. You really have to understand the papers behind them to understand the code, they may not be robust on production datasets, and many hyperparameters will require manual guessing and checking. If you are looking for a productized implementation, consider Masterful.
Three ways to access SSL via the Masterful platform
The Masterful platform for training CV models offers three ways to train with SSL.
First, in the full platform (plug alert: free, full-featured use for personal, academic, or commercial evaluation purposes), the `masterful.training.train()` function implement an SSL technique that allows you to run both supervised training and improve your model using unlabeled data in a single training function. Our CIFAR-10 benchmark report shows a reduction in error rate from 0.28 to 0.22 using unlabeled data.
Second, we include a function, `masterful.ssl.learn_representations()`, to help you pretrain a feature extractor. Once your feature extractor is trained, attach your classification / segmentation / detection head and fine-tune using the Masterful training loop with built-in fine-tuning, or, use your own fine-tuning setup. By starting with these weights instead of Xavier Glorot / Kaiming He weights, you can get better final accuracy, especially in low-shot scenarios.
Finally, we have a recipe that lets you train with your existing training loop and regularization scheme. This is a quick way to get started with SSL. Use the helper function `masterful.ssl.analyze_data_then_save_to(unlabeled_data, labeled_data)` to analyze your datasets and save the analysis to disk. Then `masterful.load_from()` to return a tf.data.Dataset object you can pass to your training loop. Check out the guide here.
Good luck on your journey with SSL! Join Masterful AI slack anytime you want to talk SSL! And to try Masterful, just run pip install masterful to install our product and try it out.