
🔵🔴 Edge#68: Run:AI Decouples Machine Learning Pipelines from the Underlying Hardware
Deep dive into one of the most relevant technology frameworks that are worth your attention
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. Become smarter about ML and AI.
Check the Quiz below: after ten quizzes, we choose the winner who gets the Premium subscription.
💥 What’s New in AI: Run:AI Decouples Machine Learning Pipelines from the Underlying Hardware
Infrastructure virtualization has played a very important role in the last two decades of software development. Companies such as VMWare made server virtualization mainstream, kickstarting a fascinating race between technology giants. Similarly, trends such as network virtualization got a lot of attention with companies like Nicira (acquired by VMWare) abstracting networking operations from their underlying infrastructure. More recently, containers in the form of technologies such as Docker and Kubernetes brought application virtualization closer to developers. All these technologies signaled a clear trend of decoupling software applications from the underlying hardware. The recent advent of machine learning (ML) workloads and the innovations in ML-hardware have brought us back to the era of tightly-coupled dependencies between ML models and hardware infrastructures – in this case GPUs. These dependencies make it extremely hard for data science teams to achieve top performance in ML models without optimizing the specific hardware infrastructures. Among the new startups tackling this new challenge, Run:AI stands out with a platform that seems ready for primetime.
The Many Challenges of Hardware Virtualization in ML Workloads
The dependencies between ML workloads and ML-hardware are very real. In my opinion, this problem has three main dimensions:
The increasing specialization of ML hardware.
The assignment and distribution of hardware resources in ML workloads.
The differences between development and training of ML workloads.
The first point is relatively simple to explain. How many times have you written an inference model in TensorFlow and PyTorch, just to spend countless hours optimizing for the underlying GPU hardware to make the model execute like your original code? This problem has become so systematic that the industry uses the term CUDA-Ninjas to refer to this type of ML engineers who can optimize models for specific hardware topologies. The rapid specialization of ML-hardware doesn’t help in this matter. These days, we have all sorts of flavors of ML-chips ranging from general-purpose GPUs to chips specialized in graph computation models or wide convolutional operations. While those hardware topologies can achieve record-level performance for different types of deep neural networks, they require models highly optimized for their specific architectures. To make matters more complicated, we even have AI-hardware accelerators that induce explicit dependencies between ML models and specific hardware. This problem gets even worse when we extrapolate it to a large organization of data science teams.
The second challenge is a bit more subtle but, arguably, more prominent given the current state of ML solutions. Data science experiments can go from consuming vast amounts of compute time and resources to sitting idle for hours or weeks. However, in a large organization, it is very common for data science teams to get assigned a fixed pool of GPU resources. That rigid methodology causes data science experiments to regularly run out of compute time or memory. At the same time, data science teams are fighting for the same pools of resources; or many resources are sitting idle without being properly allocated. In either case, this challenge in resource allocation represents a major bottleneck for large-scale ML workloads.
Finally, an important aspect of allocating hardware to ML workloads is the difference between the development and training cycles. During the development phase, data scientists don’t require large GPU clusters or high-throughput topologies. This changes during training in which data scientists can spend days training a specific model using highly-parallelizable and high-throughput workloads. In simpler terms, resource allocation and virtualization look very different between the different stages of the lifecycle of an ML model.
To address these challenges, ML workloads need an underlying infrastructure that can abstract the dependencies with hardware topologies and enable elastic resource allocations. Just like VMWare or Nicira respectively virtualized hardware and network infrastructure, large-scale ML solutions desperately need a virtualization layer.
Enter Run:AI
Run:AI is one of the most promising platforms in the nascent ML virtualization space. Conceptually, the Run:AI platform removes dependencies between ML pipelines and the underlying hardware infrastructure. Specifically, the Run:AI pool computes resources in a way that can be dynamically assigned to ML workloads, based on their requirements creating the sense of unlimited compute. This mechanism allows the reusability of GPU resources for data science pipelines while minimizing underutilized compute infrastructure. Run:AI’s virtualization mechanism allows data scientists to run a large number of experiments over an elastic computing infrastructure, without the need for static resource allocation.
