
📝 Guest post: How to Build an ML Platform from Scratch*
No subscription is needed
In TheSequence Guest Post, our partners explain what ML and AI challenges they help deal with. In this article, Alon Gubkin, CTO of Aporia, discusses a proper ML infrastructure and offers a guide on how to build one using open-source tools.
How to Build an ML Platform from Scratch
As your data science team grows and you start deploying models to production, the need for proper ML infrastructure – and a standard way to design, train and deploy models – becomes crucial.
In this guide, we will build a basic ML Platform using open-source tools like Cookiecutter, DVC, MLFlow, FastAPI, Pulumi and more. We’ll also see how to monitor for model drift using Aporia. Final code is available on GitHub.
Keep in mind that this type of project can be huge – often taking a lot of time and resources – therefore, our toy ML Platform won’t have tons of features – just the basics, but it should teach you the basic principles of how to build your own ML platform.
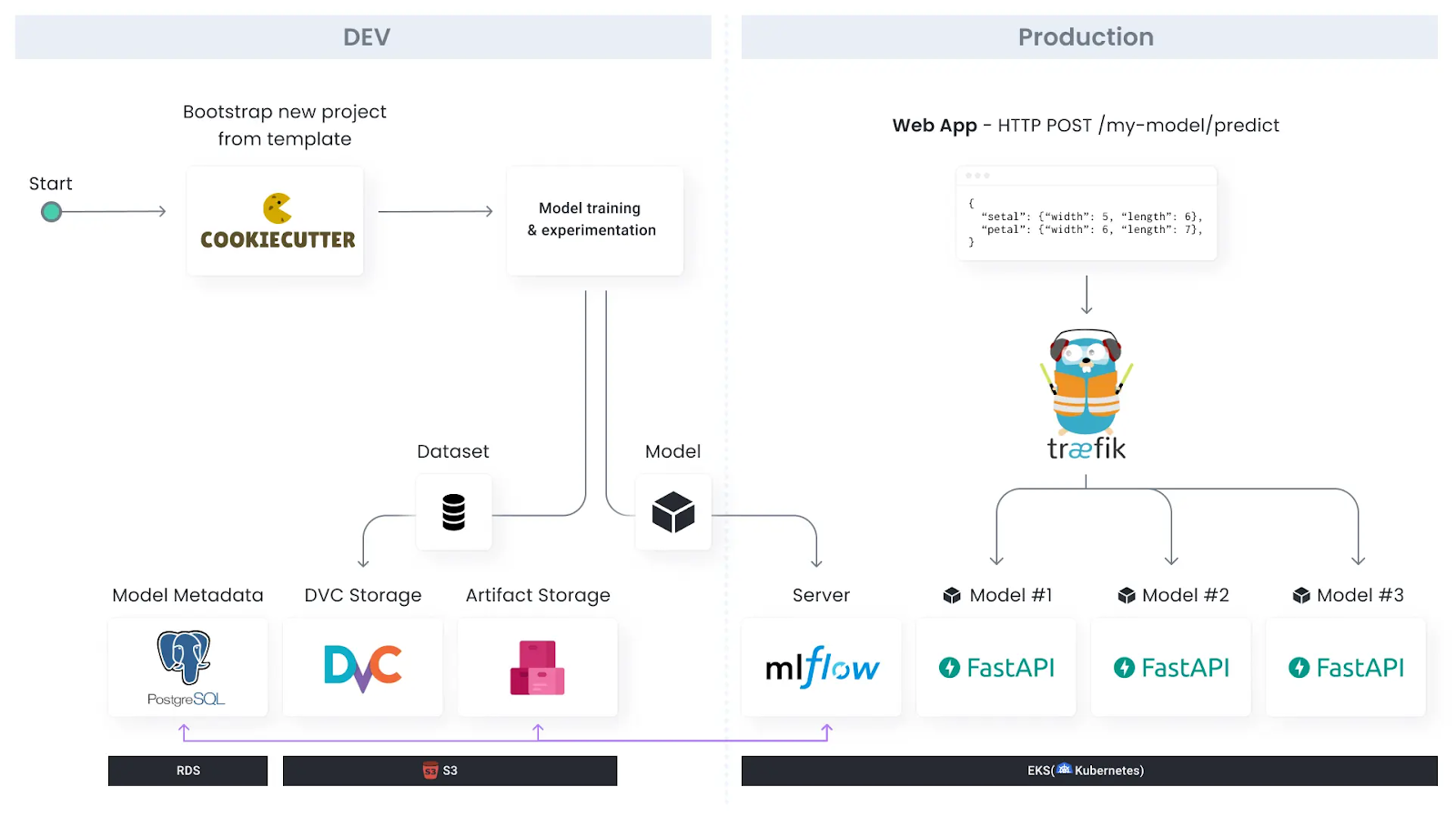
Our toy ML Platform will use DVC for data versioning, MLFlow for experiments management, FastAPI for model serving, and Aporia for model monitoring.
