
🔳 Edge#16: Probabilistic Programming, ideas behind MIT’s Gen, and the three most popular PPLs~
In this issue:
we discuss the concept of probabilistic programming languages;
we explore the ideas behind MIT’s Gen, a new generation probabilistic programming language;
we provide an overview of some of the most popular probabilistic programming languages on the market.
Enjoy the learning!
💡 ML Concept of the Day: What is Probabilistic Programming?
Inference algorithms and statistical modeling are some of the most common components in machine learning solutions. Most programming languages provide libraries for highly sophisticated statistics, but they are typically constrained to express specific formulas or statistical models and can rarely express any sophisticated business logic constructs in it. What if we could express complete programs using statistical constructs? Welcome to the field of probabilistic programming.
Conceptually, probabilistic programming sits at the intersection of machine learning, statistics, and programming languages. The main idea behind probabilistic programming is to combine statistical inference with the syntactic and semantic rules of programming languages in order to express complete programs with statistics as a first-class building block. Traditional software programming is about writing programs that receive a series of parameters as input and produce an output. Statistics focus more on determining an appropriate distribution of a set of observations. Probabilistic programming focuses on domain-specific programming languages for model definitions and statistical inference algorithms for computing the conditional distribution of the program inputs that could have given rise to the observed program output.

Image credit: Original paper
No surprise that probabilistic programming has become very popular in programming languages with strong data science frameworks as well as flexible syntactic and semantic structures such as Python or Scala. However, you can find flavors of probabilistic programming in most of the popular programming languages such as C++, Java, and C#.
The field of probabilistic programming has been around for decades but was mostly ignored in mainstream software applications. With the rise in popularity of machine learning, probabilistic programming has become an incredibly important tool in data science teams’ arsenal. We will see more innovative releases in this space.
🔎 ML Research You Should Know: Gen, the Future of Probabilistic Programming
In the paper Gen: A General-Purpose Probabilistic Programming System with Programmable Inference, researchers from the Massachusetts Institute of Technology (MIT) presented a probabilistic programming language that can be used in several inference areas such as robotics, computer vision, and statistics.
The objective: The goals of Gen are to build a probabilistic programming language (PPL) with enough design flexibility that can be used in general-purpose inference tasks.
Why is it so important: Most probabilistic programming languages have been limited to domain-specific modeling tasks and lack the flexibility to be applied in real-world inference tasks. The Gen design looks to overcome some of those challenges with a new probabilistic programming model.
Diving deeper: Probabilistic programming languages are becoming increasingly popular within the machine learning community, but their usage remains limited. Many probabilistic programming languages provide very constrained modeling capabilities that are only applicable to specific domains. Others provide richer modeling languages but limited support for inference models. In general, the challenges in traditional probabilistic programming languages can be summarized in two main categories:
Inference Algorithm Efficiency: A general-purpose PPL should allow developers to create customized and highly sophisticated models without sacrificing the performance of the underlying components. The more expressive PPL syntax is, the more challenging the optimization process will be.
Implementation Efficiency: A general-purpose PPL requires a system to run inference algorithms that go beyond the algorithm itself. Implementation efficiency is determined by factors such as data structures used to store algorithm state, and whether the system exploits caching and incremental computation.
Gen addresses some of the challenges mentioned in the previous section by leveraging a novel architecture that improves upon some of the traditional PPL techniques. Based on Julia programming language, Gen introduces an architecture that represents models not as program code in a Turing-complete modeling language, but as black boxes that expose capabilities useful for inference via a common interface. These black boxes are called generative functions and include an interface with the following capabilities:
Tools for Constructing Models: Gen provides multiple interoperable modeling languages, each striking a different flexibility/efficiency trade-off. A single model can combine code from multiple modeling languages. The resulting generative functions leverage data structures well-suited to the model as well as incremental computation.
Tools for Tailoring Inference: Gen provides a high-level library for inference programming, which implements inference algorithm building blocks that interact with models only through generative functions.
Evaluation: Gen provides an empirical model to evaluate its performance against alternatives across well-known inference problems.
The following figure illustrates the Gen architecture. As you can see, the frameworks support different inference algorithms as well as a layer of abstraction based on the concept of generative functions.
The following diagram illustrates some of the differences between Gen’s architecture and traditional programming language models. In general, the flexibility of combining both modeling and inference capabilities in a single language makes Gen a flexible option for general-purpose machine learning scenarios.
