


🔷🟥 Edge#126: Pachyderm 2 Brings New Data Capabilities to Accelerate your ML Lifecycle
What’s New in AI, a deep dive into one of the freshest research papers or technology frameworks that is worth your attention. Our goal is to keep you up to date with new developments in AI in a way that complements the concepts we are debating in other editions of our newsletter.
💥 What’s New in AI: Pachyderm 2 Brings New Data Capabilities to Accelerate your ML Lifecycle
Innovation in the machine learning (ML) space is moving at a frantic pace. Just a few weeks ago, we wrote about Pachyderm, one of the most innovative platforms in the emerging MLOps space. That’s not a marketing statement, I think the idea of a Git-like version control infrastructure for data and models is super clever. After publishing our analysis, the Pachyderm team released a sizable update, which calls for an extended deep dive.
Pachyderm 2 builds on the foundation of its predecessor and provides an upgraded set of capabilities for its cloud, community, and enterprise editions. In a nutshell, Pachyderm 2 can be seen as two major releases:
1. The Enterprise Platform: Pachyderm Enterprise 2.
2. The Cloud Platform: Pachyderm Hub 2.
Before diving into the Pachyderm 2 updates, it might be worth doing a quick recap of its predecessor.
Pachyderm 1 Recap
Pachyderm 2 builds on the foundation established by the first version of the Pachyderm platform. Pachyderm 1 provides a sophisticated data foundation across the different stages of the lifecycle of ML applications. Specifically, Pachyderm handles data ingestion, cleaning, wrangling, processing, and modeling among other fundamental building blocks of data versioning and data science pipelines. From the functional standpoint, the Pachyderm 1 platform delivers the following features:
Version Control: Pachyderm takes automatic snapshots at every step in the data science pipeline without the programmer needing to remember to call snapshots.
Data Lineage: Pachyderm accurately tracks the provenance of what’s in the training snapshots, as well as the relationship between the data, the code, and the model.
Containerization: Pachyderm runs in container infrastructures like Docker and Kubernetes, removing dependencies from any data science framework.
Parallelization: Because it leverages Kubernetes, Pachyderm can automatically scale up and parallelize data processing with no changes to the code, slicing up data into small chunks that are processed in parallel.
Code Agnosticism: The platform lets you run models in whatever framework or programming languages you want, like Python, R, Java, Rust, C++, Bash, or others.
The platform can handle the entire lifecycle of ML pipelines from data collection to deployment.
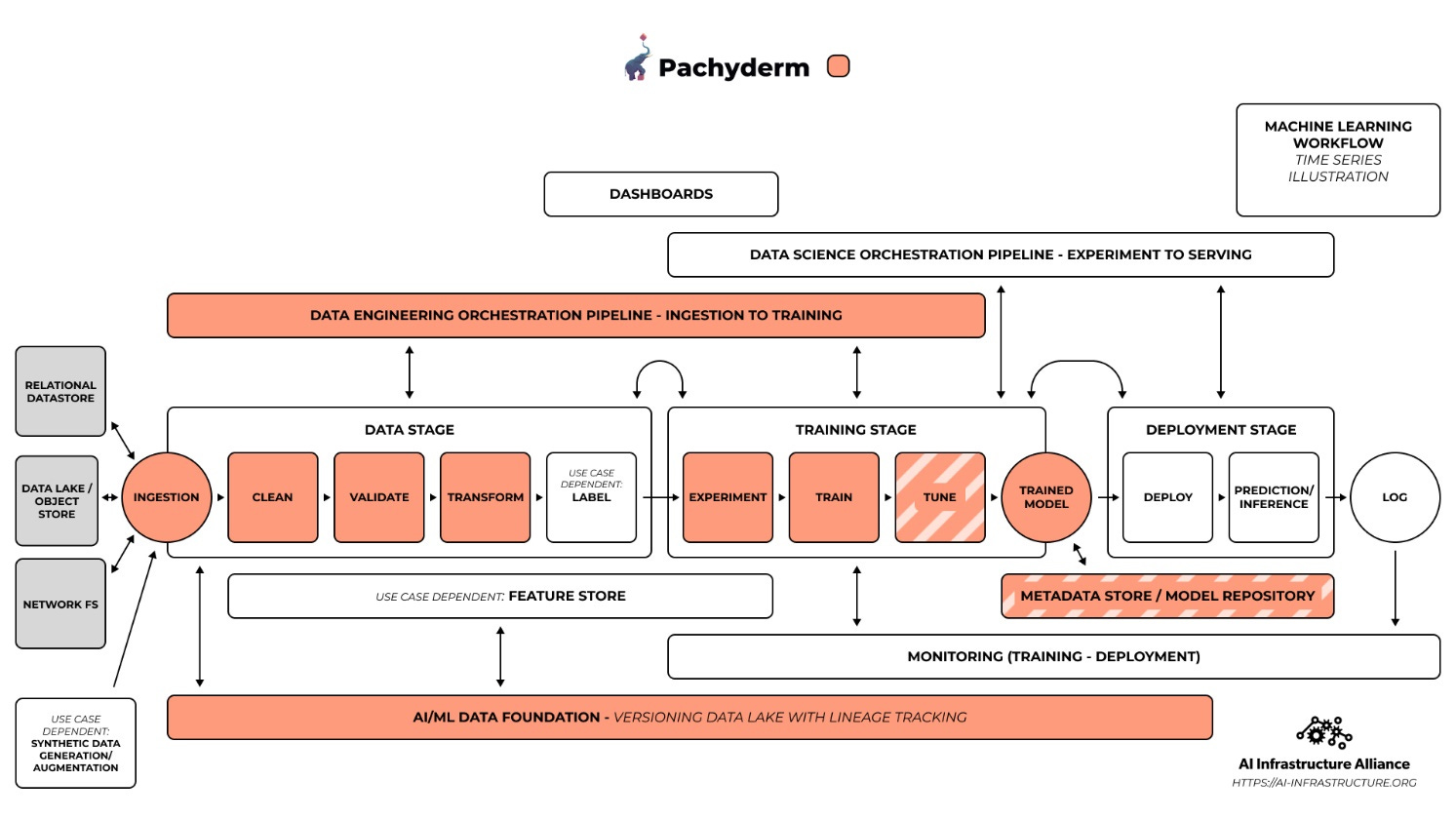
Pachyderm 2: Community and Enterprise Editions
Pachyderm 2 brings an array of new features, like Global Identifiers, Jupyter notebook support, a dynamic new web console, as well as data versioning and pipeline speed improvements. The team also worked hard to deal with technical debt, rewriting the storage layer to improve everything from the speed of the pipelines, to small file performance, to deduplication.
New Storage Architecture
Pachyderm 2’s new storage architecture splits files into 64-byte partitions, which are deduplicated across all files. That means files take up a lot less space, and it’s one of the reasons Pachyderm gives Hub 2 users pricing that doesn’t charge for storage. File commits are based on these precomputed FileSets, which drastically improve processing performance. Among other benefits, FileSets allow seeing commits before they are closed and limit the number of unnecessary merges.
Global Identifiers
Data lineage has been one of the core capabilities of the Pachyderm platform since its early versions. However, some data lineage scenarios are still quite complex to solve at scale. The classic example was tracking datasets lineage across different ML pipelines. In Pachyderm 1, this process required reconciling different identifiers, such as jobID or commitID, which could vary in different ML pipelines.
Pachyderm 2 introduces the concept of global identifiers that uniquely identify all commits and jobs related to a transaction. On the surface, global identifiers (global IDs) might seem like a simple feature, but it results in major improvements in model debugging and data lineage analysis.
Most lineage systems are nothing but a database. But when data scientists try to query that database to make heads or tails of what that lineage hash means, it’s always a struggle because they can’t easily relate that ID to what actually happened. What code changed? When? What version of the dataset did it use? What job did it run under? How is it all tied together?
A unified global ID makes it easy to pull all that information together with a single query.