We’re going to build all of this on top of AWS, but in theory, you could also use Azure, Google Cloud, or any other cloud provider.
It’s important to note that when building your own machine learning platform, you should NOT take these tools for granted. You should evaluate alternatives – as they may be more appropriate for your specific use case and business needs.
Model Template
The first component in our machine learning platform is the model template, which we’ll build using Cookiecutter for templating, and Poetry for package management.
The idea is that when a data scientist starts working on a new project, they will clone our model template (which contains a standard folder structure, Python linting, etc.), develop their model, and easily deploy it when it’s ready for production.
The ML models template will contain basic training and serving code.
Data & Experiment Tracking
The training code in the model template will use the MLFlow client to track experiments.
Those experiments will be sent to the MLFlow Server that we’ll run on top of Kubernetes (EKS).
The model artifact itself will be saved in an S3 Bucket (the Artifact Storage), and metadata about experiments will be saved in a PostgreSQL database.
We’ll also track versions of the dataset using DVC in an S3 bucket.
Model Serving
For model serving, we’ll build a FastAPI server responsible for preprocessing, making predictions, etc.
These model servers are going to run on Kubernetes, and we’ll expose them to the internet using Traefik.
Infrastructure as Code
All our infrastructure is going to be deployed using Pulumi, an Infrastructure-as-Code tool similar to Terraform.
If you aren’t familiar with the concept, you can read more about it before continuing. Here are some major advantages of using this method:
Versioned: Your infrastructure is versioned, so if you have a bug, you can easily revert it to a previous version.
Code Reviewed: Each change to the infrastructure can be code reviewed, and you’re less prone to mistakes.
Sharable: You can easily share infrastructure components, just send the source code for the component.
With Pulumi, you can choose to write your infrastructure in a real programming language, such as TypeScript, Python, C#, and more.
Even though the natural choice for an ML platform would be Python, I chose TypeScript because, at the time of writing this post, Pulumi’s implementation of TypeScript is more feature complete.
Repositories & CI/CD
We’re going to have 2 GitHub repositories:
mlplatform-infra – the Pulumi code for the shared infrastructure of the ML Platform. Infrastructure that isn’t model-specific. Kubernetes, MLFlow, S3 buckets, etc.
model-template – the model template code that data scientists can clone, including basic training code, FastAPI server, etc.
For CI/CD, we’re going to use GitHub Actions.
Model Monitoring
We’ll now set up a data drift monitor using Aporia. You can play with Aporia using the free community edition with Aporia cloud or install it on Kubernetes using Pulumi.
Start by creating a free account. Once in the platform, click the “Add Model” button on the Models Management dashboard.
