


📝 Guest post: Auto Labeling to Power Insurance Automation: Quickly Label Quality Datasets*
In this guest post, Superb AI shares a use case with their client Autonet that focuses on streamlining the claims experience in the auto insurance industry, using computer vision, AI, and domain knowledge to sort claims and route them to the best repair provider in a timely fashion. An important element of their data pipeline is understanding the orientation of the cars in pictures provided by the car owners. Knowing from what direction the car is being viewed enhances the value of damage tagging on each image. Let’s dive in!
Introduction
In auto insurance, there is a range of ways damage is assessed to determine what actions to take. Minor damages can be repaired by “SMART” (Small Medium Area Repair Technology) specialists. SMART repairs can be done directly on the vehicle (such as paintless dent repair). Alternatively, if the damages are severe and the car can be declared a “total loss”, settling such claims through automation can get the customers paid faster so they can get into a new car much sooner. The majority of claims are normal repairs that are handled by full-service body shops.
The auto insurance claim process can be complex and often may lead to poor customer experience. One problem is a “one-size-fits-all” approach where customers often have no other option but to rely on full-service body shops to receive estimates for car repairs, even for quick-fix jobs. In fact, many minor accidents or parking lot incidents can be handled through the SMART process, while many total loss cases can be reliably identified just from photos. At Autonet, we want to handle these cases more efficiently and faster than the standard auto-claims process, improving customer experience as well as cutting costs for everyone. Our workflow is detailed in the diagram below.
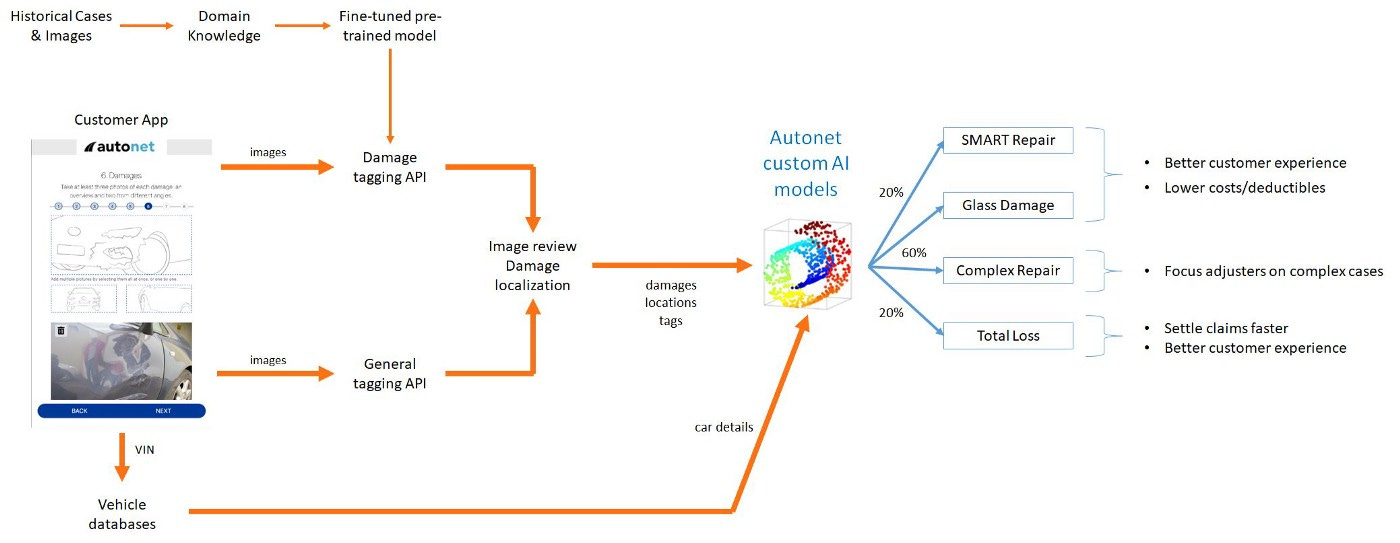
A vital step in this process is to try and localize the damage on the car, potentially identifying the damaged areas as well as adding valuable information for the decision and cost models to use. To help with this step of the process, it is valuable to understand the orientation of the car by using the various pictures collected earlier on in the process.
Problem statement
If you look at an image that contains a vehicle, whether static, video, or in the real world, you can immediately process the direction the vehicle is facing, approximate the angle, determine if it is displayed through video or is real-world, the distance to the vehicle and its speed. On the other hand, these tasks which are considered simple, are more challenging for a computer vision/machine learning automated system. To train a computer vision model, significant quantities of properly labeled images are needed, presenting another challenge. In this article, we show how to use an open-source data set of car images, a limited amount of manual labeling, and the Superb AI platform to build a large, labeled dataset and a classifier that can group images into one of eight compass directions with over 90 percent accuracy, and compare the platform auto-labeling performance to a custom Tensorflow/Keras model.