Pachyderm Console
Pachyderm 2 includes a new web user interface to access tracking information in ML pipelines and manage their configuration. This web console is a fairly notable upgrade with the traditional dashboard interface included in Pachyderm 1. The original Pachyderm 1 interface was relatively simple, but most teams spent a lot of their time on the Pachyderm command line. The new interface helps data scientists and data engineers visualize complex DAGs easily, view jobs and projects, giving them a dashboard worth spending time in.

Other improvements
There are many improvements in Pachyderm 2 focused on core architecture capabilities that might not be visible to data science teams. For instance, Pachyderm 2 incorporates an upgraded spout streaming data architecture that removes some of the limitations of the previous version for large-scale ML pipelines. Similarly, there are new options for scaling a Pachyderm cluster as well as for deploying ML models.
Pachyderm 2 lays out a path for simpler and more scalable data versioning capabilities in ML pipelines. Nowhere is this more visible than in the new version of the Pachyderm Hub.
Pachyderm Hub 2
Managing an MLOps infrastructure is a complex task regardless of the technology stack. Many enterprises now turn to managed service offerings to abstract away that complexity so they can get right to work rather than spend cycles managing it. Pachyderm Hub 2 is the native cloud offering of the platform that gives data scientists a robust data foundation for their ML pipelines without having to deploy and manage a new infrastructure. Pachyderm Hub 2 provides all of the capabilities of the Pachyderm 2, such as data lineage or versioning as cloud-first services.
From an architecture standpoint, Pachyderm Hub 2 leverages the new storage architecture (a highly scalable engine for storing and versioning datasets in ML solutions) and Global IDs. Hub 2 also iterates faster than the enterprise version, which lets Pachyderm roll out new features, like Pachyderm notebooks, at an accelerated pace. For example, it brings the familiar Jupyter notebook experience for data science prototyping into the platform. That lets data scientists rapidly build ML experiments that natively leverage Pachyderm’s data-model versioning and management capabilities.

Conclusion
Pachyderm 2 represents a major release both in terms of infrastructure and functional capabilities. A new storage model with improved speed, small file performance, and deduplication, along with enhanced data lineage features, like Global IDs, makes Pachyderm an increasingly robust data foundation for advanced ML pipelines. The new management console experience and Pachyderm notebooks give data scientists and data engineers new ways to connect with the system, troubleshoot problems and experiment with their code. The new Pachyderm capabilities are available on the Enterprise, Community, and Hub editions of the platform: https://www.pachyderm.com/platform/