
✨ Edge#14: The magic of semi-supervised learning~
In this issue:
we discuss the concept of semi-supervised learning;
we deep dive into a paper that proposes a data augmentation method to advance semi-supervised learning;
we explore Labelbox, a fast-growing platform for data labeling.
Enjoy the learning!
💡 ML Concept of the Day: What is Semi-Supervised Learning?
Traditional machine learning theory divides the universe into supervised and unsupervised methods but the reality is a bit more complex. While supervised methods dominate the modern machine learning ecosystem, they have already hit a wall and can not be adopted in many scenarios, as they depend on highly accurate labeled datasets that are rarely available. On the other end, the promise of unsupervised machine learning methods seems a bit distant. So the challenge machine learning researchers face is how to create methods that leverage some of the benefits of supervision without requiring expensive training datasets. Among the methods created in recent years, semi-supervised learning has received a wide level of adoption in practical applications.
The goal of semi-supervised learning is to enable the training of ML models by using a small labeled dataset and a large volume of unlabeled data. Semi-supervised learning tries to mitigate the dependency on expensive labeled datasets by learning from unlabeled data. How is that possible?
Semi-supervised learning is analogous to a teacher who presents a few concepts to a group of students and leaves the other concepts to homework and self-study. At a high level, a semi-supervised learning method will use a combination of labeled and unlabeled datasets. The model will start by clustering similar data of the unlabeled dataset using an unsupervised learning algorithm. Then, it uses the existing labeled data to label the rest of the unlabeled data.
Not all machine learning problems can be tackled using semi-supervised learning. Conceptually, semi-supervised learning methods make some assumptions about the training datasets.
Continuity Assumption: The algorithm assumes that the points that are closer to each other are more likely to have the same output label.
Cluster Assumption: The data can be divided into discrete clusters and points in the same cluster are more likely to share an output label.
Manifold Assumption: The data lie approximately on a manifold of much lower dimension than the input space. This assumption allows the use of distances and densities which are defined on a manifold.
Semi-supervised learning is a relatively new entrant in the machine learning ecosystem but one that has seen a strong level of adoption. Companies like Google and Facebook have adopted semi-supervised learning in many critical machine learning applications and are championing active research in the space.
🔎 ML Research You Should Know: Unsupervised Data Augmentation
In “Unsupervised Data Augmentation (UDA) for Consistency Training” researchers from Google Brain and Carnegie Mellon University proposed a method that uses data augmentation to significantly improve the performance of semi-supervised learning models.
The objective: The UDA paper proposes a technique for addressing the challenges of training semi-supervised learning models with small labeled datasets.
Why is it so important: The UDA paper has considerably advanced the field of semi-supervised learning.
Diving deeper: The theoretical framework of semi-supervised learning indicates that those models should outperform supervised alternatives with small labeled datasets and perform similar to them as the training dataset’s size increases. In a nutshell, the UDA paper proposes a method that helps semi-supervised methods consistently outperform supervised alternatives, even as the size of the labeled training dataset increases.

The main idea behind the UDA paper is to leverage the emerging field of unsupervised data augmentation methods in order to improve the performance of consistent training methods, which are the cornerstone of semi-supervised learning. Conceptually, consistency training methods simply regularize model predictions to be invariant to small noise applied to either input example. The UDA paper proves that unsupervised data augmentation methods that perform well in supervised learning models should also perform well in a consistency-based training approach such as semi-supervised learning. Oh yes, I guess a good place to start could be to define data augmentation. 😊
Unsupervised data augmentation tries to leverage both labeled and unlabeled datasets to train a machine learning model. With labeled data, this technique computes a loss function just like in supervised learning methods. For unlabeled datasets, unsupervised data augmentation applies consistency training to make predictions based on unlabeled data look similar to those made on labeled datasets. After that, unsupervised data augmentation methods compute a loss function that uses both the supervised loss from the labeled data and the unsupervised consistency loss from the unlabeled data.
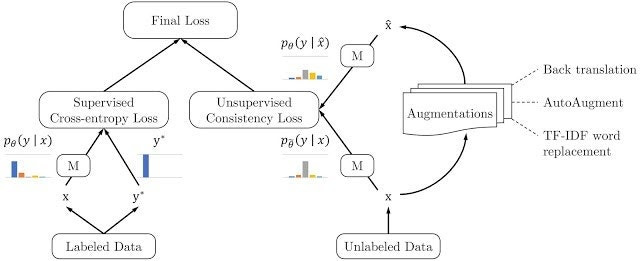
.
Image credit: Original paper
The magic of unsupervised data augmentation is that it allows label information to slowly propagate from labeled datasets to unlabeled ones. This is the essence of semi-supervised learning models. As shown in the UDA paper, using unsupervised data augmentation allows semi-supervised learning methods to start with a small labeled dataset and steadily make more accurate predictions based on unlabeled data. The initial benchmarks show that semi-supervised learning methods that use unsupervised data augmentation and are able to outperform supervised alternatives with small labeled datasets, will continue to outperform them as the size of the labeled dataset increases.
🤖 ML Technology to Follow: Labelbox is a Data Labeling Platform for your Machine Learning Models
Why should I know about this: Building labeled training datasets is one of the biggest challenges in machine learning solutions. Labelbox is one of the emerging platforms trying to address this challenge.
What is it: It is easy to trivialize the challenges of data labeling until you need to do it at scale. Building and maintaining large training datasets is a hard endeavor and typically requires labor-intensive processes and collaboration between different parties. Labelbox is an end-to-end platform for labeling and serving training datasets for machine learning models. The platform provides tools, programmable interfaces, and infrastructure for annotating datasets that can be used in machine learning models. Architecturally, Labelbox provides a consistent experience for labeling heterogeneous datasets such as text, images, audio, and video.

Image credit: Labelbox
Even though Labelbox enables a consistent experience for different data sources, it also provides tools specialized on a given data structure. For instance, to label an image dataset, Labelbox offers tools that allow a user to draw a box or polygon around a specific object. Similarly, for video datasets, Labelbox includes bounding tools that let users capture concepts in a sequence of frames.
One of the main benefits of Labelbox is that its functionality is orthogonal to a machine learning model. You can use Labelbox to serve training data for models built in your favorite machine learning framework. Once a dataset has been annotated in Labelbox, it can be incorporated into machine learning models using a handful of lines of code abstracted by the Labelbox SDK. Additionally, Labelbox enables programmatic access to the platform via a GraphQL API, which allows applications to navigate the entire structure of the projects and datasets.
One of the really useful capabilities of Labelbox is that it makes the data labeling process a collaborative, rather than isolated, exercise. The platform facilitates the interactions between different users in order to correctly label a given dataset. Labelbox can be used both in hybrid cloud and on-premise infrastructures, which facilitates its deployment in enterprise environments.
How can I use it: Labelbox can be accessed at https://labelbox.com/. The platform has a commercial edition and offers a free trial.
🧠 The Quiz
Now, let’s check your knowledge. The questions are the following:
When should you consider using semi-supervised learning?
Why do researchers claim that unsupervised data augmentation improves semi-supervised learning?
Please use an email you are signed up with, so we can track your success.
That was fun! Thank you. See you on Sunday 😉
TheSequence is a summary of groundbreaking ML research papers, engaging explanations of ML concepts, and exploration of new ML frameworks and platforms. TheSequence keeps you up to date with the news, trends, and technology developments in the AI field.
5 minutes of your time, 3 times a week – you will steadily become knowledgeable about everything happening in the AI space. Make it a gift for those who can benefit from it.
We have a special offer for group subscriptions.