The Superb AI labeling platform is designed with image and label management features allowing human-in-the-loop labeling of images. The platform also supports training custom auto labeling models (CALs), which can then be used to bootstrap labeling to higher volume while still allowing control over review and use of the resulting labels. Under the hood. Superb AI has sophisticated AI tooling that learns from limited data.
The data
For this demonstration, we used the Stanford AI Lab cars dataset (see here). A few examples are shown below:

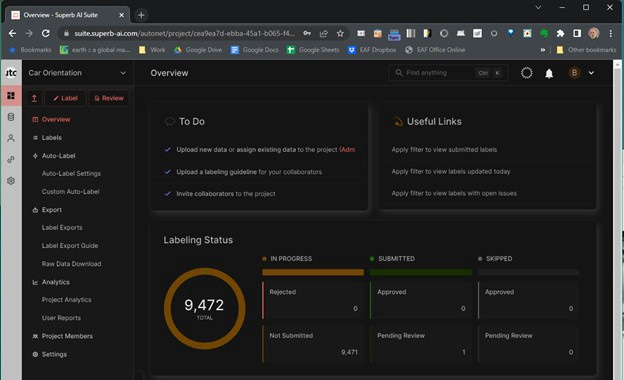
These images include advertising, public pictures, stationary vehicles, and moving cars, vans, and light trucks. There are about 8000 images in total. Of these, we initially labeled about 3000 images, then used Superb AI’s Custom Auto Label to label a bit less than another 800 images. The following image shows the project overview on Superb AI.
To generate the initial labeled data, we hand-labeled about 1200 images, then performed image augmentation in Python on most of the images using cropping (selected images) and flipping (horizontally). The distribution of these labeled images, which were then uploaded to the Superb AI platform, was highly skewed:

In Keras, we addressed this using class weighting:
total_reweight = train_sectors.shape[0] /
len(np.unique(train_sectors))
class_weights = dict()
for my_class in np.unique(train_sectors):
class_weights[my_class] = \
(1 / len(train_sectors[train_sectors == my_class])) *
total_reweightWe trained a CNN model with three convolutional layers, Max Pooling, and dropout, followed by three Dense layers also with Dropout. In Keras, you use the Flatten() layer to reshape the output of the last convolutional layer to be appropriate for a Dense layer input. The resulting model is shown here:
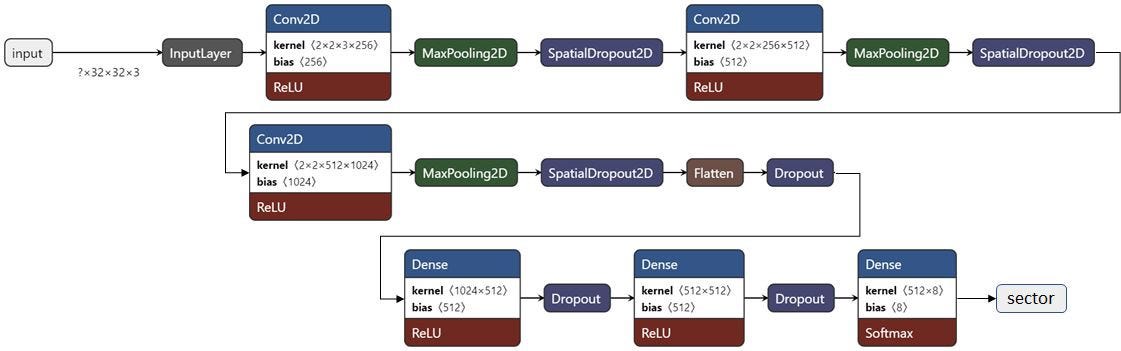
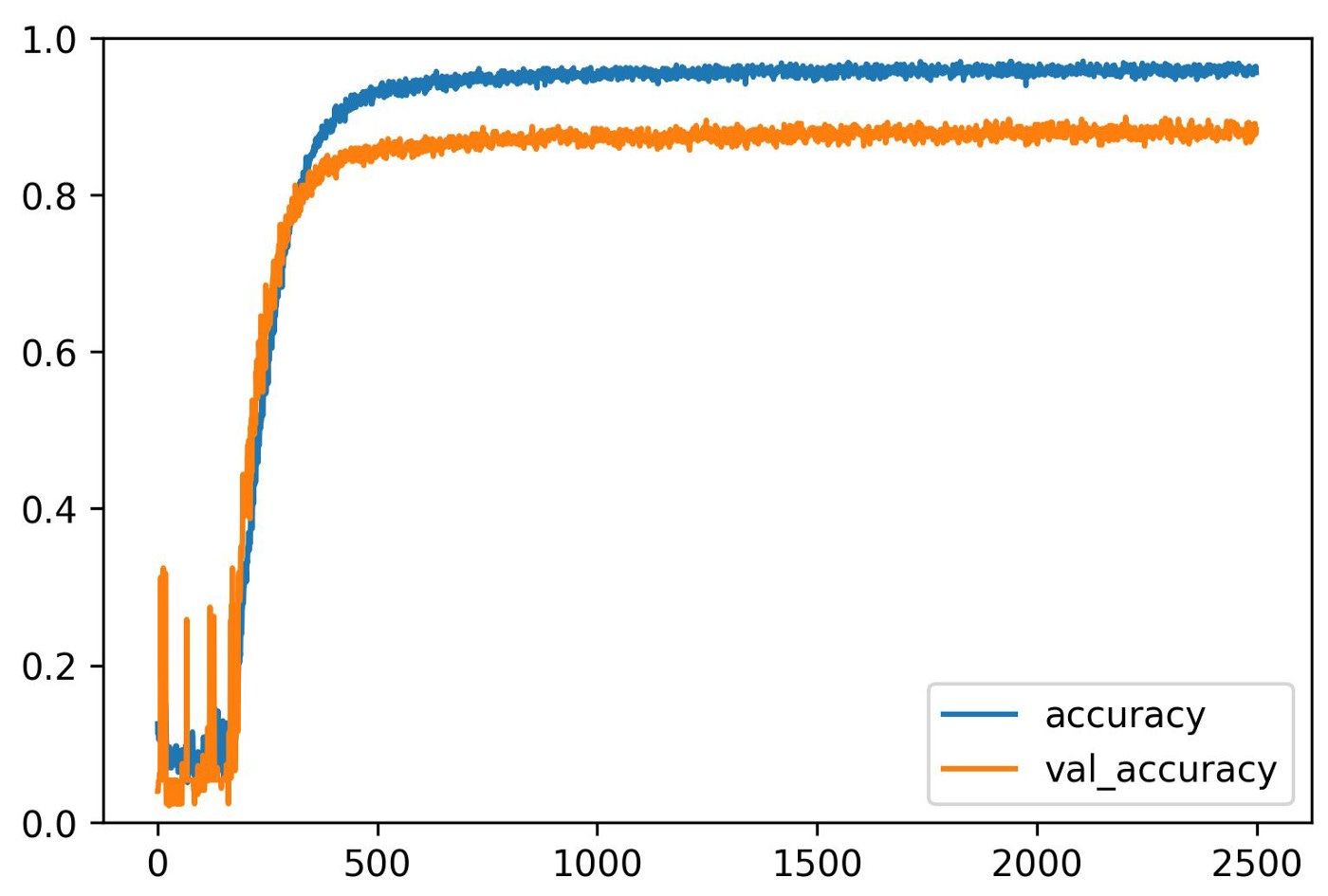
This model was trained for 2500 epochs with an initial learning rate of 5e-4 and no learning rate schedule. All the dropout fractions were set to 0.5. L2 regularization was used on the convolutional layers with a value of 5e-4, and L2 regularization was used on the dense layers with a value of 3e-4. Label smoothing was applied in the model.compile() step with an alpha of 0.2. The accuracy curves for the train and validation set are shown here.
