
🤼 Edge#32: Adversarial Attacks
TheSequence is a convenient way to build and reinforce your knowledge about machine learning and AI
In this issue:
we overview the concept of adversarial attacks;
we explore OpenAI’s research paper about the robustness of a model against adversarial attacks;
we get into IBM’s adversarial robustness toolbox that helps protect neural networks against adversarial attacks.
Enjoy the learning!
💡 ML Concept of the Day: What are adversarial attacks in deep neural networks?
In TheSequence Edge#8, we covered the topic of generative adversarial neural networks (GANs), which have emerged as one of the most popular techniques in the universe of generative models. Conceptually, GANs are a form of unsupervised learning in which two neural networks build knowledge by competing against each other in a zero-sum game. One of the most practical applications of GANs is a mechanism to generate attacks against other deep neural networks. This is known in deep learning theory as adversarial attacks.
The idea of adversarial attacks is fundamentally simple. A GAN model can be trained to generate small changes in a dataset that, although imperceptible to the human eye, can cause major changes in the output of a deep neural network. Imagine that we have a convolutional neural network (CNN) that performs an image classification technique. An adversarial attack can introduce some small noise in the input dataset and completely alter the results of the classifier. While this might sound like a fun research exercise, imagine the damage it can cause in scenarios such as self-driving vehicles.

Image credit: Joao Gomes
There are many types of adversarial attacks but they can be fundamentally classified into three main groups:
White-Box Attacks: This type of attack assumes that the adversarial network has full knowledge of the target model architecture and parameters.
Gray-Box Attacks: This type of attack assumes that the adversarial network has some basic knowledge about the structure of the target model.
Black-Box Attacks: This type of attack assumes that the adversarial network can only generate adversarial examples and evaluate the results.
Testing neural networks against adversarial attacks is no longer a fancy requirement but a key task in the lifecycle of many mission-critical machine learning applications.
🔎 ML Research You Should Know: OpenAI’s metric for the robustness of a model against adversarial attacks
In the paper, Testing Robustness Against Unforeseen Adversaries, researchers from OpenAI introduced a new metric to evaluate the robustness of a model against never-before-seen adversarial attacks.
The objective: Provide a quantifiable way to evaluate the robustness of a model against unforeseen or adaptable adversarial attacks.
Why is it so important: OpenAI’s research is one of the first attempts to quantify the robustness of neural networks against attacks not seen during the training phase.
Diving deeper: Most neural networks are very vulnerable to adversarial attacks and, as a result, the research community has developed different defense methods and measures against those attacks. However, those metrics and defenses suffer from the limitation that they assume prior knowledge of attacks, which is hardly the case in real-world scenarios. Adversarial techniques are constantly evolving and bad actors regularly develop new attack methods, which cause neural networks to face attacks that haven’t been evaluated during the training phase. As a result, evaluating the robustness of a neural network against unforeseen adversarial attacks has become an increasingly important security practice in deep learning solutions.
To address this challenge, OpenAI developed a technique that evaluates a neural network against diverse unforeseen attacks at a wide range of distortion sizes, comparing the results to strong defense methods that have knowledge of the distortion type. To make the results quantifiable, OpenAI developed a new metric known as Unforeseen Attack Robustness (UAR) which can provide a measure of the robustness of a model against an unforeseen adversarial attack. The OpenAI technique can be divided into three main steps:
Evaluate a neural network against unforeseen distortion types: The OpenAI method proposes evaluating the robustness of a method using adversarial attacks that were not considered during training.
Choose a wide range of distortion sizes calibrated against strong models: Among a set of potential distortion sizes in an image dataset, OpenAI’s technique typically chooses the largest variation for which the images are still recognizable. The idea is that attacks with wider distortion sizes have proven to be very effective against basic adversarial defenses.
Benchmark adversarial robustness against adversarially trained models: OpenAI developed the UAR metric that evaluates the robustness of a neural network against an attack to adversarial training against that same attack. A high UAR score indicates that the model’s resiliency to an unforeseen attack is comparable to known attacks.
OpenAI’s UAR is one of the most effective methods to evaluate the robustness of neural networks against adversarial attacks. In addition to the research paper, OpenAI open-sourced the implementation of the UAR metric, making it possible to incorporate it into deep learning models developed in different frameworks.
🤖 ML Technology to Follow: IBM Adversarial Robustness Toolbox to Protect Neural Networks Against Adversarial Attacks
Why should I know about this: The Adversarial Robustness Toolbox (ART) is one of the most complete libraries for evaluating the resiliency of deep learning models against adversarial attacks.
What is it: IBM’s Adversarial Robustness Toolbox (ART) is an open-source Python library that allows data scientists to evaluate the resiliency of specific machine learning models against adversarial attacks. ART operates by examining and clustering the neural activations produced by a training dataset, trying to discriminate legit examples from those likely manipulated by an adversarial attack. The current version of ART focuses on two types of adversarial attacks: evasion and poisoning. For each type of adversarial attack, ART includes defense methods that can be incorporated into deep learning models.
The current version of ART enables attack simulations and defenses based on four fundamental adversarial techniques. For each type of adversarial attack, ART includes defense methods that can be incorporated into deep learning models.
Evasion: Attacks that modify the input to influence the model. For instance, adding modifications to medical images in order to influence classification.
Poisoning: Attacks that modify training data to add a backdoor. For example, Imperceptible patterns in training data create backdoors that control models.
Extraction: Attacks that steal a proprietary model. For instance, attacks can query a model regularly to extract valuable information.
Inference: Attacks that earn information on private data. For instance, an attack can derive properties of the model’s training data up to identifying single data entries.
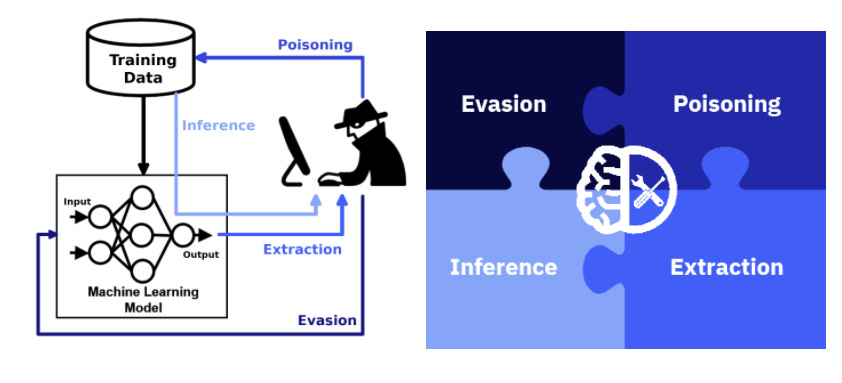
ART includes implementations of many of the most popular adversarial attacks as well as its corresponding defense techniques. The framework supports interoperability with many deep learning stacks such as TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy and many others. Additionally, ART supports a large variety of datasets such as video, audio, language and structured data.
How can I use it: ART is open source and available at https://github.com/Trusted-AI/adversarial-robustness-toolbox
🧠 The Quiz
Now, to our regular quiz. After ten quizzes, we will reward the winners. The questions are the following:
What’s the main difference between white-box and black-box adversarial attacks in neural networks?
What’s the type of adversarial attack that focuses on modifying the model’s inputs?
That was fun! Thank you. See you on Sunday 😉
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. TheSequence keeps you up to date with the news, trends, and technology developments in the AI field.
5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space. Please contact us if you are interested in a corporate subscription.

The easiest way to generate adversarial examples remains gradient-based attacks, by reading the first part we could think that GANs are almost the only way to go.