To enable its virtualization capabilities, Run:AI leverages the orchestration capabilities of the Kubernetes platform. Kubernetes is already carving out its own space within the ML ecosystem in the form of MLOps platforms such as KubeFlow. Run:AI leverages Kubernetes in clever ways to assign resources to ML containers. From an architecture standpoint, the Run:AI platform runs as part of a Kubernetes cluster. In that context, the virtualization platform gets installed as a Kubernetes operator, which is an extensibility point that enables the customized management of resources in Kubernetes cluster. That architecture allows data scientists to interact with Run:AI by simply using a command-line interface or submitting YAML files to the underlying Kubernetes cluster. The infrastructure resources can be managed visually via the Run:AI admin user interface or programmable via the command-line interface.

Image credit: Run:AI
While Run:AI does take full advantage of Kubernetes resource orchestration capabilities, it adapts them to the specifics of ML workloads. For instance, Run:AI organizes GPU pools into two logical environments for build and train pipelines. The build environment minimizes the costs by utilizing low-end servers to provision traditional data science experimentation tools such as notebooks or IDEs. In contrast with that, the train environment optimizes for high throughput and parallelism leveraging high-end servers and integrating stacks such as Horovod that massively scale the training of ML models.
Arguably, the best example of how Run:AI adapts Kubernetes to ML workloads lies in its scheduler component. In many ways, the scheduler can be considered the cornerstone of the Run:AI platform and enables capabilities such as multi-node training, policy management and advanced resource queueing, which are essential in the lifecycle of ML models. The scheduler uses high-performance computing techniques, such as batch scheduling and Gang scheduling, to optimize the GPU utilization in a Kubernetes cluster. One of the most innovative capabilities of the Run:AI scheduler is its “topology awareness,” which allocates optimal GPU topologies to specific ML models. As data scientists deploy models from environment to environment, the Run:AI scheduler tries to configure the best GPU topology based on historical performance, guaranteeing close-to-optimal performance of the models.
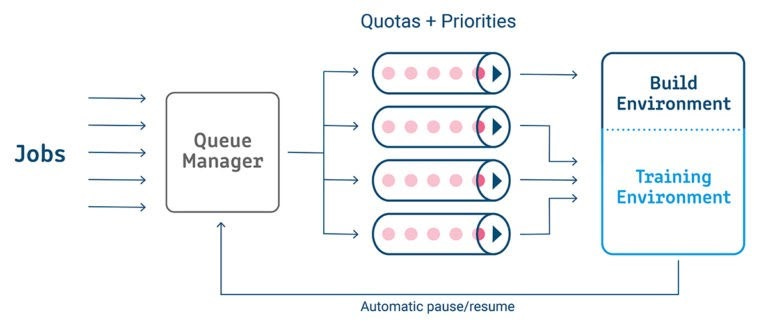
Image credit: Run:AI
The Run:AI platform can run on a simple Kubernetes cluster or as part of sophisticated platforms such as AWS Elastic Container Service, OpenShift and many others. The native support for Kubernetes allows Run:AI to be deployed as on-premise or cloud topologies, which makes it adaptable to heterogenous ML enterprise environments. The current version of Run:AI natively supports different GPU architectures and is rapidly incorporating new ones. Finally, Run:AI provides native support for different MLOps stacks such as Apache AirFlow and enables programmable interfaces via Kubernetes or REST APIs.
Conclusion
ML virtualization is a very nascent space, but one that seems essential to the next decade of ML innovation. Just like VMWare, Nicira and Docker enabled virtualization in areas such as servers, networks and applications respectively, Run:AI is adapting many of those principles of the new world of ML workloads. The next few years of ML are likely to bring an unprecedented level of innovation in hardware and GPU architectures, which can also translate into a lot of complexities for enterprises managing large pools of compute resources dedicated to ML systems. Run:AI offers a scalable, flexible and extensible platform that can abstract the complexities of hardware topologies from ML workloads. Unlike many other trends before, the near-term evolution of ML is tied to hardware and Run:AI can play a pivotal role in bringing those two worlds together.
🧠 The Quiz
Every ten quizzes we reward two random people. Participate! The question is the following:
What is the role of the scheduler in the Run:AI platform?
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms, followed by 75,000+ specialists from top AI labs and companies of the world.