Performance
After optimization using a validation set, the test set results obtained were as follows:
Superb CAL results: Keras model results:
sectorfront 0.93 0.77
left 0.90 0.74
left_front 0.96 0.84
left_rear 0.84 0.75
rear 0.81 0.65
right 0.83 0.84
right_front 0.92 0.84
right_rear 0.81 0.65
overall = 0.92 overall = 0.81It’s interesting to see where the Keras model has significantly poorer performance (on front, rear, and left rear, right rear), what “mistakes” it is making. An alternative to the confusion matrix, is a category mosaic plot, which shows not only the errors but shows the class distribution as well. Here is the category mosaic plot for the test set from the Keras model:
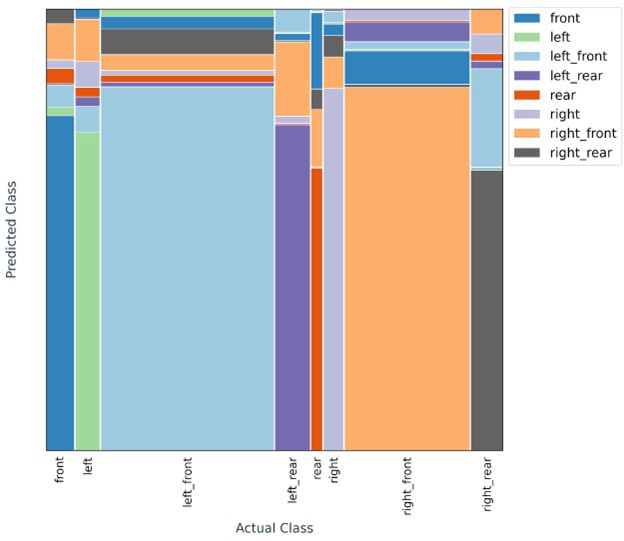
While both models could be used to label new, unlabeled images, which would then be reviewed by humans for accuracy, it’s evident that the model generated by the Superb AI platform is better, and we would prefer to use that. The objective of such a process is to generate more labeled data to further improve the models as efficiently as possible. In fact, we could have started this process sooner; Superb AI suggests that 1000 labeled images is a good starting point to generate a model, then auto label another batch (say, 1000) of those images, verify them, then repeat that process.
As an example, we auto labeled another 500 images, reviewed them, and used the combined data to train a new Custom Auto Label model. The review process in the Superb AI suite allows you to assign labels to be created or checked and enables access to both labelers and reviewers. You can also track labeling time used, review and approval status, and other metrics. Here is an example of a labeler display viewing one of the auto-labeled images:
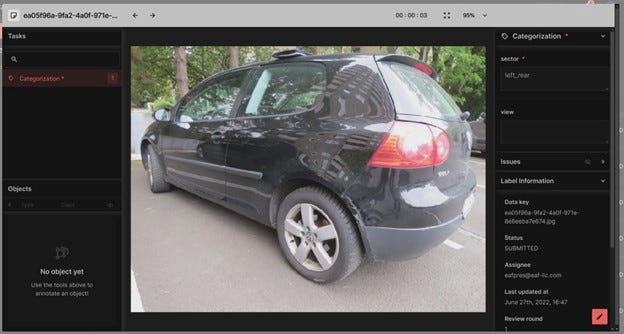
The assigned label is shown in the upper right, and if needed, the labeler could edit, change the label, and re-submit. In our test, only a few of the 500 auto-labeled images required a change.
The overall process is shown here:
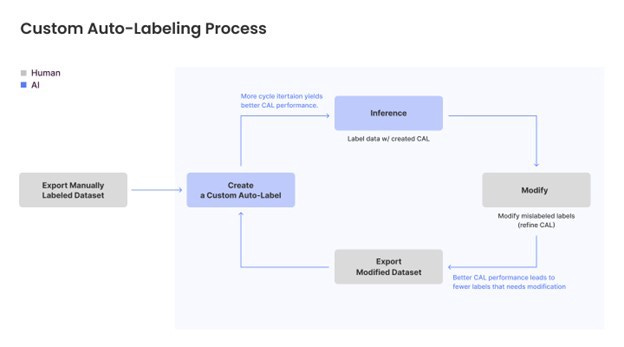
The results of re-training the models on more data are as shown here:
Superb CAL results: Keras model results:
sectorfront 0.97 0.73
left 0.85 0.70
left_front 0.97 0.93
left_rear 0.88 0.73
rear 0.87 0.70
right 0.88 0.74
right_front 0.95 0.90
right_rear 0.89 0.72
overall = 0.94 overall = 0.85Going from the re-training results above, we see that we have gained 2 percentage points in the overall accuracy of the auto-label model by auto-labeling to add more data. This translated into 5 percentage points gain on our test set, which was the same as used previously. The entire process took about two hours, a good return on time investment for most AI projects.
These results highlighted another useful feature of using the human-in-the-loop auto labeling on Superb AI. We found 40 mislabeled images out of 1000 in the test set, by comparing the CAL predictions to the original labels. Thus, the auto label process can help improve the dataset quality as well. Using the labels in other models is facilitated as the Superb AI platform allows exporting the labels in a JSON format that is similar to many popular computer vision labeling formats.
Summary
Supervised machine learning requires lots of labeled data. In the case of images, if labeling is done manually, it requires a person to look at every image and annotate it with the appropriate labels. It has been recognized by AI practitioners that some form of human-in-the-loop labeling leveraging model-based-labeling can be more efficient and more accurate than a purely manual process. In addition, with large numbers of images, it may make sense to distribute the workload across multiple labelers. In this article, we have demonstrated how to use platforms like Superb AI to augment manual labeling and make significant improvements to the model for production.