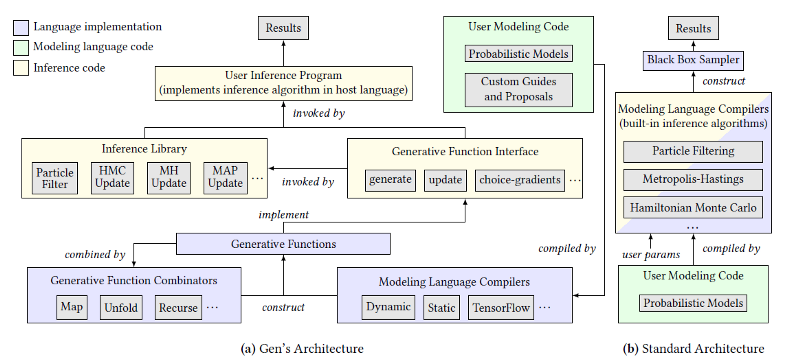
Image credit: Original paper
🤖 ML Technology to Follow: Three Probabilistic Programming Languages You Should Know About
Why should I know about this: Probabilistic programming languages are becoming an increasingly popular component of machine learning solutions. However, these new frameworks are not as popular and well-known as mainstream machine learning stacks. Below we outline some information about three probabilistic programming stacks that will help you learn more about this space.
What is it: The field of probabilistic programming languages has been exploding with research and innovation in recent years. Most of this innovation has come from combining PPLs and deep learning methods to build neural networks that can efficiently handle uncertainty. This is typically known as deep probabilistic programming languages. Tech giants such as Google, Microsoft, and Uber have been responsible for pushing the boundaries of deep probabilistic programming languages into large scale scenarios. Those efforts have translated into completely new deep probabilistic programming languages stacks that are becoming increasingly popular within the machine learning community. Here are three deep probabilistic programming languages frameworks that could be helpful in your next machine learning project:
Edward is a Turing-complete probabilistic programming language written in Python. Originally, the Google Brain team championed Edward but now has an extensive list of contributors. The original research paper of Edward was published in March 2017 and since then the stack has seen a lot of adoption within the machine learning community. Edward fuses three fields: Bayesian statistics and machine learning, deep learning, and probabilistic programming. The library integrates seamlessly with deep learning frameworks such as Keras and TensorFlow.
From a functional standpoint, Edward’s capabilities can be analyzed by three main areas:
Modeling: supporting the creation of graphical or implicit generative models.
Inference: libraries that enable variational inference, Monte Carlo methods, and compositional inference.
Criticism: routines to validate inference methods with point-based evaluations or posterior predictive checks.
Pyro is a deep PPL released by Uber AI Labs. Pyro is built on top of PyTorch and is based on four fundamental principles:
Universal: Pyro is a universal PPL — it can represent any computable probability distribution. How? By starting from a universal language with iteration and recursion (arbitrary Python code), and then adding random sampling, observation, and inference.
Scalable: Pyro scales to large data sets with little overhead above hand-written code. How? By building modern black box optimization techniques, which use mini-batches of data, to approximate inference.
Minimal: Pyro is agile and maintainable. How? Pyro is implemented with a small core of powerful, composable abstractions. Wherever possible, the heavy lifting is delegated to PyTorch and other libraries.
Flexible: Pyro aims for automation when you want it and control when you need it. How? Pyro uses high-level abstractions to express generative and inference models while allowing experts to easily customize inference.
No analysis of PPLs would be complete without covering TensorFlow Probability. While it can’t be classified as a new probabilistic programming language, TensorFlow Probability is certainly one of the most popular libraries for statistical inference and reasoning. The main benefit of TensorFlow Probability is the seamless integration between statistical inference and deep learning models in TensorFlow. Functionally, TensorFlow Probability is structured in three different layers:
Layer 1: This layer contains statistical building blocks such as distribution or bijection functions that are commonly used in statistical modeling.
Layer 2: This layer contains a series of components for statistical model building such as join distributions of neural network layers based on uncertainty.
Layer 3: This layer provides foundational elements for probabilistic inference such as Markov and Monte Carlo methods.
How can I use it: All three frameworks are free and open source. Edward is available at http://edwardlib.org/, Pyro is distributed at http://pyro.ai/ and TensorFlow Probability is maintained at https://github.com/tensorflow/probability/
🧠 The Quiz
Now, let’s check your knowledge. The questions are the following:
What is the main idea behind probabilistic programming?
What is the main contribution of MIT’s Gen to the field of probabilistic programming languages?
Please use an email you are signed up with, so we can track your success.
That was fun! Thank you. See you on Sunday 😉
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. TheSequence keeps you up to date with the news, trends, and technology developments in the AI field.
5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space. Make it a gift for those who can benefit from it.