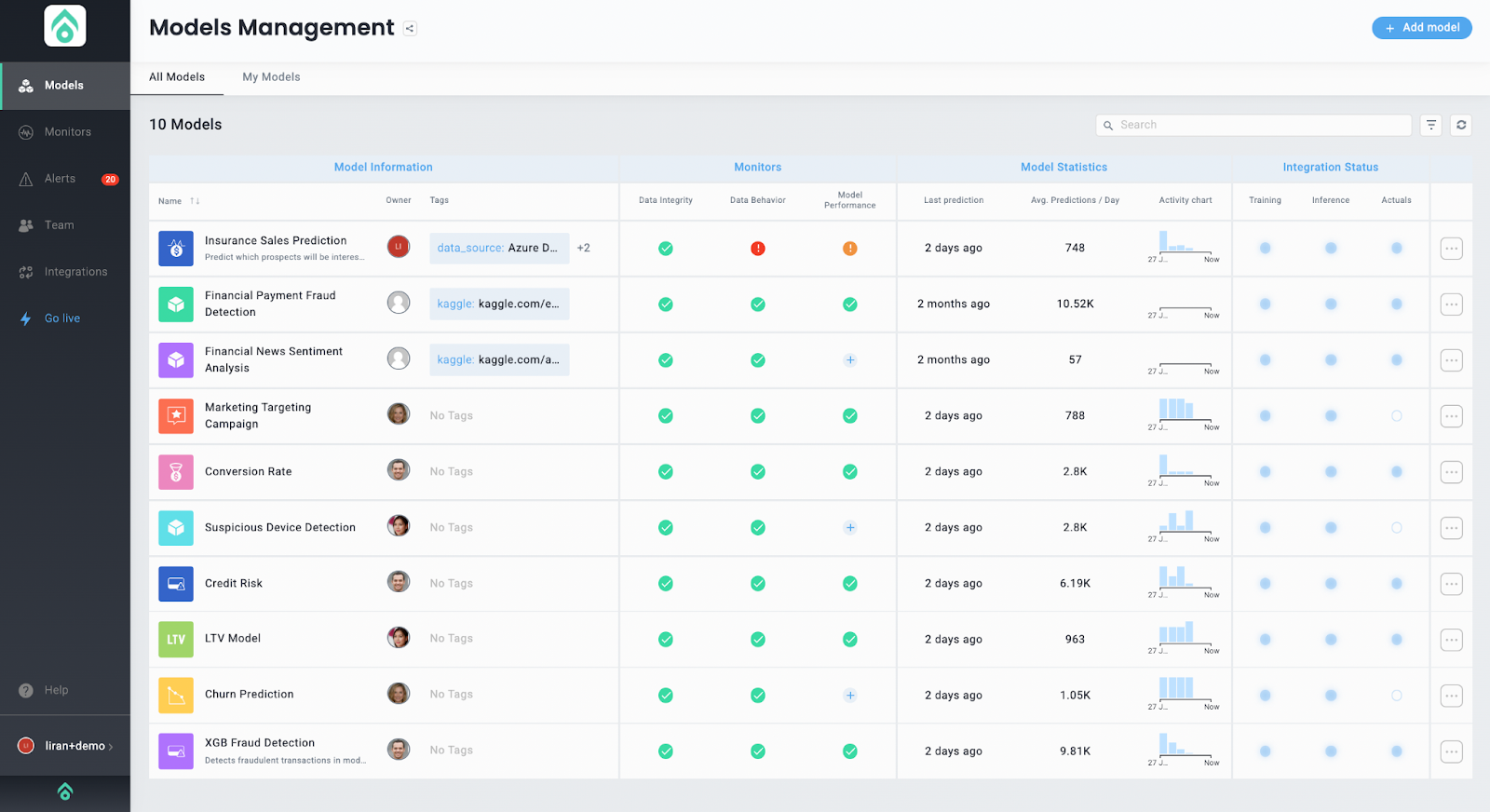
Follow the instructions to integrate your model. Then, you’ll be able to define monitors for Model Drift, Performance Degradation, and more.

Get started!
If you prefer to follow a 2-hour live coding session, check out this YouTube video I made for the MLOps.community. Or you can read the complete how-to guide here.
Have fun!